This article is more than 1 year old
The lowdown on storage and data protection
Backup to tape, disk and beyond
Deep dive El Reg has teamed up with the Storage Networking Industry Association (SNIA) for a series of deep dive articles. Each month, the SNIA will deliver a comprehensive introduction to basic storage networking concepts. The first article explores data protection.
Part1: Fundamental Concepts in Data Protection
Data protection is about making data available when something is going wrong.
There is no business continuity without data availability. Data is a valuable yet vulnerable asset; it can be accidentally compromised or destroyed by viruses, a wrong patch or administrative errors. In addition human error can contribute to data loss (for example deletion of the wrong file), and also software can misbehave. Whenever this occurs you need an uncorrupted, clean copy to restore. This process is called recovery and data protection is bout making such a copy and the process of retrieving it.
Recovery is so much more than just restore
As data protection revolves much more around recovery than back up, it is worth looking at the recovery process, and in particular at its five phases.
Detection First of all, we need to be aware of the issue by detecting it. If you just deleted a file or a directory the loss will be obvious but if your data has been corrupted by a virus for example, quite some time can pass before you notice and then you need to find out when the virus struck and what data has been affected. This leads us to phase two, the diagnosis.
Diagnosis The key point at this stage is to understand to what point in time you need to go back to retrieve the correct copy of the data, when it was still consistent and error-free. This is when you will also have to decide if you just need to recovery single files or a full back up. This will depend on your backup strategy and policies.
Restoration Now we come to phase three, the restoration of the compromised data, often mistaken for the complete process of recovery. This is the step where you physically copy (old) data to your production system. Depending on the accident before you can resume normal operations you might need to restart all your applications, replay logs from a database, or replay from a journal for a file system. This ensures that the amount of data you lose is kept to the bare minimum possible.
Test and Verification All the steps outlined above are going to be pointless if an error has occurred and you cannot recover or use the data you need. As a result the final stage is to test and verify that your data recovery was successful. It is only once this stage has been successfully completed that the data recovery process can be signed off.
RPO and RTO?
Whenever there is an incident that corrupts data, you typically will have a backup with non- corrupted data. Let’s call this the “last known good image”. If your most recent backup of uncorrupted data took place, say, last night, and today at lunch time your data was corrupted, your recovery point objective or RPO is last night and you would potentially lose half a day’s work or, in other words, any changes you have made to your data since your last backup of clean data.
Can you live with losing half a day’s work? This will probably depend on what data was affected. In some cases you might only want to lose the last ten minutes of data (an RPO of just a few minutes would however be considered quite aggressive for most scenarios).
The recovery time objective or RTO is how fast your applications come back, based on your last backup of a good image. As discussed above this period of time is not just the duration of the data restore from the backup but also that of all the phases of the recovery process.
Although the restore can be made quicker by using disk instead of tape or by using snapshots for example, restore is only one element of the recovery process and that is why an RTO of zero is science fiction.
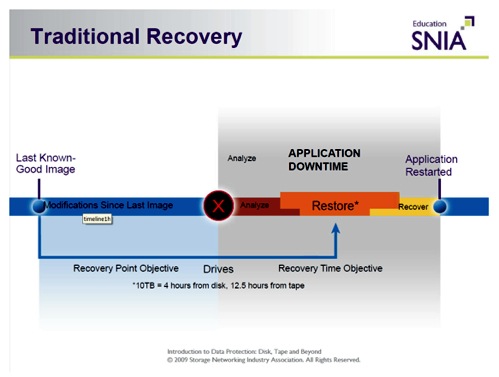
Slide from SNIA Tutorial: Introduction to Data Protection, Disk, Tape and Beyond: http://www.snia.org/education/tutorials/2010/fall
Minimising RTO and RPO
When you look at how critical some services, applications, and data are to your organisation you realise how important it is to minimise data loss i.e. to move your RTO and RPO as close to zero as possible.
With RTOs we have seen how the fresher the last ‘good’ backup (in other words, the shorter your RPO), the less time a log-based recovery will take. However the actual recovery point will rarely be just before the incident because not every point is suitable to recover from.
When we talk about application data e.g. an Oracle database for an SAP application, we need to be sure that we have consistent data. For instance: if we restore from a point in the middle of a transaction we might get into big trouble. Therefore, for backup applications you will need to first ensure the consistency of data and then backup. Obviously this reduces the number of points in time that are available for a restore.
As a rule of thumb, the higher the frequency of backups the higher your chances to have a workable RPO. The other side of the coin however is that the more often you backup the more expensive your data protection strategy will be. But the good news is that frequent backups are not necessary or beneficial. There are only a limited number of points in time that are really relevant.
If we look at the causes of data corruption many of them do not come as that much of a surprise and can be avoided. For example if you want to install a patch, make a back up before you do so; if the patch or upgrade fails, you have a working point of recovery. Let’s call such points of recovery, significant or relevant points in time and it is really helpful to be able to capture all these points. And there are certainly more of them than just one every evening.
Creating consistent backups of applications
The easiest way to create a reliable, consistent backup of an application is to shut the application down and then backup its data. The shutdown will create a consistent state. On the other hand it will result in downtime which today is unacceptable.
Another option is given by applications that support backups and allow you to put sets of data in a consistent mode before backing them up while the application is still running.
The third way is to generate a snapshot at a moment in time when data is consistent then backup from this snapshot while the application continues to run and change the original data. This is the path chosen today for very demanding applications.
Data protection strategies trade offs
There are numerous backup and recovery technologies currently available on the market and all of them have their price tag. Before you can decide you need to define your requirements. Not all data is the same; is every application service equally important to your company? You also need to differentiate between file services, email systems, databases and how quickly these must be available after an incident. How much data could you afford to lose? And how much you are ready to invest?
However, data protection is not just about RPO and RTO; the safety of your backed up copies is just as important. Would they survive a disaster? Depending on the criticality of your data you might wish to create multiple copies of your back up, on different types of media, and store them in separate locations.
The more copies you have and the further apart they are away from each other, the more secure your data is. But having several copies and moving them off site costs money. Some companies put data on tapes and store these in mines, sometimes deep in the Swiss Alps so they might survive a nuclear blast. Not every organisation needs this level of data protection, though.
To work out how much to spend on your data protection strategy ask yourself how much would data loss cost your organisation; at what stage would the unavailability of critical services and applications cost more than said strategy? How long could your organisation go without access to data?
Putting in place an infrastructure to protect information is like buying an insurance policy: you need to understand the impact of the incident to determine the price you are ready to pay to overcome this incident.
Bootnote
This article was written by Marcus Schneider, SNIA Europe Board member, and Director of Product Marketing at Fujitsu for Storage Solutions.
Part 2: Overview of a backup infrastructure will discuss how a backup infrastructure is put in place and operated.
For more information on this topic, visit: www.snia.organd www.snia-europe.org. To download the tutorial and see other tutorials on this subject, please visit: www.snia.org/education/tutorials/2010/fall
About the SNIA
The Storage Networking Industry Association (SNIA) is a not-for-profit global organisation, made up of some 400 member companies spanning virtually the entire storage industry. SNIA's mission is to lead the storage industry worldwide in developing and promoting standards, technologies, and educational services to empower organisations in the management of information. To this end, the SNIA is uniquely committed to delivering standards, education, and services that will propel open storage networking solutions into the broader market. About SNIA Europe SNIA Europe educates the market on the evolution and application of storage infrastructure solutions for the data centre through education, knowledge exchange and industry thought leadership. As a Regional Affiliate of SNIA Worldwide, we represent storage product and solutions manufacturers and the channel community across EMEA.
