This article is more than 1 year old
Deduplication’s Role in Disaster Recovery
The SNIA speaks
Deep dive El Reg has teamed up with the Storage Networking Industry Association (SNIA) for a series of deep dive articles. Each month, the SNIA will deliver a comprehensive introduction to basic storage networking concepts. This month the SNIA examines how deduplication can help with disaster recovery arrangements.
Data deduplication is gaining popularity as a way of improving storage efficiency, especially with respect to backup, where it can eliminate the need to store copies of the same data time and again. However, the benefits of data deduplication go beyond backup.
This technology can in fact also lend itself to significantly enhancing the process of sending data offsite for Disaster Recovery (DR) purposes.
This article sets out to describe the data deduplication process together with the architectural choices it opens up, and ultimately how this can positively impact your business. It is based on the SNIA Tutorial of the same name located on the SNIA Europe website here.
Introducing terminology
Data Deduplication is the replacement of multiple copies of data – at variable levels of granularity – with references to a shared copy in order to save storage space and/or bandwidth.
Data Replication is continuously maintaining a secondary copy of data – possibly at a remote site – from a primary volume for the purposes of providing high availability and redundancy. Data replication is used for DR and business continuance, among other uses.
Disaster Recovery is the recovery of data, access to data and associated processing through a comprehensive process of setting up a redundant site (equipment and work space) with recovery of operational data to continue business operations after a loss of use of all or part of a data centre.
This involves not only an essential set of data, but also an essential set of all the hardware and software to continue processing of that data and business. Any DR may involve some amount of downtime.
About data deduplication
One of the fundamental principles of data deduplication is that it works best where repetitive data exists. This is normally most frequent within a traditional backup operation, where the same data is processed and stored day after day after day.
Normally, full system backup operations are performed weekly, with incremental operations interspersed at the end of each day. The data stored during these operations is likely to be very similar; studies in fact, show that up to 98 per cent of the data can remain unchanged in many cases.
Deduplication technology has opened up the benefits of data replication to the mass market.
Deduplication involves the identification and evaluation of data. This is a process where unique data and references to duplicate copies of redundant data are stored. The deduplication may happen ‘inline’, that is before any data is written to disk, or as a ‘post-process’ which stores data to disk first, then performs these steps to evaluate, store, and/or replicate the data as a secondary process.
Archive data and primary array data can also be deduplicated, with greater or lesser efficiency. In all cases, the rate of deduplication will depend upon the data change rates and the nature of duplication in the data set. We will come back to data change rates later in the discussion.
Deduplication technology has opened up the benefits of data replication to the mass market. Once seeded with original data, the off-site (target) device need only have the changed data transmitted from the local (source) device to maintain backup integrity. This in turn means that lower bandwidth links can be used to transmit the data at lower cost than previous replication solutions would allow.
Today’s data protection challenges
The key challenge for IT is the fact that, on average, corporate data is doubling every 18 months to two years. This impacts the whole cost envelope of managing the data, from capital expenditure to power and cooling, to IT resources; it can also hinder the ability of the IT manager to maintain and improve Service Level Agreements (SLAs) for business managers and functions within their organisation.
Data growth
Let’s look a little more closely at what we mean by data growth.
We all know anecdotally that private data is growing rapidly, with digital photography and HD imagery for film and TV, through the new social applications like Facebook, You Tube and Twitter. Anyone with teenage children knows how much social applications can clog up the hard disk on the home PC.
Eric Schmidt from Google remarked that “Every two days we create as much information as we did from the dawn of civilisation up to 2003”. Examples of this ‘big data’ include: CERN, generating over 40TB of new data every second during its experiments and DreamWorks, back in 2009 using 12PB of storage in the post-production of its movies.
In business we have the same increases but with vastly more significant implications. I’m sure many of us have seen an estimate that suggests every person in the western world consumes over 30GB of data a day, somewhere on our systems.
Massively constrained budgets
Budgets are shrinking in most companies, and we all being asked to do more with less.
The whole IT environment is under significant pressure to maximise CAPEX and OPEX, including energy usage around power and cooling and the need for green efficiencies. Today’s data protection solutions have to deliver a wide range of benefits to the guys I meet day in and day out, covering the spectrum from system failure to viruses, from operator error to natural disasters.
Yes, they are all different flavours of ‘data insurance’, but if the day comes when you lose a server, a SAN or even the whole building, then your investment has to kick in and prove its worth.
Increased regulation and security requirements
Other areas under scrutiny are compliance and regulatory requirements, both subject to corporate guidelines and government legislation such as the old Sarbanes Oxley (SOX2002). The impact on data protection is two-fold: firstly the need to comply with guidelines on where and how to protect data, and secondly the need to retain this data for longer periods of time.
How data deduplication helps to answer business challenges
Most of the benefits of deduplication revolve around the fact that the overall data storage footprint is significantly reduced. This in turn means that users can:
• Save money: on hardware acquisition as they won’t run out of disk space so quickly
• Save time and resources: IT staff is freed from tape handling and maintenance to work on other value-added activities
• Enhance SLAs: with more data kept on hand for longer, they can offer faster restore times
• Deliver remote office and DR solutions: deduplication in turn opens the door to efficient data replication that keeps both bandwidth and networking costs under control. Replication is then available to off-site data for DR, or for supporting the centralised backup of remote sites.
“Every two days we create as much information as we did from the dawn of civilisation up to 2003”.
There are some additional benefits in deploying data deduplication that may not initially come to mind:
Hands-free solutions: most data deduplication solutions are integrated with some sort of disk-based backup system; either a dedicated appliance, or a software application running on a generic disk array.
What this allows in most cases is a method of automating the backup operation, freeing up IT resources and enabling the systems to be used in places where IT resource may be scarce.
More dependable and reliable backup: automating the process can also reduce human error and probably the intrinsic costs associated with those remote processes.
Rapid restore: the other advantage of deduplication is that the data is actually still ‘online’, although it needs to be re-hydrated before use. This provides a more rapid access operation than trying to find the required data on a tape in a data store or in a remote office.
Remote office solutions: for these reasons and others, many organisations are now seriously looking at moving tape technology from their remote offices in order to manage it centrally from the datacentre (DC), thereby keeping data close to home and within a robust IT environment in the knowledge that the remote backup operations are now dependably automated to eliminate human intervention.
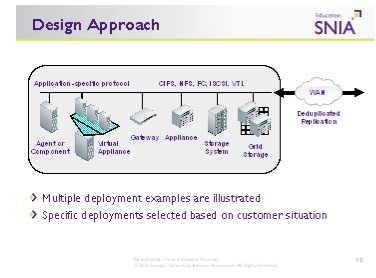
Deduplication ’flavours’ and deployment models
When considering deduplication, one of the first areas of discussion is where in the environment it should be deployed. There is a range of products and solutions to help users with this decision; the central question is ‘what issues are you trying to solve and where is the best implementation point to solve that issue?’
Today there are many different flavours and algorithms for deduplication in the market and most will not easily co-exist. Some of the more popular deduplication solutions include:
• Application-specific virtual appliances, agent-based or component-based solutions
• Gateway devices working above a generic storage platform
• Dedicated deduplication appliances
• As a component or feature within a larger storage or grid environment.
The majority of these platforms run a Virtual Tape Library (VTL) on NAS target (CIFS & NFS) data format on the systems to manage the access and file visualisation from the outside world. Systems are available with iSCSI and Fibre Channel interfaces to allow easy integration into most corporate IT environments. These solutions can also be linked to a WAN accelerator or optimisation appliance that may also speed up the replication process independently.
Data deduplication solutions may be deployed as ‘remote islands’ of storage (either in a remote office or at a larger head office DC, or more commonly in a more elaborate arrangement that performs local backup with deduplication followed by replication between two or more sites. There are also many different deployment models for the replication operation:
• The simple single direction replications: from source to target, usually from remote office to DC, or maybe DC to DR site; or of course from multiple remote sites to a central DC Site.
• Then there are ‘dual–routings’: either bi-directional on the same link from DC 1 to DC 2, and DC2 to DC1, each acting as the DR site for the other;
• A rotational scheme where DC 1 replicates to DC2 which is replicating to DC3 and DC3 is replicating back round to DC1.
• Multi-hop models: which have the same data being transferred from Remote Office to DC and then on to the DR site.
With all of these schemes there may be an impact to replication licensing cost and this should be worked into the cost envelope.
No matter what deployment option, if we are replicating between sites, we do need to make sure we have the same technology at both ends of the operation. So what are the 'gotchas' or trade-offs organisations should be thinking about and gaining advice on?
• Performance: depending upon the method of reduplication, data ingest performance may be lower than a normal data movement. This is down to the fact that the deduplication operation itself takes time and processor bandwidth; this however is data type and format dependant. In reverse, when restoring data, a re-hydration operation will be needed to allow a full restoration of the original data, so these parameters should be taken into account.
• Scalability: should be discussed and planned; what is the data growth pattern for that part of the environment? When thinking about the required capacity, if possible, users should estimate their likely data change rate (the amount of data that changes over the period of their backup cycles). The other point to remember is that not all files deduplicate at the same rate, so backing up databases and unstructured office data will give a different dedupe ratio than backing up movie or TV file formats.
• Encryption: any form of encryption will significantly affect any deduplication process, because encryption by its nature will randomise any similar data streams and all deduplication algorithms are looking for repetitive streams of data.
If we are replicating between sites, we do need to make sure we have the same technology at both ends of the operation.
In Summary
When planning any data protection strategy it is important to start by focusing on business needs. Data deduplication solutions exist to support the business SLAs that must be delivered. Users should start by considering:
• What is the backup and replication window I need to provide for?
• What are the restore and system downtime expectations of the business?
• What are the regulatory implications around different data types used for the applications in my organisation?
• What are the different elements of data I have to protect – how much redundancy is there likely to be between one backup and another, how much does my data change?
• How will the solution you have chosen fit into my current environment?
• Will it scale with my data growth needs and the overall performance I will need today and in the next few years?
• Finally how does the total cost work with my budgetary constraints on CAPEX and OPEX?
Data deduplication is not a panacea for all data protection ills; it still needs to fit within an overall data protection strategy that covers all aspects of risk. However, used properly, data deduplication can dramatically reduce storage inefficiency, enhance manageability and cut costs. It can also open the door to cost-effective data replication solutions to off-site data for DR or to centralise the backup of multiple remote offices.
Bootnote
This article was written by Chris Sopp, SNIA Europe Board of Directors, HP Enterprise Storage, Servers and Networking. For more information on this topic, visit: www.snia.org and www.snia-europe.org. To download the tutorial and see other tutorials on this subject, please visit: www.snia.org/education/tutorials/2010/fall
About the SNIA
The Storage Networking Industry Association (SNIA) is a not-for-profit global organisation, made up of some 400 member companies spanning virtually the entire storage industry. SNIA's mission is to lead the storage industry worldwide in developing and promoting standards, technologies, and educational services to empower organisations in the management of information. To this end, the SNIA is uniquely committed to delivering standards, education, and services that will propel open storage networking solutions into the broader market.
About SNIA Europe
SNIA Europe educates the market on the evolution and application of storage infrastructure solutions for the data centre through education, knowledge exchange and industry thought leadership. As a Regional Affiliate of SNIA Worldwide, we represent storage product and solutions manufacturers and the channel community across EMEA.
