This article is more than 1 year old
Can network architectures break the speed limit?
Bandwidth is never enough
How much bandwidth is enough? The answer is almost always: how much do you have and what will it cost?
The two major networking architectures in the world, InfiniBand and Ethernet, have been struggling to keep up with the bandwidth demands of corporate data centres and service providers, which want increasingly wide networks with lower latency links.
The proliferation of faster wireless networks and online applications, both for business and consumers, and the increasing use of data-heavy media such as video are putting strains on networks and everyone is clamouring for more speed.
Tall order
The problem is that it is getting harder and harder to make the leaps, as much for economic as for technical reasons.
John D'Ambrosia is chief Ethernet evangelist at Force10 Networks (now part of server maker Dell) as well as chairman of the Ethernet Alliance, a vendor-driven trade group. He says he was a bit nervous when he chaired the IEEE P802.3ba Task Force, which developed the standard for 40Gb/sec and 100Gb/sec Ethernet.
The reason was that Ethernet always made tenfold leaps in bandwidth performance as each successive generation came to market, but the needs at the network aggregation layer and at the server layer were drifting. Some users could not wait for 100Gb/sec.
"Up until then, 10X leaps, that was what Ethernet did," explains D'Ambrosia. "But it became very clear that it was going to be 40Gb/sec or 100Gb/sec or a very big problem."
Back in 2007, when the Ethernet specs were being hammered out, it looked like server makers might need 40Gb/sec Ethernet in 2014 and possibly 100Gb/sec Ethernet in 2017 or so, based on current trends.
"Servers are driven mainly by Moore's law, and they are not on the bleeding edge," says D'Ambrosia.
"But the situation is different for systems and for network aggregation. It is dynamic and changing and bandwidth needs are growing very quickly. In fact, right now the models we use to predict bandwidth needs are being challenged."
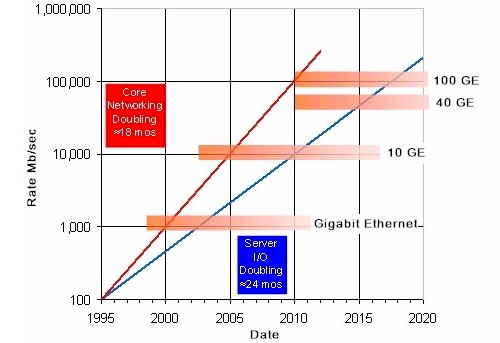
It is not that Ethernet is being pulled in two different directions: server needs and network needs. It is that both are being pulled upwards at different rates.
Mind the gap
As you can see from the Ethernet roadmap above, core networking bandwidth needs are doubling every 18 months, while server bandwidth needs are doubling every 24 months. The gap between the two is widening all the time.
One service provider has told D'Ambrosia that that it will need 1Tb/sec speeds by 2015, and search engine giant Google has said it would be really useful in 2013.
That's a pretty big jump – one requiring 40 lanes of traffic, the most by far ever attempted in an Ethernet switch chip. This at a time when 100GE is not even ramped up yet.
"100GE is a lot more expensive than people want to pay," says D'Ambrosia, adding that the industry needs to drive port counts up to drive per-port costs down.
Too little too late
Others in the Ethernet Alliance are saying that 400GE can be done with some clever tweaks, while still others think that by 2018, when the US Defense Advanced Research Projects Agency wants to have exascale supercomputers in the field, 400GE will be too late to market.
"It's quite scary," says Ambrosia. "The big debate now is speed requirements versus technical feasibility."
So what is next for Ethernet, aside from the obvious rollout of 10GE ports on servers beginning later this year and the uptake of 10GE, 40GE, and 100GE switching further in top-of-rack and end-of-row switches?
D'Ambrosia says that for one thing, everyone is braced to support 25Gb/sec signaling – and that includes both Ethernet and InfiniBand switch makers. (One chip from Mellanox Technologies, the SwitchX ASIC, is being designed to eventually support both protocols.)
"You never bet against Ethernet because the industry never bets against Ethernet"
And that raises an interesting point. Ethernet, InfiniBand, and Fibre Channel are borrowing ideas and technology from each other, and that will ultimately help Ethernet evolve.
"You never bet against Ethernet because the industry never bets against Ethernet," says D'Ambrosia. "The market wants Ethernet to succeed and evolve."
The same can be said for the companies that make parallel systems based on the InfiniBand alternative to Ethernet to run supercomputing applications, data warehousing and online transaction processing engines, and other kinds of clusters.
Ahead by a nose
InfiniBand has to work harder than Ethernet to justify its existence, and thus far, it has done a remarkable job of staying ahead.
"You're going to see higher speeds and lower latency for InfiniBand," says Brian Sparks, senior director of marketing at Mellanox and co-chair of the InfiniBand Trade Association's marketing working group.
Even as Ethernet borgs technologies from InfiniBand to improve the reliability and speed of communication – Remote Direct Memory Access over Converged Ethernet (RoCE), is a key one – InfiniBand has its advantages.
Sparks says that RoCE has a 33 per cent overhead running atop Ethernet compared with using Remote Direct Memory Access on InfiniBand.
"For those who need the lowest latency, that's a big deal," says Sparks.
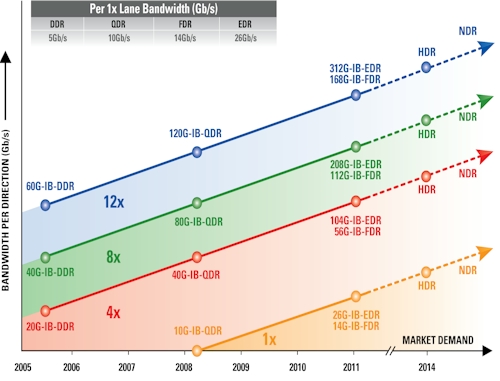
It is hard to believe, but 10Gb/sec InfiniBand came out a decade ago, and Ethernet is really just beginning its 10GE build out today.
In the fast lane
InfiniBand is a multi-lane protocol, and in general, the four-lane (4x) products shown in the roadmap above are used to link servers to switches, the eight-lane (8x) products are used for switch uplinks, and the 12-lane (12x) products are used for switch-to-switch links.
The single-lane (1x) products are intended to run the InfiniBand protocol over wide area networks. The original InfiniBand protocol ran each lane at 2.5Gb/sec. Double data rate pushed it up to 5Gb/sec, quad data rate (QDR) went higher to 10Gb/sec per lane, and the current fourteen data rate (FDR) pushes it up to 14Gb/sec per lane.
With FDR InfiniBand, the data encoding scheme was switched from to the 8b/10b encoding used in prior InfiniBand protocols to 64/66. This drops the overhead for the protocol from 25 per cent to 3 per cent, leaving more of the bandwidth (56Gb/sec for a top-of-rack InfiniBand switch) available for workload data.
With eight data rate (EDR) InfiniBand, the lane speed is going up to 25Gb/sec. The initial EDR products were expected around the end of 2012, but Sparks says that they have shifted out to early 2013.
Beyond that, there is the hexidecimal data rate (HDR) kicker and then next data rate (NDR). If history is any guide, then HDR will have 50Gb/sec lanes and NDR will have 100Gb/sec lanes – but that assumes the ASICs can be developed to support such speeds.
Stuck in the middle
Neither Mellanox nor QLogic, the other InfiniBand switch chip maker, is saying boo about what the future lane speeds might be, and neither is the InfiniBand Trade Association.
The other big problem, of course, is the PCI-Express bus. We are stuck at PCI-Express 2.0 right now, with PCI-Express 3.0 expected later this year.
PCI Express 3.0 will be able to handle 8GT/sec of bandwidth and is also ditching 8b/10b encoding for an even more efficient 128b/130b scheme to improve efficiency.
That means PCI-Express 3.0 buses will have twice the bandwidth of the previous generation.
At the moment, the PCI-Express buses are choking with InfiniBand QDR and FDR and the Ethernet 10GE and 40GE speeds, so there isn't much point in moving faster as far as servers are concerned.
The PCI-SIG that controls the bus standard used on PCs and servers needs to start better aligning PCI-Express 4.0 and 5.0 buses with the Ethernet and InfiniBand roadmaps and picking up the pace. ®
