This article is more than 1 year old
Is Auto-tiering storage really as good as it sounds?
Imperfect optimisations
Storage arrays are getting so good at managing data that they can now move it between different types of drives in the array so you don't store low-value data on expensive drives. Is it really as easy as this?
Let's suppose that you yourself are running this part of a hypothetical block-access drive array's operation. You can see what blocks are passing through what ports on the array, but that is it. You don't know what is at the server end of the links to those ports and don't know if the disk blocks flying back and forth are part of an Oracle database, PowerPoint deck, Word document or seismic data record.
You have four basic storage tiers at your disposal: ones made from one hundred 7,200rpm 2TB SATA disk drives (200TB), forty 10,000rpm 800GB SAS drives (32TB), twenty 15,000rpm 400GB Fibre Channel drives (8TB) , and five 200GB solid state drives (1TB total).
That's 241TB of storage in total and you know that tier 1, the SSD storage, has the most expensive drives, tier 2 Fibre Channel drives the next, with the tier 3 SAS drives being cheaper still, and the SATA drives being the least expensive. Data is stored in LUNs and LUNs are associated with ports. Your job is to match data value and storage tier. How are you going to do it?
Before we answer that we'll rule out fancy tiering schemes such as ones with protection built in, such as a tier with mirrored data and a tier with RAID 6 data, protecting against two drive failures. This just makes life even more complicated and we'll rule it out.
Judging data's value
How do you judge the value of the data you see travelling in and out of the array? Some schemes let users tell you via a management facility; "Keep these blocks in SSD and these in SATA." Easy-peasy for that but you still have to deal with the rest. Let's say that data starts off by default in the SATA tier if it is completely new but stays in the tier which a port is using otherwise.
For example, if data is being read out from the SAS tier on port number six, and then data comes in to be written through that port, then it goes to the SAS tier too.
Okay, that's a starting position. Now, you judge the value of data by the only statistic you directly measure; the number of I/Os to and from a LUN. If LUN number 20 in the SATA tier is getting more I/Os per second (IOPS) than LUNs in the next tier up, the SAS tier, then move a LUN from the SAS tier down to the SATA tier and your most active SATA LUN up into the SAS tier.

EMC's FAST tiering scheme
You are moving a whole LUN at a time and the number of decisions you make is quite limited, but, hold on, how long do you measure activity for before deciding to move a LUN? A second, a minute, five minutes, thirty minutes? The longer you defer the decision the more time an active LUN can be being accessed at a slow rate and inactive LUNs, meaning lower value data, taking up space in an expensive storage tier.
Other things being equal you want to minimise the amount of data movement inside the array yet maximise the responsiveness of the array when a LUN is active. So you optimise both by settling on a mid-point; say two minute checks.
Okay. Now let's have a 2TB LUN which gets a high degree of activity, higher than anything else in the array. It needs to go in the flash storage tier - but it can't; there is only 1TB of space there. Also, in that 2TB LUN you see that there is a hive of activity around some blocks but none around others. It may be that 10 per cent of the LUN is actually active, meaning 200GB, which would fit in the flash storage tier. So now you need to tier at the sub-LUN level.
That means the array software must be able to have a LUN occupy multiple storage tiers yet still be treated as a single storage pool for the port to which it is assigned.
Chunk granularity
How large should your chunks of data be? It's now a case of not over-doing the number of data moves, because there will be more of them as you are tracking sub-LUN-level activity, against the responsiveness of the array and the tiering resources at your disposal.
Other things being equal, the smaller the chunk size, the more granular your tracking, the more precisely you can tier the data but the more tracking you have to do. It's easier to track 20 LUNs than 4,000 sub-LUN chunks. What do the storage array suppliers do?
Dell EqualLogic tiers at the 15MB page level and, in an interesting twist, only does it between EqualLogic arrays in a group, not within each array, not unless the array has mixed SSD and disk drive enclosures, a unique case.
Dell Compellent arrays tiers at a 512KB page level but has now moved to 32KB pages. HP's EVA tiers at the LUN level. IBM's DS8000 uses 1GB chunks or extents as it calls them in its EasyTier feature. The Storwize V7000 also uses 1GB extents. IBM's XIV has no tiering at all, having only one drive type.
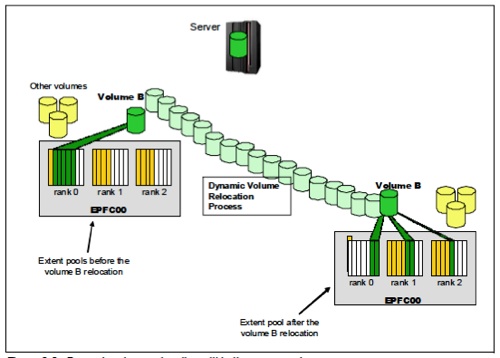
IBM's EasyTier showing Dynamic volume relocation within the same pool
Tracking frequency
The more frequently you track the chunk activity levels the better you can ensure that higher value data goes into the equivalent value tier, but you don't want to be too reactive because then you will spend too much time moving data inside the array and less time reading and writing data using the same internal array links to do so. THe smaller the chunk, the more reactive you can afford to be, because less data is being moved at a time.
If you know that data is being read sequentially then tiering doesn't matter so much. It matters most when data access is relatively random and you need to push it up tiers fast as its activity rises and return it to lower tiers as the activity level falls away.
Tiering will work adequately, to say the least, when the array has sufficient resources and internal bandwidth to track small chunks and move them after relatively short periods of raised activity. There is no perfect automated tiering scheme based just on array-level considerations.
It's always a case of optimising as best you can between competing considerations. If accessing servers could give the storage resource more information about I/O patterns and applications, such as a VDI boot storm about to happen, then the array could pre-load golden master VDI files in flash, and respond very much better.
That sort of better interaction between hypervisors and storage resources is surely coming down the pike and tiering will work much better as a result. ®
