This article is more than 1 year old
Hadoop: Making Linux gobble big data
Growing penguins need petabytes to feast on
Hadoop World The Hadoop big data muncher has grown into more than Yahoo! conceived when it open-sourced its search engine indexing tool and its underlying file system back in 2009. And it has become exactly what open-source projects aspire to be: a centre of gravity around which a maelstrom of innovation coalesces.
At the Hadoop World conference in New York hosted by Cloudera, the company's top brass and techies rallied some big-name advocates to talk about how they are using Hadoop in production and what the future holds for the data processing platform. (And yes, the Cloudera people are whippersnappers and they call it data processing, so what is old is new again.) Cloudera is one of several organizations that provides tech support for the Apache Hadoop stack as well as proprietary extensions to Hadoop – to make it better suited for companies to deploy alongside their traditional, database-driven back-end systems
Mike Olson, CEO at Cloudera, opened up his keynote by reminding everyone that "big data is more than size; it is complexity" and that "Hadoop is at the core of a data analytics platform, but you need more."
Among the 1,400 attendees at the two-day conference this week, 580 companies were represented, and Olson gathered up some interesting statistics that illuminate the issues actually facing Hadoop as it matures and becomes just another tool in the data centre. For one thing, big data is not all that big out there once you leave the Facebook, Google, Yahoo, eBay, and others out of the mix. Across those companies in attendance (and Facebook and eBay were there) the average cluster size is a mere 120 server nodes, up from 66 nodes a year ago at the Hadoop World 2010 event.
Of those companies in attendance, 44 per cent had Hadoop clusters with between 10 and 100 nodes, and 52 per cent had clusters between 100 and 1,000 nodes. The name node in a Hadoop cluster – roughly akin to a head node in a regular HPC cluster – starts choking at around 4,000 nodes, which is the scalability limit of Hadoop at the moment. Those 580 companies had a total of 202PB under management by Hadoop, a factor of 3.4 higher than last year. The node count didn't quite double, but the capacity more than tripled. The largest customer attending the event had 20PB under management of Hadoop, and 76 companies had between 100TB and 1PB and 74 companies had more than 1PB.
The remaining 4 per cent of the Hadoop customers in attendance are topping out their clusters in terms of node count. Earlier this year, executives at Yahoo! confirmed to El Reg that the company had 16 clusters running Hadoop with a total of 43,000 servers underpinning it, and the expectation was to have close to 60,000 nodes running Hadoop by the end of this year. Earlier this year, Yahoo! had over 200PB of data under Hadoop management all by itself. So it looks like Yahoo! data was not included in this poll data presented by Olson.
The point of rattling off those numbers, aside from being impressed with the girth and heft of all that iron, is to point out the obvious fact that big data is not really very big at all for most companies. At least not yet. Most companies don't yet know how to capture and use all of the unstructured data that could be mashed up with the operational data stored in their back-end systems. And they won't until the Hadoop stack becomes as polished and complete as a Linux distribution. And the indications are, at least from the roadmaps set out by the folks at Cloudera who are heavily involved in the development of Apache Hadoop, that we are pretty close to having an analog to Linux.
Maybe they should have called it Cuttix?
During the keynote sessions, Charles Zedlewski, vice president of products, and Eli Collins, senior engineer, walked down memory lane for Hadoop from its internal development at Yahoo! in 2006 and 2007 to open-source project in 2009 and then peered a little down a future lane to what might be coming down the pike on the back of an elephant.
Zedlewski got to start the history lesson, and talked about how the initial MapReduce algorithm and underlying Hadoop Distributed File System (HDFS) was "a great start, but also had fairly narrow use cases," mainly creating search engines and performing "click sessionization" (throwing custom data at you as you move around a website). At the time, all of the code that was contributed to the Hadoop project was related to the core HDFS and MapReduce.
The Hadoop stack next got a database (of sorts) and a set of high level programming languages that wrapped around the kernel. These include: HBase, the column-oriented distributed data store that rides on top of HDFS (and which arguably is not ready for primetime quite yet); Zookeeper, a configuration server for clusters that helps to make applications less brittle; and Mahout, a set of machine learning algorithms for taking what MapReduce tells apps about you others like you and making recommendations to you, among other things like automatic document classification. These projects, which were outside of the core Hadoop "kernel", represented 73 per cent of the code in the stack that year.
And even with a major upgrade to Hadoop with its open-sourcing in 2009, the addition of the Pig high-level data analytics language and the Hive data warehouse and SQL-like ad hoc query language, and the Avro file format, the core Hadoop kernel still only comprised 58 per cent of the code in 2009. By last year, the Hadoop kernel represented about 37 per cent of the total, with a slew of other independent projects wrapping around Hadoop to twist and extend it to new purposes.
Here's where the Hadoop distro stands today:
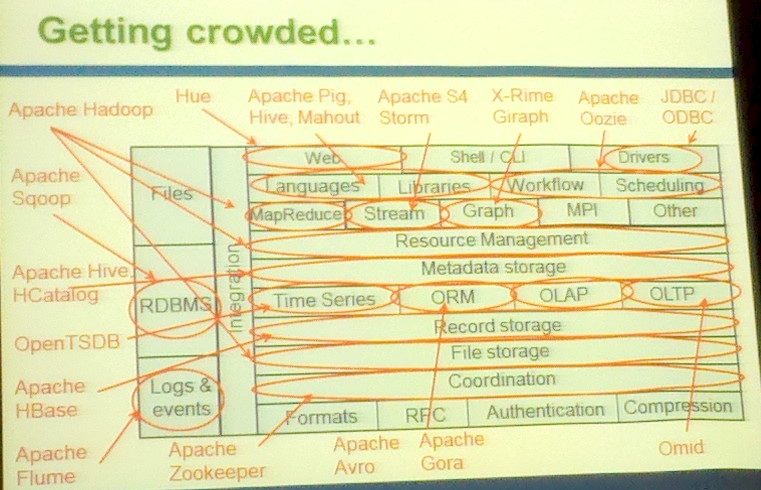
The modern Hadoop distribution (click to enlarge)
Now, said Zedlewski, there are a half-dozen alternative file systems for Hadoop and multiple compression algorithms, and new projects have sprung up to bet able to move data back and forth from Hadoop and relational database management systems, to stream log and event files right into Hadoop (Flume), and to also be able to absorb files of different formats right into Hadoop (Sqoop). And in addition to the original MapReduce computation, other methods of chewing on data are being added, including MPI, graph, and stream algorithms.
