This article is more than 1 year old
Proprietary interconnects blaze the networking trail
Ethernet and InfiniBand left behind
Given the great strides that Ethernet and InfiniBand networking have made in the past decade, you would think that there wasn't much room for proprietary interconnects linking together nodes in parallel supercomputers.
Oddly enough, despite the overwhelming popularity of these two increasingly similar networking technologies, new proprietary interconnects are on the rise. How can this be?
The answer is as old as the computer industry itself. Sometimes, to solve a specific problem it makes more sense to engineer a machine that solves that problem well.
All you need is a rich customer that can afford to pay for something that is not standard. Say a nuclear energy or other kind of research lab run by the US, Europe, China or Japan.
Top drawer
"At the high end of the market there is always going to be the opportunity for a proprietary interconnect that has more bandwidth or lower latency – or both – than InfiniBand or Ethernet, or whatever the standard du jour is," says Addison Snell, chief executive of Intersect 360 Research.
In the Top 500 list of supercomputers put out in June, there were 232 machines using Ethernet switches to lash together their server nodes, with only 11 sporting switches that spoke 10 Gigabit Ethernet.
There were 206 machines that used InfiniBand as an interconnect, and of these 69 were using quad data rate (QDR) 40Gbps protocols. While faster fourteen data rate (FDR) InfiniBand switches are now coming to market from Mellanox Technologies and QLogic, they had not ramped up in time for the June Top 500 list.
That left 62 machines, or 12.4 per cent of the systems on the list, using proprietary interconnects for number-crunching scalability.
At the top of the list is the K supercomputer built by Fujitsu for the Rikagaku Kenkyusho (Riken) research lab in Kobe, Japan. It uses a proprietary interconnect called Tofu that implements a 6D mesh/torus between the 17,136 Sparc64-based server nodes in the 8.77 petaflops machine.
Here's what it looks like, conceptually:
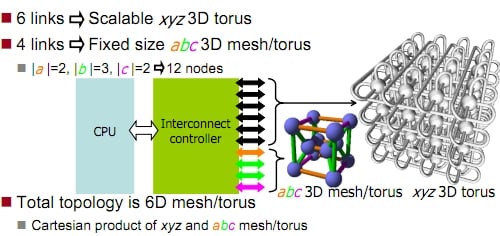
Fujitsu's Tofu interconnect for the K supercomputer
Each one of the eight-core Sparc64-VIIIfx processors in the machine has its own dedicated Tofu controller. The Tofu chip has ten links reaching out to the network, each with 10GBps (that's bytes, not bits) of bandwidth, for a total of 100GBps coming out of the Sparc64 chip.
The Tofu interconnect is actually a 3D torus linking local processing nodes (using four of the links on the interconnect chip) that has an overlay of a 3D mesh/torus on top of that (using the other six links).
Expensive choice
Meshing two 3D networks, Fujitsu says it can offer 12 times the scalability of a 3D torus. Multiple paths between nodes ensure the crash of a node will not affect processing.
The K supercomputer also originally had a $1.2bn price tag. Back then it was supposed to be a hybrid scalar-vector machine scaling to 10 petaflops and sporting Fujitsu Sparc64 scalar and NEC SX vector engines with help from Hitachi on the interconnect.
Riken has not said what the final price tag on this K supercomputer is, but it is clearly a lot more expensive than slapping together a cluster using X86 servers and InfiniBand switches.
Among the other interconnects that are prominent in the HPC space these days are:
Arch The Tianhe-1A super uses a proprietary interconnect called Arch, which was developed by the Chinese government.
The Arch switch links the server nodes together using optical-electric cables in a hybrid fat-tree configuration. It has a bi-directional bandwidth of 160Gbps, a latency for a node hop of 1.57 microseconds, and an aggregate bandwidth of more than 61Tbps. That's twice the bandwidth of QDR InfiniBand.
Extoll Russian supercomputer maker T-Platforms is working with the University of Heidelberg to create the Extoll interconnect. This puts six links on a network interface card that can in combination deliver 90GBps of bandwidth with what the vendor hopes will be sub-microsecond latency on a node-to-node hop.
Gemini and Aries Cray's XE6 Opteron-based massively parallel supercomputers use an interconnect called Gemini. It has two virtual network interface cards that plug into four Opteron processors on the XE6 server blades.
The core of the interconnect is a 48-port high radix Yarc router with adaptive routing, which allows four of the ports to be linked on the fly to create the virtual interface card to link to compute nodes.
These 48 ports have an aggregate bandwidth of 168GBps (again that is bytes, not bits) and can do a node-to-node jump in just a little more than a microsecond.
More importantly, the Gemini chip can process about two million messages per second, about 100 times more throughput than the prior SeaStar+ interconnect used in the Cray XE5 supers. Gemini uses a 3D torus interconnect.
For its future Cascade supers, Cray is cooking up a much higher bandwidth interconnect called Aries, which will plug into processors through PCI-Express 3.0 links (this being useful for any processor that supports it) instead of being restricted to Advanced Micro Devices' HyperTransport links.
Cray has not said much about Aries, but it will use a combination of electrical and optical signaling and offer about 10 per cent performance improvement over the current Gemini.
UltraViolet Silicon Graphics continues to push up the scalability of its NUMAlink shared memory interconnect as it ported the interconnect from Intel's Itanium processors to its high-end Xeon 7500 and now E7 processors.
The NUMAlink 5 rides atop Intel's Boxboro 7500 chipset and uses some of the ports to cross-couple 128 two-socket blade servers into a single shared memory system. NUMAlink 5 delivers 15GBps of interconnect bandwidth between the blades in the Altix UV cluster, and less than a microsecond of latency on those links.
BlueGene and Blue Waters IBM has been making supercomputer interconnects for decades, with the RS/6000 SP switch at the heart of its PowerParallel machines getting Big Blue into the game for real in the late 1990s.
The Federation switch is part of the US Department of Energy's ASCI programme, glueing together tons of standard AIX servers. And now it has the very high bandwidth interconnects used in the BlueGene/Q and Blue Waters parallel supers.
The BlueGene/Q puts the network processor and virtual network interface card right onto the same chip as the 18-core PowerPC processor that does the calculating in the system. This interconnect implements a 5D torus between the compute nodes, each having one of these processors. (One core is used for running the Linux kernel, one is a spare, and the other 16 are used for calculations.)
The BlueGene/Q interconnect has a total of 11 ports, each of which can send 2GBps of data bi-directionally, for a total of 44GBps of network bandwidth. A slice of this bandwidth is used to link to I/O nodes in the system, which hook to external disks and networks.
The BlueGene/Q machine has 46 times the bisectional bandwidth of the original BlueGene/L machine and is what allows IBM to scale this box up to 20 petaflops.
Although IBM has pulled the plug on the Blue Waters Power7-based machine at the National Center for Supercomputing Applications at the University of Illinois, the vendor is still selling the machine and, according to Snell, is just about ready to announce a buyer for the box. (Blue Waters was going to be more costly to build than either IBM or NCSA anticipated at the start of the project back in 2007.)
At the heart of the 16 petaflops Blue Waters system is a homegrown hub/switch interconnect that links 2,048 drawers of machines together. Each drawer has eight 32-core Power7 processor modules and eight hub/switch interconnect chips, which deliver a stunning 1,128GBps in aggregate bandwidth.
That is 192GBps of bandwidth into each Power7 four-chip multichip module (what IBM called a host connection), 336GBps of connectivity to the seven other local nodes on the drawer, 240GBps of bandwidth between the nodes in a four-drawer supernode, and 320GBps dedicated to linking supernodes to remote nodes. There is another 40GBps of general-purpose I/O bandwidth.
Eye on Ethernet
There are still other interconnects in use out there, and they might point to how some of the technology in the funky interconnects in petaflops-class supercomputers might make their way to commercial networking.
For example, Quadrics interconnects are still in operation, even though Quadrics shut down as it was trying to morph itself into a supplier of a pumped-up version of 10GE.
Myricom tried the same thing by taking some of the smarts in its own interconnect and layering it on top of 10GE, and is thus far still around.
So what about bringing the technology embodied in the Cray Gemini or future Aries interconnects or IBM Blue Waters interconnect, or any other interconnect for that matter, down into Ethernet?
"Getting it all the way down into Ethernet would certainly take a long time," says Snell. "Some of the protocol tricks will probably make it into Ethernet, but the fabric interconnect will not."
There is one other tack that might prove to be useful for general-purpose computing over the long run. Cray has a very interesting twist for its Gemini interconnect: running Ethernet on top of it and convincing Linux applications that they are speaking Ethernet.
This feature, called Cluster Compatibility Mode, is a part of Cray's Linux Environment 3.0, a hardened version of SUSE's Linux Enterprise Server 11. Eventually, Cray plans to support the OpenFabrics Enterprise Distribution drivers for InfiniBand in this Cluster Compatibility Mode.
Either way, applications compiled for normal Linux clusters using InfiniBand or Ethernet protocols can move over to Cray iron and run without having to be recompiled.
There is a performance penalty for such emulation, but that is just the way it is with computers. ®
