This article is more than 1 year old
Hot Intel teraflops MIC coprocessor action in a hotel
Sweet nothings whispered about Xeon E5 performance
SC11 Intel did not make any announcements of new processors or coprocessors at the SC11 supercomputing conference in Seattle, but it came about as close as it could without actually doing it.
Rajeeb Hazra, general manager of high performance computing at Intel, hosted a lunch briefing with journalists to show off two things. The first was that it has working silicon for the x86-based "Knights Corner" Many Independent Core (MIC) coprocessor that the chip giant will be pitching as an alternative to using GPU coprocessors in x86 clusters.
Secondly, Intel has ten machines on the Top 500 list using the forthcoming "Sandy Bridge-EP" Xeon E5 processors, and they have a performance advantage over the new "Interlagos" Opteron 6200 processors that were launched earlier this week.

Intel HPC GM Rajeeb Hazra holding a "Knights Corner" MIC coprocessor
While the "Knights Ferry" MIC coprocessor has been available in limited quantities as a software development platform, the "Knights Corner" chip is the real deal, the one that is intended to be put into production and used on a large scale inside of workstations, servers, and supercomputer clusters to boost the number-crunching performance of the systems substantially.
This is, of course, precisely what Nvidia and Advanced Micro Devices want you to do with their graphics processors, and ironically, that was Intel's original plans for the "Larrabee" project that led to MICs. Intel wanted to get into the discrete graphics card business using arrays of modified Pentium cores, and has instead decided to just pitch the many-cored chips as coprocessors that can run parallelized x64 code.
Intel has been showing off the MIC coprocessors for so long it is hard to remember that it is not yet a product. Two years ago at SC09, Justin Rattner, chief technology office at the chip maker, showed off an early version of the Knights Ferry chip with 32 cores that was able to deliver slightly over 1 teraflops of performance on the SGEMM single precision, dense matrix multiply benchmark test - after Intel turned on all the cores and then overclocked it for a short spike.
The original Knights Ferry chip had 32 superscalar cores (without out-of-order execution) and a 512-bit vector math unit that can do 16 floating point operations per clock with single precision. Double precision was not an option, which is the main reason Knights Ferry was not commercialized. Many HPC applications require it.
Intel has been cagey in public talking about how many cores are physically on the Knights Corner coprocessor, and has only committed to saying that it is going to be larger than 50. The real answer is that there are 64 cores on the die, and depending on yields and the clock speeds that Intel can push on the chip, it will activate somewhere between 50 and 64 of those cores and run them at 1.2GHz to 1.6GHz, based on various presentations that were making the rounds at this year's IDF back in September.
Intel is not committing to a clock speed or core count, to keep its options open on the new 22 nanometer processes it is using to make the Knights Corner MIC coprocessor. But there was no question that Intel wanted to hit 1 teraflops for double precision floating point math with the coprocessor, and more if it can squeeze it out, and El Reg has been saying that for quite some time. Intel will very likely hit 2 teraflops or more at single precision, but this doesn't matter except for a small subset of HPC applications, particularly in the life sciences, where double precision is not needed.
In a hotel room near the press conference today, Intel's engineers had taken one of the handful of Knights Corner MIC chips that had come out of the foundry in Hillsboro, Oregon, and plunked it onto a development PCI-Express board, plugged it into a two-socket caseless Xeon server. It then fired up this box and ran the DGEMM matrix math benchmark on it, pushing it up to over 1 teraflops at double precision.
Intel would not say how many cores were activated on this MIC chip, what clock speed it was running at, or how much GDDR5 graphics memory was on the card. Nor would it let pesky journos take pictures or ask questions. Hazra wouldn't even let El Reg hold one of the loose chips he had.
Once again, Intel would not talk about delivery dates for MIC coprocessor chips, which will be packaged onto PCI-Express processor slots, but the expectation is for them to come out in the second half of 2012. "We don't build chips and then sit on them for years," Hazra said when asked for a firmer date.
The key differentiator between the MIC chips and GPU coprocessors, explained Hazra, is that the compilers that HPC application programmers have been using to write multithreaded code on CPUs and parallelized code on clusters using the MPI protocol can be used to dispatch code to a MIC coprocessor.
"It eliminates code porting to a certain extent," said Hazra. "It just makes it an optimization job." The application source code builds with a compiler switch being flipped. "So it is programming as you have always done it, with results you have never experienced before."
Just to make sure we believe this is possible, Glenn Brook, of the Joint Institute of Computational Sciences, which spans Oak Ridge National Laboratory and the University of Tennessee, was trotted out to talk about the code porting he has been doing moving x86 cluster code to the Knights Ferry experimental MIC coprocessors. The software developers there have ported more than 5 million lines of Fortran, C, C++, and Python code to run on the MICs in under three months, including NWChem for chemistry, ENZO for astrophysics, ELK for materials science, MADNESS for applied math, and a few others. Most of it was Fortran code and most of the ports took less than a day each.
"Most of this code will never run on GPUs as we know them," Brook explained, saying that they do not have the kind of parallelism that a GPU coprocessor with many hundreds of cores requires and that the cost and complexity of porting to GPUs would be too much. This coming from a lab that has agreed to buy a 20 petaflops XK6 hybrid CPU-GPU machine. It really comes down to cases. And any new code can be implemented on a GPU from the getgo.
The thing that Intel has to do to compete with Nvidia is match or nearly match it on raw double precision performance and get the codes that can't move to GPUs so easily. In some cases, this will simply mean treating a MIC like a baby cluster, putting MPI on it and running code on each core as it it were a server node because this is the easiest way to port the code. You can't do that with a GPU coprocessor.
It is reasonable to assume that Intel will do everything in its power to contain the usefulness of the MIC and charge a premium for it. Hopefully it will give it more of a fair shake than Itanium got, and the exascale imperative pretty much means it will indeed let it live where it naturally can.
Still loving the CPU for HPC
Despite all this talk about the MIC coprocessors today, Intel is still very much in love with its CPUs and the vast business it has built peddling them. And everyone, of course, is waiting for Intel to formally announce the chips early in 2012. Hazra said that they were "within a month or two of introduction," and by that statement I took that to mean they would be here in the next 60 days, but Intel clarified and said that Hazra meant that they had been shipping quietly behind the scenes for the past two months and this was not an indication that the chips would officially ship in January or so. The official Xeon E5 launch date remains "early 2012."
Intel did not give out feeds and speeds for the new Xeon E5 line, but Hazra did provide some assessment of how the top-bin Xeon E5 part would stack up the current six-core Xeon X5690 processor running at 3.4GHz:
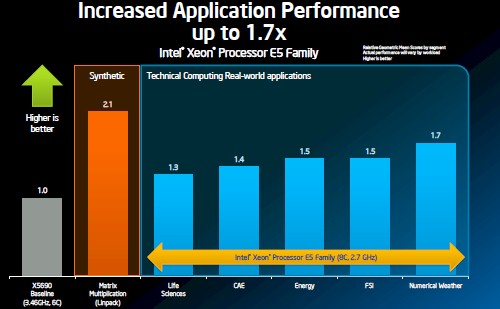
How the Xeon E5 rates against the Xeon X5690
Depending on the benchmark test, Intel is getting from 1.3 to 1.7 times the performance on HPC applications. But that is not the only test Intel has to pass. The Xeon E5s also have to compete against the 16-core Opteron 6200s from AMD. And rather than show actual benchmark test results, Hazra just pulled out the Linpack test results for a small cluster based on the Xeon E5s and using InfiniBand links (ranked number 105 on the November 2011 Top 500 list that came out earlier this week ) and pegged it against an Opteron 6200 machine that ranked number 20 on the list using a similar Infiniband interconnect. Here's how they stacked up on a per CPU basis:
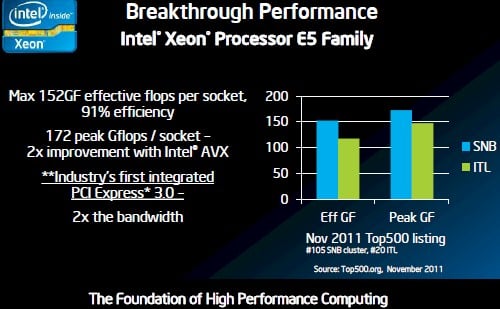
Linpack performance of Xeon E5 and Opteron 6200 processors
As expected, Intel is pretty hot to trot about the integration of PCI-Express 3.0 controllers on the Xeon E5 processors, which AMD has not done with the Opteron 6200s. In fact, not only does the Opteron chip not have PCI on the die, it only supports PCI-Express 2.0 links, which run at half the speed. "PCI Express 3.0 is a necessity for performance," said Hazra. "Anything else just doesn't make sense. It is like moving backwards. Using anything else would be a compromise. That's how we feel, and that's what out customers are telling us they feel."
AMD must be talking to different customers, then. ®
