This article is more than 1 year old
Peeking up the skirt of Microsoft's hardy ReFS
Getting under the skin of Windows 8's new server filesystem
As reported this past fortnight, Microsoft's new Storage Spaces for Windows 8 is only half the story; the operating system builder is also throwing in a new Resilient File System (ReFS) while retaining most NTFS features and semantics.
Storage Spaces is a Windows 8 feature that enables a PC user to aggregate physical disk drives into a storage pool from which virtual drives are carved out; these imaginary disks then benefit from self-healing data integrity features. Storage Spaces is aimed at client PCs using NTFS. ReFS is designed for servers, but will be adapted for clients so it can be ultimately used across both system classes.
ReFS, which was co-designed with Storage Spaces, is expected to cope with much greater scale than NTFS, and data is verified and auto-corrected using checksums, just like Storage Spaces. In fact it aims to be resilient end-to-end when used in conjunction with Storage Spaces.
The new filesystem, unveiled by Windows development boss Surendra Verma, will feature:
- Checksums to test the integrity of metadata - which are records describing each file such as the creation time and date.
- Optional data integrity checksums
- Allocate-on-write transactional model to avoid losing data during a crash
- Large volume, file and directory sizes
- Storage pooling and virtualisation
- Data striping for performance (bandwidth can be managed) and redundancy for fault tolerance
- Disk scrubbing for protection against latent disk errors
- Resiliency to corruptions
- Shared storage pools across machines for additional failure tolerance and load balancing
Software doesn't need to do anything special to use the new filesystem: the blog states "data stored on ReFS is accessible through the same file access APIs on clients that are used on any operating system that can access today’s NTFS volumes".
Let's have a look at ReFS scaling and integrity features:
ReFS scaling
ReFS uses B+ trees for juggling all on-disk structures including metadata and file data, implemented underneath the main NTFS upper-layer API and semantics engine. This provides the filesystem API compatibility with NTFS.
The B+ trees, which are also used in NTFS to organise its filesystem, in theory allow infinite scaling. We understand the maximum implemented NTFS file size is 16TB less 16KB although it could be 16 exabytes less 1KB. The Microsoft blog tells us that the maximum ReFS file size is one byte shy of 264 bytes - which is 16 exabytes.
The trees can be quite compact or very large and multi-level on disk. Common filesystem abstractions are built using tables to describe directories and "enumerable sets of key-value pairs" to define each file and where chunks of it are stored. The image below shows this:
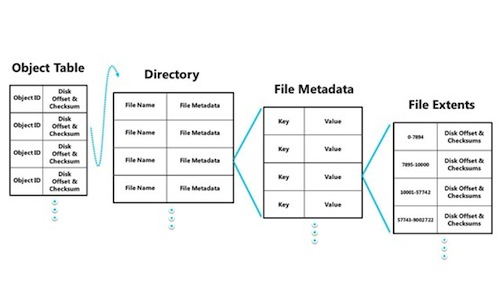
Click to enlarge Credit: MSDN
Microsoft states: "Directories can scale efficiently, becoming very large. Files are implemented as tables embedded within a row of the parent directory, itself a table (represented as file metadata in the diagram above). The rows within the file metadata table represent the various file attributes. The file data extent locations are represented by an embedded stream table, which is a table of offset mappings (and, optionally, checksums). This means that the files and directories can be very large without a performance impact, eclipsing the limitations found in NTFS."
Filesystem integrity
Free space is carved up by a hierarchical allocator that includes three separate tables for large, medium, and small chunks, enabling the disk allocation algorithms to scale efficiently. Updating the disk is not done with either the NTFS transaction journal approach or a log structure. Instead an allocate-on-write approach is used that never updates metadata in-place but writes it atomically to a different location to preserve disk contents correctly if a power failure happens when the structure is being updated.
Data, and data directories, can have an integrity attribute in which case updates are also carried out with an allocate-on-write approach. This is known as an integrity stream.
ReFS metadata is 64-bit checksummed at the B+ tree page level, and the check values are stored separately from the metadata. The blog says: "This allows us to detect all forms of disk corruption, including lost and misdirected writes and bit rot (degradation of data on the media). In addition, we have added an option where the contents of a file are checksummed as well."
If ReFS detects data corruption and is running on top of Storage Spaces it can automatically repair corruption by telling Storage Spaces to read all of its copies of that data, select the good one based on checksum validation, and use it to fix the bad copies. Where ReFS is not running on top of Storage Spaces it logs a corruption event.
Periodically ReFS reads all the metadata and integrity stream data in a volume in a mirrored Storage Space, and validates its correctness using checksums. Mismatched old and new checksums indicate bad data, and the bad data copies are fixed by using the good ones. This is known as scrubbing and combats bit rot.
Implementation
The read performance of ReFS is said to be similar to that of NTFS and Microsoft's blogger expects it to be good at streaming data.
ReFS does not offer deduplication, but deduplication products should work with it as they work with NTFS. It does not implement a second-level cache but third-party products can be used to provide it. It works with VSS to provide snapshots but doesn't, for now, support writable snapshots or snapshots larger than 64TB.
Read the blog entry for more information; the FAQ section is useful, and the comments to it are interesting too. ®
