This article is more than 1 year old
Cray gets graphic with big data
ThreadStorm appliance cries 'Urika!'
Supercomputer maker Cray has released an exotic appliance to help deep-pockets organizations find the relationships hidden in the torrent of information now being collected about, well, everything and everyone.
Sometimes you want to Map and Reduce that big data to sift it for some golden nuggets of information, and sometimes you want to take data about people or objects and see how they are connected to each other – or, better still, to see how they might be related, even though there is not a relationship expressed in your data.
For the former, you can set up a massive Hadoop cluster and munch the data, with a handful of server vendors and commercial Hadoop disties more than happy to take your money. For the latter, you have been pretty much on your own.
But now you can buy an appliance made by Cray that's based on massively multithreaded processors with huge shared memory that have been, up until now, the playthings of the US government's spooky agencies.
The appliance, called Urika (well, actually uRiKA but we don't hold with ransom note capitalization here at El Reg), is a combination of open source software to do graph analysis on big data coupled with the fourth generation of Cray's "Threadstorm" massively threaded processors that has been tuned to do relationship analytics, or what is sometimes called graph analytics. Essentially it is like playing n degrees of Kevin Bacon on your data sets – not to look for a specific piece of information, but rather to divine how all of the elements of a data set are connected to one another.

Cray's Urika graph appliance
The Urika appliance is the first product of the YarcData division that Cray announced last month, Yarc being Cray spelled backwards and also the internal acronym for "Yet Another Router Chip" when the "Gemini" XE interconnect used in Cray's XE6 and XK6 massively parallel supercomputers was in development.
Cray tapped Arvind Parthasarathi to be senior vice president and general manager of YarcData. Parthasarathi came to Cray from Informatica, where he was general manager of its Master Data Management (MDM) business unit. He was previously director of product management at supply chain specialist i2 Technologies (now part of JDA Software) – and this is important for the Urika appliance.
"Graphs have been around forever," Parthasarathi tells El Reg, with the Königsberg Bridge Problem of the early 18th century being a famous one that asked if you could start at one place in Königsberg and cross all seven bridges in the city without doubling back and with ending up at your starting point. (Euler proved you can't.) Traveling salesman problems, which play connect-the-dots across a spatial data set to find the most efficient route to hit all the spots, are another famous kind of graph problem.
"A lot of problems in the world are actually graph problems," Parthasarathi said, "and I found out at Informatica, a lot of supply chain problems are in particular graph problems."
The problem is that graph problems are tricky and not well-suited for traditional clusters of machines, like Hadoop data chunking and reducing is. (Well, you could argue that, too. But moving right along...)
Most big data munchers store data as key/value combinations, XML documents, columnar data, or relational data in a table, and the data is chopped up into partitions. This is fine, because you can parallelize an SQL query or a MapReduce routine and run it on the chunks, and then aggregate the distilled "answers" after you are done chewing.
But with graph applications, where you need to follow the connections between data, every time you leave a node in a cluster, you are leaving main memory and talking over the network, and that is on the order of 100 times slower than memory. And that makes walking the links between data points very time consuming.
Moreover, graph data sets are inherently non-deterministic – unlike a lot of what we do on PCs on our desks and servers in the data center – and from any one point, you actually have to follow all potential paths in the data to see where it goes. You can't prefetch and cache this data to make the graph walking any faster. Now, add the fact that in the real world, you want to ask questions in real time and are constantly updating the data. Getting data out of storage and into main memory of a server is about 1,000 times slower than storing it in memory in the first place.
Obviously, if you look at the graph problem, what you need is a machine with a zillion threads and a couple of ba-zillion gigabytes of main memory to store the data all in memory. Cray has not built such a machine, of course. But the Urika appliance comes as close as any other machine you can buy.
Urika is based on the massively multithreaded MTA chip created by super-geniuses Jim Rottsolk and Burton Smith (both now at Microsoft). In fact, according to Shoaib Mufti, vice president of R&D at the YarcData unit, it's based on the fourth-generation MTA design that Cray's former Custom Engineering division was working on for a number of government and academic customers.
The original MTA and MTA-2 processors created by Tera had their own sockets, but with the XMT machines, Cray renamed the processor ThreadStorm, jacked it up to 128 threads, and made it plug into the 1,207-pin Rev F socket used by Opteron 8000 series chips. The jump from MTA-2 to ThreadStorm saw clock speeds bump up from 220MHz to 500MHz, and processor count jump from 256 CPUs to 8,192 CPUs using the XT4 chassis and its SeaStar2 interconnect to create a single shared memory system.
Because the MTA-2 chip, and now its follow-on used in the Urika machine, uses the Rev F socket, it can slide into XT4 and now XT5 blade servers that would have normally been populated with Opteron chips. So one socket, one motherboard, and one interconnect can be used to put radically different processors into essentially the same machine to address very different workloads.
You might be thinking what I was thinking: that Cray would have built the Urika box using its XE6 blades (which have the G34 socket from Advanced Micro Devices) and much faster and higher-bandwidth XE interconnect.
But doing so would have forced Cray to do a socket shift for the Threadstorm+ chip – a very expensive proposition for a small customer base – and, Mufti tells El Regthat the modified SeaStar2+ interconnect used with the XT5 machines has finer-grained network and memory control than the Gemini interconnect.
The fourth-generation ThreadStorm chips are still running at 500MHz, but based on early customer use of the XMT machines, Cray has done a bunch of tweaks to boost performance on specific workloads like graph analysis.
The XT5 blade has eight Opteron processor sockets, and in the Urika machine four of these are populated with the single-core, 128-thread ThreadStorm+ processors. The four other sockets are equipped with additional DDR2 memory controllers, which are not part of the Threadstorm dies.
Cray stuck with DDR2 because this memory is not bursty, as is DDR3, which would actually work against the XMT design, which is all about having lots of threads, moving slow and moving steady. When you have 128 threads, when a bunch stall, there is usually an open one to do some work while the thread fetches data or waits for a calculation to complete.
Each ThreadStom socket has four memory slots and can be equipped with 4GB, 8GB, or 16GB memory. You put four of these ThreadStorm blades in a rack, and that is your base system with 512 threads and 512GB of main memory. In this case, the memory runs at lot faster than the processor, rather than the other way around in most systems today. This is a good thing, both for performance and for reducing power consumption.
The SeaStar2+ interconnect can span up to 8,192 processors (that's 1.05 million threads) and 512TB of shared main memory in a single image using 16GB memory sticks. The good bits are that as far as Linux is concerned, this machine looks like a single wonking uniprocessor with an astounding number of threads and main memory. And the machine has a parallel I/O subsystem that is capable of moving data into and out of the appliance at rates of up to 350TB per hour.
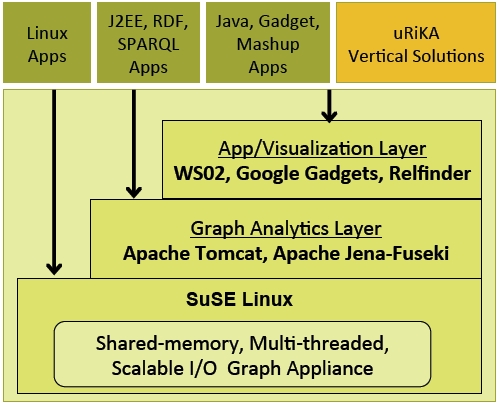
The Urika software stack: SLES and open stack graph analysis tools
The hardware, while impressive, is not particularly useful without some software. The Urika stack is based on the Apache Jena project, which is a Java framework for building semantic web applications. SPARQL is the pattern-matching query language for graph applications, and Apache Fuseki is the SPARQL server that runs in conjunction with the Jena framework and that allows data stored in the RDF format, the special format for graph data, to be served up over the HTTP protocol. Applications to analyze and visualize the graph data can be coded on top of this query language and format using existing tools such as Google Gadgets, WS02, and Relfinder.
The Urika machine starts at one rack at a cost of "several hundreds of thousands of dollars," according to Parthasarathi, including the software stack.
Eventually, Cray will be working with partners to craft vertical solutions in the life sciences, social networking, financial services, healthcare, intelligence, supply chain, and telecoms industries to make use of the Urika platforms in conjunction with other big data and OLTP systems they might already be using. ®
