This article is more than 1 year old
Nvidia: No magic compilers for HPC coprocessors
No free lunch for MIC, either
Steve Scott, the former CTO at supercomputer maker Cray, joined Nvidia last summer as CTO for the chip maker's Tesla GPU coprocessor division, and the idea was to shake things up a bit and not only sell more Tesla units, but to shape expectations in supercomputing as we strive to reach exascale capacities.
And so, in his first big statement since joining Nvidia, Scott put out a blog that pours some cold water on what are perhaps the uninformed expectations of companies looking to use various kinds of coprocessors – be they Intel's Many Integrated Core (MIC) parallel x86 chips, Nvidia's Tesla GPUs, or Advanced Micro Devices' FireStream GPUs. Scott's observations are well-reasoned, subtle, and timely, if not as earth-shattering as what color the next iPhone will be.
It has been obvious since IBM built the petaflops-busting "Roadrunner" hybrid CPU-Cell blade supercomputer for Los Alamos National Laboratory that hybrid architectures are the way to push up into the exascale stratosphere and not have the supercomputer powered by its own nuclear plant and melting through the Earth's crust thanks to all of the heat it emits.
In a call with El Reg discussing the blog post, Scott said that it took about 1.7 nanojoules of energy to do a floating point calculation on a six-core "Westmere" Xeon 5600 processor implemented in 32 nanometer processes, but a "Fermi" GPU used in the Tesla coprocessor implemented in a fatter 40 nanometer process only consumed 230 picojoules per flop. Since you can't optimize a core for both energy-efficiency and fast single-thread performance, you need the CPU to do serial work that might otherwise hold up the GPUs, and let the GPUs to do parallel calculations at a throughput that a CPU can't without expending lots of energy.
It is now obvious, since Intel reincarnated its "Larrabee" x86-based graphics processor as the "Knights" family of coprocessors, that Intel, AMD, and Nvidia essentially agree that hybrid is the future for HPC. Ironically, IBM is moving in many different directions when it comes to supercomputers, including massively parallel architectures with wimpy and brawny Power cores, as well as hybrid ceepie-geepie machines that are largely composed of other vendors' components.)
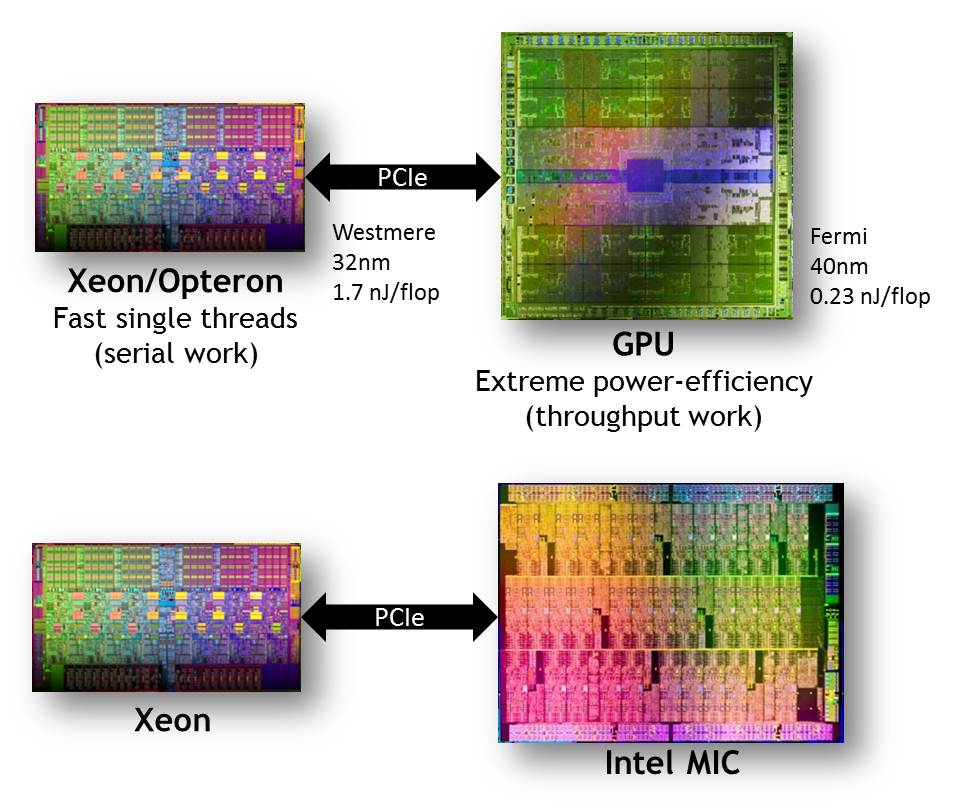
Hybrid HPC is the way to go (click to enlarge)
There are many differences between a GPU coprocessor and a MIC coprocessor, but conceptually they are similar in that they have lots of cores – hundreds for the GPU and dozens for the MIC – that share L2 cache memory, GDDR main memory, and offload floating point calculations from the CPU. "The reason I wrote the blog was not because I am critical of MIC," explains Scott. "If I were Intel, this is exactly what I would do."
Hybrid means sharing work across lots of CPUs and GPUs
"While I agree with this," Scott wrote in the blog, referring to the hybrid future for supercomputing, "some of the discussions around programming the upcoming MIC chips leave me scratching my head – particularly the notion that, because MIC runs the x86 instruction set, there's no need to change your existing code, and your port will come for free."
Scott makes a good point. When Intel has shown off the performance of the "Knights Ferry" development MIC coprocessor, as it did last fall at Intel Developer Forum, you only ever see the application scaling on a single MIC coprocessor. In this case, it was a Knights Ferry chip with 64 cores, and in early benchmarks cited by Scott in his blog, Intel is showing MIC units with 128 threads (which would suggest that there are two threads per core on the MIC units).
While this is all very exciting, the point is, according to Scott, that using the -mic flag in the Intel compilers to crunch down the applications tested on the MIC chip means that the app is compiled specifically to run on only a single MIC coprocessor using the MPI protocol used to link supercomputer nodes to each other. In essence, you are treating that MIC unit as a 64-node baby supercomputer and completely ignoring the x86 processor to which it is linked.
This, Scott tells El Reg is a completely unrealistic way to talk about any coprocessor because there are some MPI operations that require a fast single thread to do stuff, and with this way of using the MIC unit, you have an Amdahl's Law problem that your workload will slow down and wait for a single core running that single-thread job to finish before re-embarking on parallel calculation bliss.
Moreover, these cores will all be chatting back and forth with MPI operations and the Pentium core at the heart of the unit might not have enough oomph to get the serial work done quickly, and you might only have 8GB or 16GB of memory per MIC unit, which could work out to 128MB to 256MB per core, compared to the 1GB or 2GB you have per x86 core on a regular x86 server node when you expect to do serial work fast.
The other thing you can do with a MIC coprocessor, since it is an x86 architecture chip, is to run OpenMP on it and treat the MIC chip as a large SMP system with the GDDR memory as globally accessible. But OpenMP does not yet scale well, even if it will be a lot less chatty than running flat MPI on the MIC. "The idea of keeping more than 4 or 8 cores busy with unmodified OpenMP code is not realistic," says Scott. And you still have the limited memory per core and Amdahl's Law bottleneck as well.
The final approach that you can take with a coprocessor is to use it as an accelerator, which is the way that Nvidia is using its CUDA programming environment to take advantage of the compute capacity in the Tesla GPU coprocessors.
"And even here, nothing is free," says Scott. "Future codes are going to have to be worked on to expose more parallelism and offload it to the coprocessor. There is no such thing as a magic compiler."
To get to exascale supercomputers that can be powered and cooled within reasonable (and yet exorbitant) economic budgets, you need to get down to around 20 picojoules per flop – more than an order of magnitude better than the Fermi chips. And with clock speeds topped out and electricity use and cooling being the big limiting issue, Scott says that an exaflops machine running at a very modest 1GHz will require one billion-way parallelism, and parallelism in all subsystems to keep those threads humming.
It's a tall order, and one that is going to take the best minds on the planet to solve. ®
