This article is more than 1 year old
Amazon's S3 object count kisses 1 trillion
Buying Bezos by slice
It started out so small, a mere 200,000 objects, with the 2006 launch of the Simple Storage Service (S3) object storage companion to the Elastic Compute Cloud (EC2) compute cloud. Six years later, and Amazon's infrastructure cloud is getting ready to handily bust through 1 trillion objects under management.
In a blog post, Jeff Barr, at the Amazon Web Services infrastructure unit, says that the S3 service contained 905 billion objects as of the end of the first quarter. This is an amazing number of files for any single entity to house.
Perhaps more significantly, the peak number of requests that the S3 service is fielding is now at 650,000 requests per second, with occasional peaks going even higher.
Amazon has kept the S3 data a little close to its chest over the years, but here is what the Q1 2012 data looks like against the data from the fourth quarter from each year since the S3 service was launched:
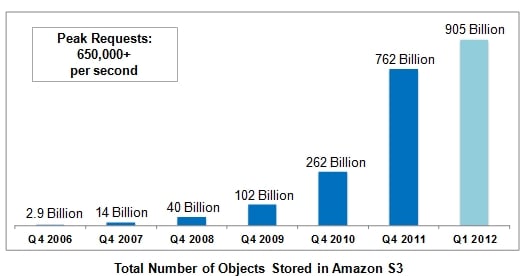
Amazon's S3 object growth over time (click to enlarge)
El Reg has poked around gathering up other data points here and there over the past year, and we have assembled more quarterly data about the S3 service than Barr put in his blog. Every point with a blue diamond is an actual data point for that quarter in the chart below. We fit the curve as best we could between the dots.
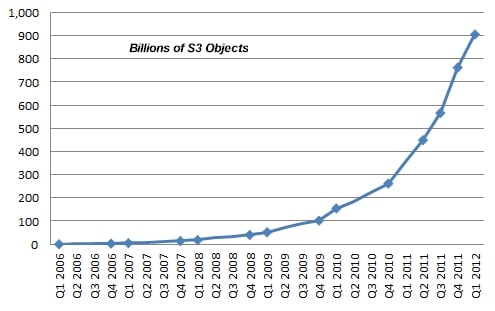
The S3 cloud: Not quite a hockey stick – yet
The tapering off of the S3 object growth in the first quarter was no doubt in part due to the launch of object expiration and multi-object deletion, both of which came out in December 2011.
Barr says that every day AWS import/export, the S3 storage gateway, the S3 APIs, Direct Connect pipes, and various backup tools that work with S3 are adding "well over a billion objects" per day.
Actually, it is closer to 1.57 billion a day in the first quarter of this year, if you do the math on the Q4 2011 and Q1 2012 data and average over the days.
In a sense, by offering the automatic file retirement services, Amazon chopped off the handle of this hockey stick curve. This may make the S3 service look less impressive in terms of straight math but it also makes S3 a more useful service and hence more appealing to customers who shell out bucks to use Amazon's disk drives instead of their own.
Amazon has not given out peak file request data as frequently as the object count, but this is what we know. Back in the first quarter of 2009, Amazon said S3 was peaking at around 70,000 file requests per second, and in some customer presentations Amazon said it hit 200,000 peak requests per second in the second quarter of 2011.
We were told earlier this year when we did a story on the S3 ramp that it was peaking at 370,000 requests per second, and now it has rocketed up to 650,000 requests per second.
So even as the service is now automagically retiring files to the bit bucket, the amount of requests is on a very fast ramp indeed. It would be interesting to see what the bandwidth is on the S3 cloud, and how much money it generates.
Show me the money
And where is the comparable EC2 data?
Amazon does not, of course, talk about the dough that AWS generates in the aggregate or for any particular service individually.
In the first nine months of 2011, Amazon posted $30.6bn in sales (up 44.2 per cent) while the Other category, where AWS and various other unspecified product sales get parked in Amazon's financials, accounted for $1.08bn in sales (up 70.4 per cent).
Assume that when Amazon reports its final 2011 quarter the Other category is around $1.5bn, and maybe three quarters of the revenue is AWS. If those assumptions are correct, then AWS has already broken through $1bn in annual sales.
If that were the case, AWS would still only be about three per cent of revenue, but how many IT departments in the world are making money instead of spending money?
The interesting question is this: Are the millions of EC2, S3, and other AWS service users now giving Amazon enough money to use its data center to pay for Amazon's own usage out of the profits? ®
