This article is more than 1 year old
Intel slaps Xeon Phi brand on MIC coprocessors
Cray to plug them into future 'Cascade' supers
ISC 2012 The name "Many Integrated Core" doesn't roll off the tongue – and even Intel doesn't know whether to pronoun MIC as "mick" or "mike" – so with the future "Knights Corner" x86 coprocessors intended to thwart the coprocessor plans of Nvidia and its Tesla family, Chipzilla is settling on the brand name of Xeon Phi to peddle its variation on the energy-efficient coprocessor theme.
The company rolled out the new brand at the International Supercomputing Conference in Hamburg, Germany, while at the same time providing a little more guidance on the production schedule, and picking up an endorsement from supercomputer-maker Cray.
Phi, of course, is the Greek letter associated with the golden ratio, which pops up all over the place in nature and is most famous in the Fibonacci spiral. And those of us who studied math will know how to pronounce it "fie" instead of "fee," or perhaps will argue about the correct pronunciation depending on our accents. (Yes, I just set that up for you. You're welcome.)
Intel is not all that interested in the golden ratio, but rather the gold in them thar HPC hills – and keeping as much of it out of Nvidia's and AMD's hands as it possibly can. Every GPU coprocessor kills a bunch of x86 server chips. It really is that simple in the advance towards exascale computing.
Ahead of the ISC event, vice president of the Intel Architecture Group and general manager of technical computing Rajeeb Hazra briefed journos and analysts on the new branding for the MIC processor, which will sport more than 50 active x86 cores, and which will very likely have 64 cores on the die with a bunch of them deactived to boost chip yields, and running at somewhere between 1.2GHz and 1.6GHz. Hazra also talked at length on the importance to Intel of the HPC space in general, the Xeon Phi chips in particular, and his company's race to exascale computing by 2018 or so.
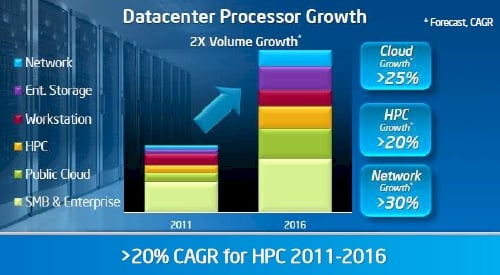
Intel's Data Center and Connected Systems Group forecast through 2016
Intel wants to double the revenue and processor shipments coming out of the Data Center and Connected Systems Group between 2011 and 2016, and is well on its way to do that with the uptake of Xeons in both storage and networking – but to get a big piece of the HPC action, Intel also needs some kind of coprocessor that offers much better performance per watt and that can compete against the GPUs that Nvidia is kicking out in terms of pricing and performance.
Intel has the chip-process advantage, and is going to be implementing the first iteration of Xeon Phi, "Knights Corner", in its 22-nanometer Tri-Gate transistor-etching process, which is also used on the "Ivy Bridge" Core and Xeon E3-1200 v2 processors today. Nvidia will have the advantage of bringing consumer-level manufacturing to the GPU coprocessors, like the GK104 chip used in the Tesla K10 board, that are aimed explicitly at workloads that need only single-precision floating point math, such as in various applications in financial services, life sciences, and seismic and image processing.
On high-end double-precision coprocessors, the Xeon Phi will go head-to-head with Nvidia's GK110 chip in coprocessor cards that are not particularly high volume and that are so big and complex the yields will be low and the prices per unit relatively high.

Intel's 'Knights Corner' Xeon Phi chip
What both Intel and Nvidia are focused on – and what AMD seems to have forgotten – is that the HPC market is projected to grow at more than 20 per cent in the next five years, considerably faster than the server market at large. And despite some very large monolithic systems on the latest Top 500 super computer rankings, most people expect future HPC clusters – and maybe even servers that do lots of calculations in the data center – will be based on hybrid CPU-coprocessor architectures. Accordingly, the stakes with Xeon Phi are high – and this is more than taking a failed "Larrabee" x86-based GPU effort and making it pay for itself. Also, because it is technically a Xeon sub-brand, no matter what happens with CPUs and coprocessors in the HPC racket, Intel will be able to say that Xeon is the dominant chip – provided ARM and GPU collectives don't kick the tar out of Intel, of course.
Intel has not seemed to be in much of a hurry to get the Xeon Phi coprocessors into the field, and Hazra said that the plan was for the Knights Corner variant of the chip to be in production by the end of this year. When pressed, he would not elaborate on when it might be for sale or how Intel would take the coprocessor to market, but presumably Intel will go the OEM route much as Nvidia has with the Tesla coprocessors, letting server makers buy them and integrate them with their systems, and not selling them to customers directly through channels.

Terafloppers: Intel's ASCI Red, circa 1997, and Knights Corner coprocessor, circa 2012
Intel is not providing much in the way of detail on the Knights Corner coprocessor, except to say that the card will plug into a PCI-Express peripheral slot on a server and that it will have at least 8GB of GDDR5 memory for the 50-plus cores on the chip to share to run work offloaded from the CPUs in a cluster.
Intel has said that the Knights Corner coprocessor card will be able to run whole applications, including an MPI stack like a baby cluster if customers want to do that, but as former Cray CTO and now Nvidia Tesla CTO Steve Scott pointed out recently, the programming models are just as complex for MIC as they are for GPU coprocessors, and that's not a lot of memory to run MPI or OpenMP stacks natively on the coprocessor card, either.
Intel showed off the Xeon Phi chip pushing 1 teraflops at double-precision math running the DGEMM matrix math benchmark. That's only one card running one benchmark, and the real test is how a server cluster equipped with hundreds or thousands of Xeon Phi coprocessors will do running Linpack and other benchmarks, and then real workloads. Intel showed off a single Knights Corner coprocessor running Linpack at 1 teraflops peak (not sustained) performance at ISC on Monday.
To counter the MIC skeptics, Intel slapped together a cluster called "Discovery", which came in at 150 on the latest Top 500 rankings. This machine uses eight-core Xeon E5-2670 processors running at 2.6GHz in its two-socket server nodes. The nodes are lashed together with 56Gbs FDR InfiniBand cards and switches, and have Knights Corner coprocessors dropped into the servers as well. The exact feeds and speeds of the Discovery cluster were not divulged, but the machine has a total of 9,800 processor cores and a source at Intel tells El Reg it is "significantly lower than 100 nodes."
If you play around with some numbers (and El Reg can't resist) and assume you have two Knights Corner coprocessors per server node with 54 cores activated and two Xeon E5-2670s, you can get 9,796 cores across 79 server nodes. That would be 158 teraflops of raw peak Linpack performance from the aggregate MIC cards, and another 26.3 teraflops peak from the 1,264 Xeon cores.
This jibes almost perfectly with Intel's own peak performance with the Discovery cluster, which came in at 180.99 teraflops peak and 118.6 teraflops sustained on the Linpack test. The important thing is that with what we presume were 158 MIC cards, Intel was able to get a computational efficiency of 65.5 per cent (meaning that share of cycles that could do work across the ceepie-phibie did work) and only burned 100.8 kilowatts.
That works out to 1,176 megaflops per watt sustained Linpack performance, which is not too shabby. It's still not the 2,068 megaflops per watt that IBM delivered with its "Sequoia" BlueGene/Q machine at Lawrence Livermore National Laboratory, however. Intel still has some work to do tuning its Cluster Studio XE and Parallel Studio XE compilers and development tools to make the best use of Xeon Phis, but this result is perhaps better than many people had expected.
Cray is basing its next-generation "Cascade" supercomputers with the "Aries" interconnect, which it sold off to Intel back in April, on Intel's Xeon processors, and has not said whether it will support Opteron processors or Nvidia Tesla coprocessors in these machines, as the current XE6 and XK6 supers do. The company did announce at ISC that it will be supporting Xeon Phi coprocessors alongside Xeon CPUs in the Cascade machines, which go into production in 2013. (Cray retains a license to the Aries interconnect so it can sell systems based on it.) The US Defense Advanced Research Projects Agency commissioned the development of the Cascade super from Cray and will get its machine later this year; the exact feeds and speeds of that box have not been divulged. ®
