This article is more than 1 year old
Berkeley Lab to air-cool Cray Cascade super
2 petaflops, 6 petabytes for a mere $40m
Lawrence Berkeley National Lab, which runs the big and unclassified science projects for the US Department of Energy, is sticking with Cray for its next-generation supercomputer, tentatively called NERSC-7.
That's short for National Energy Research Scientific Center, which is one of the largest basic science computational centers in the world and which is located in the temperate climate of Berkeley, California.
Cray was able to win the NERSC-7 thanks in part to the success of the "Hopper" Cray XE6 Opteron cluster using the "Gemini" XE interconnect, which has 1.05 petaflops of sustained performance on the Linpack Fortran benchmark test. Hopper ranked fifth in the world when it came online in the fall of 2010, but has subsequently fallen to number 16 on the latest Top 500 supercomputer rankings. The NERSC-7 machine will get Berkeley Lab back into the hunt, and it will be based on the future "Cascade" system design and "Aries" interconnect that Cray has been fashioning for the US Defense Advanced Research Projects Agency.
But don't think that Cray was a shoe-in for the NERSC-7 deal, as this roadmap toward exascale computing for the Berkeley Lab shows:
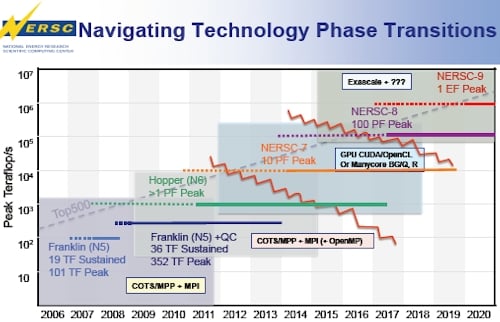
Berkeley Lab's NERSC systems roadmap
That roadmap, put together by John Shalf, group leader for NERSC's advanced technology group in August 2010 to discuss the issues around getting to exascale systems, shows the "Franklin" Cray XT4 system, which was its NERSC-5 box and which had 101 teraflops of peak performance and which was subsequently upgraded to quad-core Opterons to push up to 352 teraflops.
The Franklin machine was decommissioned this past April, and that is one of the reasons why NERSC is looking to add some capacity. But as you can see from the roadmap, only two years ago Berkeley Lab was thinking that NERSC-7 might be a box with GPU coprocessors or even a future BlueGene/Q or BlueGene/R machine (we haven't heard of BlueGene/R yet) to get to 10 petaflops of peak aggregate number-crunching power.
The feeds and speeds of the NERSC-7 box were not divulged, but Cray says Berkeley Lab is going to install a Cascade machine with 2 petaflops of performance, which is double what Hopper offers, using Xeon processors from Intel. It is not clear what Intel processors Cray has planned for the Cascade boxes, but it will either be the current "Sandy Bridge" Xeon E5s or the future "Ivy Bridge" Xeons, which should start rolling out next year on 22 nanometer processes according to Intel's tick-tock chip manufacturing method.
Cray has not said if it will support Opteron processors in the Cascade boxes, or Tesla GPU coprocessors for that matter, which probably has Advanced Micro Devices and Nvidia a little jumpy. What Cray did say two weeks ago at the International Super Computing conference was that the future Cascade machines would support the Xeon Phi x86-based coprocessor, formerly known as "Knights Corner" or MIC.
Sources at Cray say that the NERSC-7 machine is a brand new install and as far as they know, the initial contract does not call for the use of Xeon Phi coprocessors. All the math will be done by the Xeons. But clearly, Berkeley Lab could become a testbed for the Xeon Phi coprocessors and boost its raw performance to the 10 petaflops range the NERSC-7 contact calls for. And that is not just some arbitrary number.
According to a presentation (PDF) made by Richard Gerber, director of users services at NERSC, in February of this year, the users at Berkeley Lab are screaming for more flops for the NERSC-7 system cycle.
All of the different areas of the lab – advanced scientific computing, biological and environmental, basic energy science, fusion energy, high energy physics, and nuclear physics – turned in their projected needs for the next couple of years, and that came to 15.6 billion compute hours by 2014, more than ten times the amount of compute-hours used by the lab in 2011. That's a 10 petaflopper. If you use the current Xeon E5-2600 processors and put one Xeon Phi per socket in the box, you could push the raw aggregate computing power of a Cray Cascade machine to 14 petaflops peak.
No one is saying that Berkeley Lab will do this, but it could. The interesting bit that the nuke lab is confirming is that the Cascade system will be put into a "free cooling" data center, which will use the chilly outside air coming off San Francisco bay, to keep the NERSC-7 machine from melting.
"This approach utilizes water from cooling towers only, not mechanical chillers, to provide exceptional energy efficiency," explained said Jeff Broughton, head of NERSC's systems department, in a statement. "The moderate Bay Area climate combined with Cray's new design will allow us to keep power for cooling to less than 10 per cent of the power used for computing." This is a big deal when your power bill comes from a California power company.
In addition to the 2 petaflops Cascade system, NERSC-7 will use the next-generation and as-yet unannounced Sonexion Lustre parallel file systems from Cray. These future Sonexion arrays will be kickers to the current Sonexion 1300s, and they will be commercialized in the first half of next year, like Cascades. That array will be able to support up to 140 GB/sec of sustained aggregate I/O performance, and it will be interesting to see if Cray puts the Gemini or even the Aries interconnect at the heart of the disk clusters as well as the compute clusters.
Why not? The current Gemini XE interconnect is a high radix, 48-port YARC (Yet Another Router Chip, and Cray spelled backwards) router with an aggregate of 168GB/sec of bandwidth and something on the order of 2 million packets per core per second in an XE6 super; that message throughput is about 100 times that of the SeaStar+ interconnect, and it is what allows an XE6 machine to scale to 1,000 cabinets and about 3 million Opteron cores, if you want to do that.
Gemini was a dumbed-down version of Aries, one that linked into the Opteron HT3 ports instead of the PCI-Express 3.0 ports that Aries uses (and presumably, only on-chip PCI-Express links, like the Xeon E5 processors have).
The value of the NERSC-7 deal, which includes the cluster and storage as well as the software licenses and support over multiple years, comes to $40m. This is an astounding level of bang for the flops, when you consider that the "Red Storm" super that got Cray on the massively parallel path with Sandia National Labs a decade ago.
Red Storm, which was just decommissioned, used the original SeaStar interconnect to lash together Opteron processors to deliver about 43.5 teraflops of peak performance; it cost $90m, and that was without the storage. NERSC-7 is nearly 46 times the performance for half the money, if you want to call the storage a freebie.
And it is far more likely that storage represents half the cost, so the raw compute power is more like 200 times less expensive than it was only a decade ago on capability-class systems. The irony is, at these prices, an exascale machine would still cost $1bn, and no one can afford that. ®
