This article is more than 1 year old
US Energy dept starts handing out cash for exaflop superputer quest
Need to get the 'leccy bill down below that of a city
The Department of Energy is continuing to dole out cash to pay for some of the basic research that needs to be done if the United States is going to field exascale-class supercomputers by 2020 or so. This time around, Nvidia and Intel have taken down some contracts, and El Reg hears that Big Blue is getting some funding as well.
IBM is in its quiet period just before putting out its financial results for the second quarter, and that could be why the company has not said anything about its awards under the FastForward portion of the DOE's Extreme-Scale Computing Research and Development program, which has become the main vehicle for the creation of systems with 1,000 petaflops of number-crunching performance and 1,000 petabytes of data store.
As El Reg explained in detail last week, the first phase of the exascale project is called FastForward, and it has a nominal amount of funding that is designed to get some primary research done that will lead to exascale systems. We have contacted the DOE a number of times to get more details about the budgeting for the three phases of the Extreme-Scale project, but thus far DOE is keeping a tight lip about the plans. The development of exascale systems is expected to cost hundreds of millions if not billions of dollars, so you can understand why DOE doesn't want to talk about spending that much dough in an election year. Moreover, while the Extreme-Scale project is funded in part by the DOE's Office of Science, which does basic research, the National Nuclear Security Administration part of the DOE, which manages the American nuclear weapons stockpile, is also not only kicking in funds but is also expected to be the first big beneficiary of exascale systems. Ever more powerful supercomputing is needed to simulate old nukes and confirm they'll still work, or to design new ones: the problems are particularly intricate as real-world explosions are forbidden under the Nuclear Test Ban Treaty.
The Extreme-Scale project has an initial research phase, called FastForward, and which has an intentionally somewhat vague statement of work since it is dedicated to some of the primary research in processor, memory, and storage and I/O technologies that will be required in exascale systems. The engineering challenges are daunting. Extrapolating current technologies with Moore's Law will be woefully insufficient to meet the power envelope, cost (both capital and operating), and reliability requirements of an exascale system, so real engineering breakthroughs must be made to get a machine that might only require 20 megawatts of juice to do an exaflops of work against an exabyte of data.
Last week, AMD announced it received two contracts worth $15.6m to do research on memory subsystems and interconnects relating to memory as well as exploring the use of hybrid CPU-GPU architectures to boost the performance of HPC machines. Whamcloud, a company that offers commercial support for the open source Lustre parallel clustered file system, also took down a contract, rumored to be worth $8m, in conjunction with partners HDF Group (which has application I/O expertise), EMC (which is bringing in experts for system I/O and I/O aggregation), and Cray (which is doing scale-out testing of the big bad storage systems).
Nvidia's Bill Dally, the head of the computer science department at Stanford University who took a two-year sabbatical to be chief scientist and head of Nvidia Research, came back to Nvidia in March in those roles and is spearheading the $12.4m project that Nvidia is doing as part of the FastForward phase of the Extreme-Scale DOE project. The research will be based on the earlier "Echelon" system that Nvidia conceived as part of the US Defense Advanced Research Project Agency's Ubiquitous High Performance Computing program announced in March 2010 and now superseded by the DOE effort.
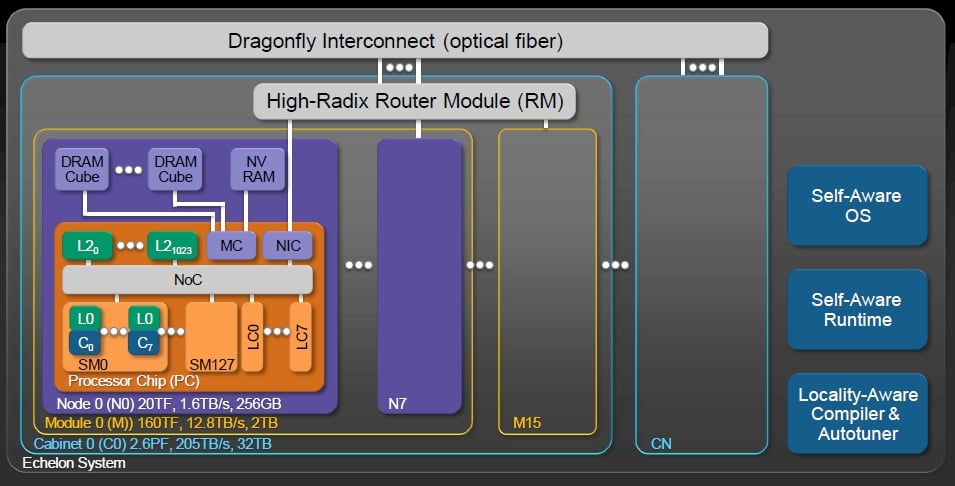
Block diagram of Nvidia's Echelon exascale system (click to enlarge)
Echelon proposed creating a special processor with four double-precision fused multiply-add (DFMA) units and some Level 0 instruction and data cache for those units and their main registers and operand registers. This block would be able to do about 20 gigaflops of peak number crunching. You pack eight of these into a single unit with a switch linking them to a shared Level 1 cache memory and comprising a "streaming multiprocessor" or SM. A single chip would have 128 of these SMs, rated at a combined 20.5 teraflops and would include plus 1,024 banks of Level 2 static RAM cache (measuring 256KB each for a total of 256GB of cache), plus memory controllers, network interface cards, and eight of what Nvidia called latency processors.
An Echelon node multichip module would have eight of these linked together on a single substrate linking out to 3D stacked DRAM memory (through 1.4TB/sec of memory bandwidth) with 150GB/sec of network bandwidth coming out of the interconnect. There are also ports on the node for direct link to non-volatile storage memory. A node module would be rated at 160 teraflops peak and would have 12.8TB/sec of memory bandwidth at 2TB of main memory. A cabinet of Echelon iron would have 16 modules offering a total of 2.56 petaflops and would consume about 38 kilowatts, according to a presentation put together by Dally for the DARPA work, and 400 cabinets would get you to an exaflop at around 15 megawatts.
This sounds like mission accomplished, right? Wrong. For one thing, Cray was on the Echelon team and its "Aries" interconnect, which will probably be commercialized as Dragonfly, was an integral part of the Nvidia design. So was the high-radix router module, a component of the Aries interconnect presumably, that Nvidia was proposing to put in its Echelon chip. Now Intel owns Cray's Aries interconnect as well as the patents behind the interconnect biz and the key employees (minus former Crayon Steve Scott, now Tesla CTO at Nvidia). And you can bet that Intel is in no mood to share with Nvidia – particularly when it wants its Xeon Phi x86-based coprocessors to be used instead of Nvidia GPUs in petaflops and exaflops systems.
In a blog post, Dally confirmed that the FastForward contract with the DOE would leverage the work done on Echelon, and just to put all the engineering into perspective, Dally said in theory an exascale system using today's CPU technology would take about 2 gigawatts – yeah, 1,000 megawatts – to power and cool, and that this was equivalent to the entire output of the Hoover Dam. If you moved to the forthcoming Tesla K20 GPU coprocessors, coming later this year, to do the math, you are down to maybe 150 megawatts to juice up an exascale box.
"Achieving this level of efficiency will require extraordinary innovation on a number of fronts," Dally wrote. "However, we firmly believe that heterogeneous computing offers the best approach to get there."
That's another way of saying that you need to minimize the use of traditional CPUs, which are optimized for single-thread performance, and go massively parallel with modest processors, like those in the GPU.
Intel Federal, the unit of the chip maker established last September to chase big HPC and big data deals at the US government, has taken down two FastForward contracts worth a combined $19m.
At the same time, Mark Seager, former head of HPC systems at LLNL, was tapped by Intel to be CTO for the chipmaker's HPC Ecosystems group. Seager was in charge of the Advanced Simulation and Computing Initiative (ASCI) program at LLNL, and was responsible for ASCI Blue Pacific, ASCI White, ASCI Purple, and BlueGene/L, which were all based on IBM's Power servers and proprietary interconnects. Intel wants to own this business, and has made no secret about it. Intel will be working on processor projects, featuring future Xeon and Xeon Phi designs, as well as on interconnects. The expectation is that Intel will perfect its near threshold voltage chippery, demonstrated with the "Claremont" Pentium chip, as well as the 3D memory stacking technology (called Hybrid Cube Memory, or HCM) that Intel is developing with Micron Technology, Samsung Electronics, and others. But the specifics of the work Intel is doing were not detailed.
"High-performance computing is a transformative technology that will allow current and future generations of scientists and engineers to develop breakthrough advancements to address our most pressing societal issues," said David Patterson, president of Intel Federal, in a statement. "This is a great example of how public-private partnerships will significantly help move high performance computing forward and push the boundaries of innovation." ®
