This article is more than 1 year old
Intel accidentally outs 'Poulson' Itanium specs
The Intertubes giveth and taketh away
The webmeisters of the world have given once again, with Intel accidentally outing some of the feeds and speeds of the impending "Poulson" Itanium processors for midrange and high-end servers. Some of the data has already been taken down, and all of it will probably follow shortly.
An intrepid reader of El Reg pointed out to the systems desk that the Itanium Processor 9500 Series: Reference Manual was available on the Intel web site, which gives details on the microarchitecture, performance, and other aspects of the chips.
The manual is mostly useful for coders working on HP NonStop, OpenVMS, and HP-UX machines at this point, plus a smattering of Bull, Fujitsu, and NEC mainframes.
A lot of information about the Poulson chips has already been divulged. Intel briefed press and analysts before the IEEE International Solid-State Circuits Conference in February 2011, confirming that Poulson would have eight cores and that it would be implemented in the 32 nanometer process. That process is being phased out this year for desktop chips and will be replaced by the 22 nanometer Tri-Gate process. Intel then gave even more details about the Poulson chips during its two big ISSCC presentations.
Here's a die shot of the Poulson chip and a quick refresher, and then we'll dig into the new data from the reference manual.
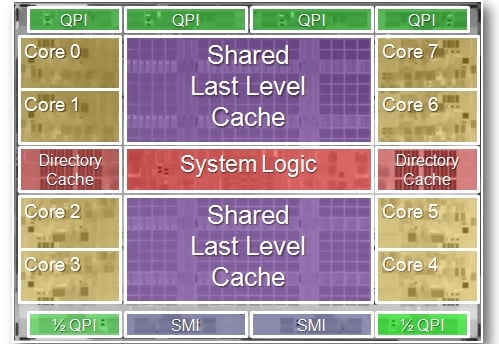
Poulson has eight cores, two directory caches, five QuickPath Interconnect (QPI) links, two Scalable Memory Interconnect (SMI) DDR3 memory controllers that support up to 512GB per socket, two shared L2 caches, and a bunch of system logic all on the same piece of silicon, which has a combined 3.1 billion transistors packed into a 588 square millimeter die size. The top bin part is expected to throw off 170 watts, which is a bit better than the 185 watts of the top-bin four-core Itanium 9300 processor it will replace.
As you can see, the Poulson uses a "cores out" design, just like the current "Sandy Bridge" Xeon E5s, and similarly has a ring interconnect that lashes together the cores, caches, and other elements of the processor.
A Poulson chip has a total of 54MB of SRAM memory: 32MB of L3 cache (broken up into eight blocks, with 4MB for each core), 2MB of total L2 data cache, 4MB of total L2 instruction cache, 2.2MB of directory cache (two chunks), 3.6MB of last level tags, and 169KB of L2 instruction tags. (Intel sometimes calls L2 cache "mid-level cache.")
Each Poulson core has 16KB of L1 data cache and 16KB of L1 instruction cache. All of the caches have ECC scrubbing. The core itself has six arithmetic logic units, two integer units, two floating point units, two memory units, and three branch units that are distributed across twelve ports.
At the very center of the chip is a ten-port crossbar router, which manages memory and I/O across the chip, and significantly links the two half-QPI links at the bottom of the chip to the four QPI links at the bottom.
The links at the top are used to create servers with two or four sockets, and the two half-links at the bottom are used to create glueless eight-socket machines. They could also be extended to support SMP or NUMA processing in conjunction with another chipset (such as a modified HP sx3000 chipset) to make even larger shared memory configurations.
A half-QPI link on Poulson will deliver 3.2GT/sec of bandwidth, compared to a full port on the Itanium 9300 that comes in at 4.8GT/sec; the full Poulson links at the top of the chip run at 6.4GT/sec. You get an aggregate of 45GB/sec of bandwidth out of those SMI memory ports and 128GB/sec out of those combined QPI ports; the L3 cache ring has 700GB/sec of bandwidth.
El Reg updated you on the Poulson chips' much-improved threading model last August, as well as their much better use of the transistor budget. The Poulson core has 89 million transistors – fewer than the 109 million in the "Tukwila" core used in the Itanium 9300s – and occupies less than a third of the area. At the same time, it maintains application compatibility while doubling the instruction pipeline width to 12 instructions.
That's what we already knew about what we now know will be called the Itanium 9500 series, and it is a lot. We now know there will be four Poulson Itaniums: The 9520, 9540, 9550, and 9560. The manual does not supply the model numbers, clock speeds, activated L3 cache sizes, or prices, though it does explain lots about the inner workings of the chip.
Still, the roadmap watchers over at CPU World think they know more. They spotted four chips with just those names in an Intel Product Change Notification document, which has since been scrubbed of the Itanium 9500 data.
The Itanium 9300 processors, launched in February 2010 came in a two-core version that ran at 1.6GHz and a four-core version that ran at between 1.33GHz and 1.73GHz. (Turbo Boost can push those cores higher, even there is enough thermal room.) If the data that CPU World stumbled upon is right, then Poulson clock speeds will range from 1.73GHz to 2.53GHz.
That is a a very big bump in processing speed, ranging from 30.1 to 46.2 per cent over the Tukwilas and a lot more than the 20 per cent or so we were expecting. If these are the real SKUs and processing speeds, that is certainly something that HP and Intel will eventually be crowing about.
The Poulson chips are expected to be launched sometime this year, and they are probably in production right now. It would be a fair guess that Intel plans to launch them at the Intel Developer Forum in San Francisco in early September. ®
