This article is more than 1 year old
Teradata forges upgraded Aster, data warehouse appliances
Smell the new Xeon E5 iron and unified data environment
Data warehousing and analytics pioneer Teradata has managed to keep rivals IBM, Oracle, and EMC/Greenplum at bay through product evolution and acquisitions, and is taking the wraps off upgraded versions of its eponymous data warehouse and Aster analytics appliance to keep its share of the big data turf it helped plant decades ago.
The company is launching a new version of its Big Analytics Appliance based on the Aster hybrid row/column parallel database that Teradata acquired back in March 2011 for $263m and previewing the Data Warehouse 2700 Appliance, which is a more traditional query cruncher using the Teradata clustered database.
The Aster database is designed for a number of different purposes, but generally is aimed at handling unstructured data and doing complex queries very fast so managers, while the Teradata database is designed to hold massive amounts of data and do thousands of queries at the same time across that data. Both Aster and Teradata databases give business managers something to do with their time – wait for queries to process – and a sense that they know what is going on.
The new Aster appliance is shipping now, while the upgraded Teradata appliance will ship in the first quarter. Both are based on Intel's latest "Sandy Bridge" Xeon E5 processors and as usual, Teradata is using an OEM supplier to give it the server nodes for its clusters.
In recent years, Teradata and Aster both used Dell PowerEdge iron, but the company doesn't like to talk about its suppliers and Scott Gnau, president of the Teradata Labs division that designs the company's hardware and software, would not spill the beans to El Reg on what nodes Teradata is using this time around.
The Aster Big Analytics Appliance can run version 5 or higher of the Aster database, which was formerly known as nCluster and which was notable in that it had its 50 of its own SQL-MapReduce functions to chew on unstructured data with SQL instructions. It can also run Hadoop side-by-side with Aster, in this case the Hortonworks Data Platform 1.1 release.
In fact, you can also slip out the Hadoop Distributed File System (HDFS) and not tell Hadoop and let Aster hold the data if you want, or you can use a new feature called SQL-H to query unstructured data in either HDFS or Aster data stores.
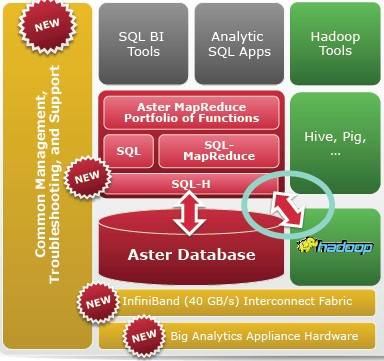
How the Aster appliance bits hook together
The new machine is an update to the Aster MapReduce Appliance launched in November 2011 using Xeon 5600 processors from Intel and sporting 10 Gigabit Ethernet links between the server nodes. That appliance shipped in the first quarter of this year.
With the new cluster appliance for Aster, Teradata is shifting to 40Gb/sec (QDR) InfiniBand switches and adapters on the server nodes from Mellanox Technology, which will significantly reduce latencies and boost the bandwidth between the server nodes. There are two styles of nodes that are deployed in the new Aster appliance, and they reflect the different needs of Aster queen or worker nodes and Hadoop master and data nodes.
The Aster database has the notion of a queen node, which tells worker nodes what to do, but unlike real bee hives, the Aster database can have multiple queens for failover and scalability. Hadoop has a single master node, called the NameNode dispatching work to data nodes, and that master node is something of a bottle neck and a single point of failure.

The Aster Big Analytics Appliance
The Aster queen and worker nodes and the Hadoop NameNode are all based on two-socket rack servers using eight-core Xeon E5-2670 running at 2.6GHz. The Aster backup and loader nodes and Hadoop data nodes use six-core Xeon E5-2620 processors running at a mere 2GHz (and which cost a quarter of the price). Memory configurations are not given for the Aster appliance nodes.
The servers use 900GB disks in the Aster queen and worker nodes and 3TB drives in the Hadoop data nodes and Aster backup nodes. A full cabinet running the Aster database has two queen nodes and sixteen worker nodes with 88TB of raw user space and 264GB with the typical 3:1 data compression that Teradata sees on customer data.
Each expansion cabinet that hangs off the queen nodes has eight worker nodes, for an additional 99TB of user space (297TB with compression), and you can add multiple cabinets and fatter Mellanox InfiniBand switches to scale up to multiple petabytes of database space.
The Aster nodes are loaded up with the 64-bit version of SUSE Linux Enterprise Server 11 SP2 as well as the Teradata Viewpoint management console and system management and administration tools, which are common to Aster database clusters and Teradata data warehouses.
There isn't a lot of data on how these things performance, but the Teradata spec sheet says that it can be up to 35X faster than raw Apache Hadoop at doing SQL and MapReduce work. Pricing for the Aster appliance was not announced.
In addition to the new Aster hardware appliance, Teradata is rolling out a virtual appliance for tire kickers that packages up a queen node and a worker node inside of VMware Player virtual machines as a test baby cluster, if you can call a single worker node a cluster.
This includes a fully functional version of the Aster 5 database, including all of the integrated MapReduce functions in the Aster database. By putting them in VMware Player format, these Aster images can be loaded on a test laptop for experimentation. You cannot use this Aster Express software in production.
New look and new guts for data warehouses
Over on the Teradata data warehouse side, the server nodes are also getting a Xeon E5 refresh and a shiny new cabinet that looks a bit different from the distinctive Teradata racks that have been around for years. (You won't be able to tell so easily that Apple is using them in its data center, we guess.)

The Data Warehouse 2700 SQL query cruncher
Teradata's spec sheets are a bit light on the configuration details for the Data Warehouse Appliance 2700, but it is based on two-socket server nodes using eight-core Xeon E5-2670 running at 2.6GHz and is an upgrade from the Data Warehouse Appliance 2690 announced last October using Xeon 5600 processors and SUSE Linux Enterprise Server 10 SP3.
As with the prior machine, the new 2700 series appliances uses Teradata's Bytnet clustering software running atop Ethernet to lash multiple nodes together. They also support SUSE Linux Enterprise Server 11 SP2 as an option on the machines, if you want to get all of your boxes on the same release.
Depending on the disks you choose (300GB, 600GB, or 900GB), the Data Warehouse Appliance 2700 scales from a low of 6.8TB of user space in a quarter cabinet using 300GB disks to 82.3TB of user space in a full cabinet using 900GB disks. If you buy some extra switches, you can daisy chain 20 racks together to push the database capacity across a cluster up to 1.5 petabytes of user space.
Once again, there is not much in the way of performance data available for the Data Warehouse Appliance 2700, buy Gnau says that the query performance, rack for rack, is about twice that of the prior 2690 appliance, and that the new box can load data about four times faster.
The Teradata clustered database is also getting some tweaks, with the workload manager being more granular and more deterministic, allowing, as Gnau put it, "for mere mortals to deliver quality of service for queries." There is a new set of SmartLoader tools to slurp data from third party sources into Teradata 14, and a new cut-down, virtualized version of a Teradata cluster called Teradata Virtual Machine Edition that is aimed at tire kickers and experimenters.
Uniting Aster, Teradata, and Hadoop
What Teradata really wants to talk about more than iron is how its software is integrating the disparate Aster, Teradata, and Hadoop platforms together into a big data masher and muncher.
The idea is to use Hadoop to capture, store, and refine incoming unstructured data (telemetry from web sites and retail sites and third party data sources) and then have that data accessible for crunching alongside operational data in the Aster and Teradata databases. Aster is where you find the useful nuggets using intense analytics, and Teradata is where you do the ba-zillions of operational queries you need to run the biz.
To that end, Aster appliances are now integrated into the Viewpoint management console, and Hadoop will be integrated in early 2013, says Gnau. Teradata is also rolling out a new Connector for Hadoop program, which will allow for copying and accessing of data between Teradata and Hadoop systems as well as periodic bulk and batch loading and continuous loading if you need more immediate analysis on data. This connector is available now for the open source Apache Hadoop and the Cloudera CDH4 distro and will be available later in the fourth quarter for Hortonworks HDP 1.1. ®
