This article is more than 1 year old
Cisco tames Hadoop with Tidal workload control freak
Forges big-data bundles on UCS iron
Hadoop World Everybody is trying to make a buck or two on Hadoop big-data munching, and Cisco Systems is no exception. It's trying to get the jump on others by making its Hadoop World announcements just as people are arriving at this week's New York event and figuring out what to do after all the yammering is done.
Cisco is making two announcements related to Hadoop this week, one regarding its Tidal Enterprise Scheduler workload manager and the other concerning its "California" Unified Computing System converged server-storage-networking platforms. Both aim to give Cisco's fast-growing systems biz a chance to take a bigger bite out of the Hadoop market.
The box counters at IDC reckon that the global big-data market – including hardware, software, and services revenues from data warehousing, data marts, and analytics clusters like Hadoop – will grow at a compound annual growth rate of 40 per cent from the $3.2bn in 2010 to hit $16.9bn in 2015. Within that big-data market, Hadoopery stuff is growing at a 60 per cent rate over the same term.
Greenfield cloud installations where companies are trying to modernize their networking and servers have been a big driver for the UCS business, and Cisco no doubt wants to make a repeat in the Hadoop sector, with MapReduce and various file systems and data stores, generally open source, being a kind of greenfield alternative to more traditional clustered data warehouses.
It may not seem like it, but we're still in the early days of Hadoop at commercial enterprises, says Wayne Greene, director of product management for cloud and system management at Cisco. "There's a journey toward enterprise-wide Hadoop operations," Greene tells El Reg, after companies start out with a science project or two where they plunk in a baby Hadoop cluster with a modest number of nodes, experiment with a few different data sources, and then succeed in solving particular (and usually modest) business problems.
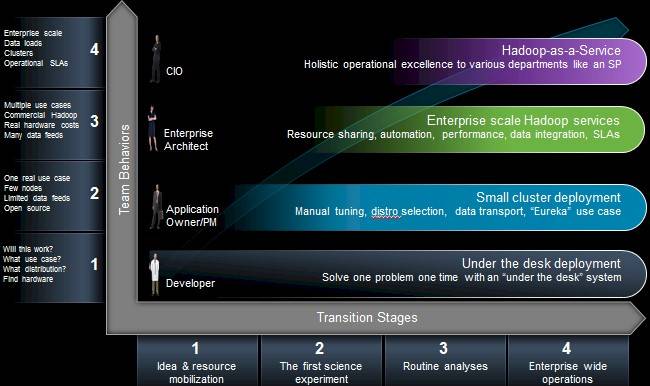
Hadoop use evolves along IT normal trends for any new tech
But at some point you grow up – and before you know it you have multiple Hadoop clusters scattered around, an even larger number of applications dependent on it, and you need to consolidate those clusters and get proper workload management running on them to keep the Hadoop jobs playing nicely on a smaller number of clusters that are shared by the business units.
"Companies will ultimately get to a 1,000-node cluster and it will have to be managed and controlled centrally, not by individual departments," says Greene.
This is where Tidal Enterprise Scheduler, which can manage as many as 30,000 to 40,000 workload jobs a month, comes in.
Cisco got into the server racket back in early 2009, and very quickly figured out that it would need to either partner for a diverse system-management stack for the UCS iron, as it did with VMware for hypervisors, BMC Software for BladeLogic some operating system application management, and the usual suspects for Windows and Linux operating systems. Alternatively, it could create or acquire its own software.
For a company that doesn't think acquisitions pan out most of the time, Cisco certainly has been acquisitive over the years, so it is important to watch what CEO John Chambers does rather than what he says. And so it was not any surprise at all when only a month after the UCS systems were launched Cisco shelled out $105m to acquire Tidal Software, which made its own family of job scheduling, application performance management, and IT process automation tools known as Intersperse.
Now knows as Tidal Enterprise Scheduler, the Intersperse tools basically weave their way into every aspect of modern systems, managing data interchanges such as dropboxes, FTP servers, and various feeds; wrapping around ERP software and their databases; and doing extra/test/load jobs to and from production databases and data warehouses – and now, with support for Hadoop, big data munchers.
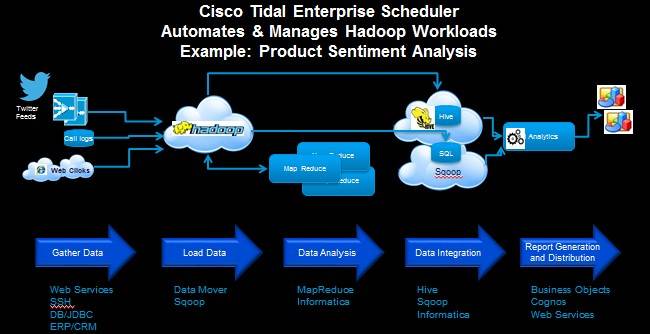
Wrapping Tidal Enterprise Scheduler around Hadoop
With the Tidal Enterprise Scheduler 6.1 release, the workload manager can step in and control-freak the MapReduce computational layer in Hadoop, working through its API stack, as well as reach into the Hadoop Distributed File System that underpins the open source implementation of the big data muncher. It can also reach in and control the Hive SQL-like query layer for Hadoop and the Sqoop bulk data transfer tool, which allows you to pump huge amounts of data in bulk mode into HDFS and then pump it back out again to other systems for further analysis or report generation.
The 6.1 release announced on Monday also has hooks into the Amazon Web Services EC2 compute and S3 storage clouds, and has support for managing the workload control freak from iPhones and iPads now, as well.
Tidal Enterprise Scheduler has been certified against the commercial Hadoops from Cloudera, MapR Technologies, and EMC/Greenplum, and will also work with the open source Apache Hadoop. Presumably a certification for Hortonworks is in the works. The scheduler is priced based on the number of target machines running any particular application, and a 16-node bundle for Hadoop clusters will run around $16,000.
Speaking of bundles, Cisco has Hadoop hardware bundles aimed at big data, based on its UCS C Series rack-mounted servers and top-of-rack Nexus 5000 series switches. Here's the lineup:

Cisco's UCS big data system bundles (click to enlarge)
You can't use B Series blade servers to run Hadoop because they don't have enough local storage with one or two disk drives. The C Series configurations come in a full-rack, high-capacity setup; a full-rack high-performance setup; and a half-rack, high-performance setup. The high-performance versions have 256GB per node instead of 128GB, and use two dozen 1TB disks per node spinning at 7.2K RPM instead of a dozen 3TB drives spinning at the same speed to provide more memory and more spindles per unit of capacity to make Hadoop run faster. The high-performance, half-rack drops in faster processors and even skinnier 600GB 10K RPM SAS drives to push performance even further.
The Cloudera, MapR, and Greenplum Hadoops are certified to run on the big-data hardware bundles. Pricing was not divulged for the hardware bundles. ®
