This article is more than 1 year old
MapR simplifies and extends HBase for Hadoop
And clones Google's Dremel to drill into big data
Hadoop World Back before the Hadoop Distributed File System (HDFS) came out of stealth mode in May 2011, Hadoop distie MapR Technologies didn't like the way it worked, so it rejigged it to look more like a Unix file system from the outside and beefed up its availability.
Now, MapR is taking aim at Hadoop's HBase distributed database layer, which allows customers to run SQL queries against information pumped into HDFS.
Google creates: the open source community imitates, iterates, innovates, and commercializes. That has been the pattern time and time again in Big Data, and so it is with Hadoop's MapReduce and HDFS, which are based on ideas embodied in Google's own MapReduce and Google File System (GFS). GFS was created for its search engine indexing many years ago and mimicked by Yahoo! to create Hadoop and HDFS. Google then added a distribute database table layer called BigTable, and the open source community – led by Powerset and championed by Facebook – created HBase.
With the first iteration of its products, MapR took the append-only architecture of HDFS and made it readable and writable in a random fashion and gave it a Network File System mount, which is a very clever piece of software engineering and one that MapR has decided to keep closed source. The company also provided high availability for the Hadoop NameNode, the part of HDFS that acts like a file allocation table in your disk drive, remembering where all the data is, and that is a single point of failure in Apache Hadoop. MapR has also created a multi-node implementation of Hadoop's JobTracker, which distributes computational work around to data chunks scattered around the Hadoop cluster.
Based on surveys of the customer base done by MapR, which uses EMC/Greenplum as its main distributor for its Hadoop stack, 45 per cent of Hadoop shops use HBase in production for at least some query jobs. "HBase has got a lot of momentum," says Jack Norris, vice president of marketing at MapR, tells El Reg. "It has great scale, it leverages Hadoop, and it has a good consistency model compared to Cassandra and other options, which eventually get to consistency."
Cassandra is the database layer that Facebook eventually created because of issues it was having with HBase, and keeping data absolutely consistent across the Hadoop cluster at any given time was something Facebook was willing to sacrifice for scalability and performance. That's something you might do when you have nearly 1 billion users and the data is some smart-alec comment someone makes about a cat, but when you are using Hadoop to do risk analysis at a bank, eventual consistency is probably not an appealing idea.
Just like there were a lot of issues with HDFS, there are a lot of issues with HBase, and MapR has been at work tweaking the underlying HDFS file system and how HBase works with it to make it better. HBase initially writes data to memory for speed, but every now and then this data has to be pushed to disk in a file, called an HFile, where it cannot be altered. However, HBase does do an operation called compaction, which merges the HFiles on disk.
HBase also has a control freak called a RegionServer, which runs on each node in the Hadoop cluster, and which pumps incoming database information into a write-ahead log (WAL) and then puts it into memory. (This is so the data is kept and retrievable in the event of a node crash.) These compactions and RegionServers eat a lot of resources, and recovering a RegionServer after a crash, which involves replaying the WALs into memory, can take 30 minutes or more.
The key thing that MapR has done in its latest tweak of its Hadoop code is get rid of compactions and RegionServers.
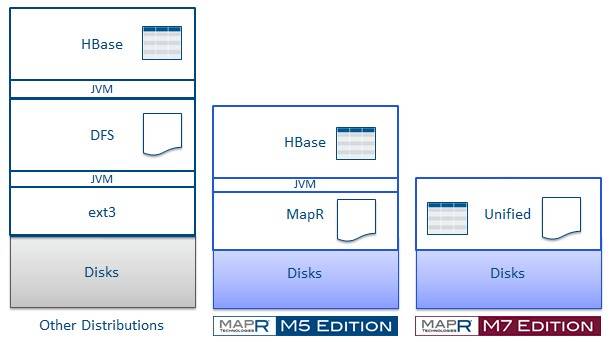
Apache Hadoop versus MapR M5 and M7
"When I tell customers we can eliminate compactions and RegionServers to HBase users, they stand up and applaud," says Norris, adding that I/O storms in the cluster can also slow down HBase performance, stalling the updating of tables, and there is a lot of manual tweaking Hadoop admins have to do to split and merge tables and backing up or renaming tables is a pain in the neck.
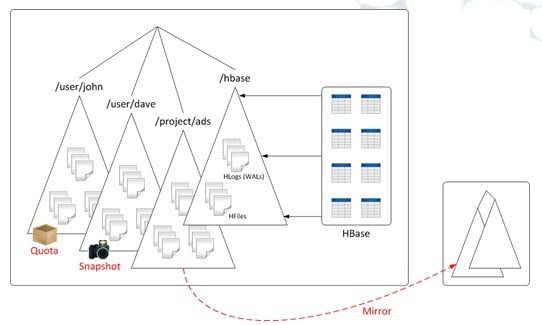
How HBase works on MapR M5 Edition
With the MapR M5 Edition of the Hadoop stack, the company basically pushed HDFS down into a distributed NFS file system, supporting all of the APIs of HDFS and with MapR M7 Edition, the file system can not only handle small chunks of data but also small pieces of HBase tables. This eliminates some layers of Java virtualization, and the way that MapR has implemented its code, all of the HBase APIs are supported so applications that whack HBase don't know they are using MapR's file system.
On that earlier M5 Edition, HBase tables and logs (Write Ahead Logs) are stored in one part of the system and data chunks in HDFS are stored in another part of the system, just like in any other Hadoop stack. What this means is that you have limited data management options on the HBase tables and you also can't do snapshots and backups of the data as you can with chunks of data in the MapR HDFS-alike file system. You can't mirror HBase data either.
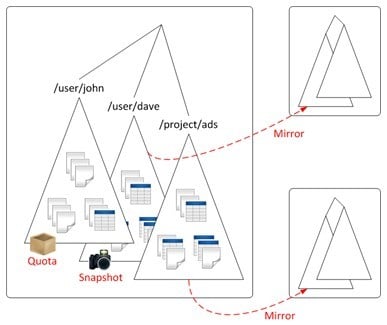
How HBase works on MapR M7 Edition
With MapR M7 Edition, the unstructured data in the HDFS-alike part of the file system and the HBase-alike tables of the file system can be interwoven, so the tables and their underlying data files can be grouped together, snapshotted together, and backed up to mirrors together.
Moreover, with the real HBase, RegionServers can only handle somewhere between 100 and 200 regions per server, or about 2TB of HBase data, and so on a modern x86 server with a dozen 3TB disk drives, most of the capacity can't be used. Those RegionServer limits also mean that a single cluster has trouble handling several hundred tables at the same time. The MapR file system doesn't use RegionServers to support HBase tables, so it doesn't have any of these limits.
The M7 Edition allows for HBase databases to have more than 1 trillion tables and allows for 20 times the number of columns as Apache HBase supports. Row and cell sizes in MapR's HBase-alike have also been boosted to handle larger objects.
The tweaked MapR file system has been in a private beta test with three customers, and based on that experience MapR is telling future customers that it expects to be able to offer at least twice as fast performance on HBase queries (generally written in the Hive variant of SQL) compared to the open source Apache Hadoop plus HDFS and HBase.
MapR is opening up the code for customers to participate in a wider public beta for its implementation of this improved HBase support. General availability of the M7 Edition is expected sometime in the first quarter of next year. MapR M5 Edition cost $4,000 per node, and MapR has not yet set pricing on the M7 Edition.
Drill, baby, Drill
MapR is also talking up its Apache Drill project, which is an interactive analysis engine that rides atop HDFS or HBase and that is akin to the BigQuery service that is in beta over at Google and that is based on Google's Dremel tool, which is now two years old. Drill uses a variant of SQL called DrQL, which is compatible with the BigQuery service.
Both the BigQuery service and the Drill layer on top of HDFS and HBase are intended to allow for interactive analysis of data stored in Avro, JSON, and protocol buffer formats allowing for the querying of information ranging from gigabytes to petabytes in from milliseconds to minutes and to display it in some useful fashion. The idea is to use Drill in situations where latency matters, such as in the creation of real-time dashboards or doing event detection and trend analysis on the fly such as for network intrusion, fraud detection, and failure analysis in systems.
Norris says that MapR expects for Drill to be production ready maybe late in the fourth quarter, and says that he expects that eventually all Hadoop releases will include Drill, which could be rolled into the M7 Edition Hadoop stack in the first quarter of next year. No promises. ®
