This article is more than 1 year old
Intel Xeon Phi battles GPUs, defends x86 in supercomputers
A hoard of wimpy Pentium cores do the math for brawny Xeons
SC12 Intel's Xeon Phi might have started out with the goal of creating an x86-based graphics engine, but it ended up defending the x86 architecture's hegemony in high-performance computing against the onslaught of GPU coprocessors from Nvidia and AMD.
However, it ends up being a battle among GPUs anyway – but in a different market than Intel, Nvidia, or AMD might have thought it would be, seven years ago.
That's when John Hengeveld, now director of marketing for Intel's high-performance computing group, was a company strategist envisioning an increasingly parallel world, one that would need access to calculations that cost less money and burned less electricity.
"We've been hard at work on this for a very long time," Hengeveld told El Reg ahead of this week's launch of the first two Xeon Phi coprocessor cards at the SC12 supercomputing event in Salt Lake City.
From its not-so-humble beginnings as the ill-fated "Larrabee" GPU processor, the Xeon Phi evolved into what is essentially a parallel x86 supercomputer on a chip. And after talking about this "Many Integrated Core" architecture for years, the first two Xeon Phi coprocessor cards are finally here, ready to do battle with Nvidia's Tesla GPU coprocessors and to a lesser extent AMD's FirePro graphics cards.
We say to a lesser extent not because of the technology that AMD has, but rather because of the attitude that it does not have. AMD can deliver a GPU coprocessor that can crank the flops, but the company seems unfocused, not concentrating on getting its GPU accelerators into HPC systems.
AMD lost the processor slot to Intel at Cray with the new "Cascade" XC30 supers, and didn't even seem to try to get the GPU accelerator slot in the systems. And that's a shame because this market needs all three competitors working on CPU and GPU designs to keep everyone honest and hardworking.
El Reg has spent years going over the slowly revealed architecture of the Xeon Phi coprocessors, and we're not going to repeat that history now. But with Monday's announcement, a couple of things are cleared up.
First of all, if you count carefully in the die shot below, the "Knights Corner" chip that's the first usable member of the Xeon Phi chip family has 62 cores. Those cores are based on a heavily customized Pentium-54C core that has four threads, 32KB of L1 instruction cache and 32KB of data cache, plus a 512KB L2 cache.
It also includes a shiny new vector processing unit that thinks in 512-bit SIMD instructions instead of the 128-bit or 256-bit AVX instructions in Xeon chips. This VPU is capable of processing eight 64-bit double-precision floating point operations or sixteen 32-bit single-precision operations in one clock cycle.

The 62-core Xeon Phi coprocessor
(click to enlarge)
El Reg had guessed it would have 64 cores, in keeping with a good clean base-two number, but that's not how it played out. Based on thin performance data from last year, we estimated that it might have 54 working cores running at somewhere between 1.2GHz and 1.6GHz. As it turns out, however, the yields are a bit better on that 22-nanometer Tri-Gate process Intel is using to etch "Ivy Bridge" and Xeon Phi processors, and that means it can use more of the cores on the die and not have to run them at such a high clock speed. This is important because every incremental bump in clock speed creates an increasingly larger jump in heat until the magic blue smoke that allows all computing escapes from the chip.
As it turns out, Intel is bringing two different Xeon Phi chips to market. One has 60 of the 62 cores fired up and spinning at 1.053GHz, while the other has 57 cores activated and runs at a marginally higher clock speed of 1.1GHz to deliver almost as much raw double-precision performance.
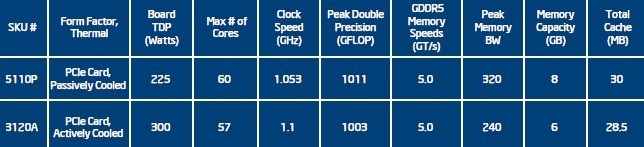
Intel does one Xeon Phi card with a cooling fan, and another without
The Xeon Phi 3120A PCIe card is an actively cooled device – it has a fan embedded in it like a graphics card for a workstation. This one uses the 57-core, 1.1GHz Xeon Phi that has 28.5MB of cache memory on the chip plus 6GB of GDDR5 graphics memory for the Xeon Phi to use as its workspace, and 240GB/sec of peak memory bandwidth coming into or going out of that memory.
Add it all up, and this card can do a tiny bit over 1 teraflops of double-precision floating point math, which is what it needs to be competitive with Nvidia's new K20 and K20X GPU accelerators. But it also dissipates 300 watts, which will make it hot for many workstations, and too hot for some dense-packed servers.

The PCI card housing a Xeon Phi coprocessor
If you want to weave Xeon Phis into your supercomputers for number-crunching offload, then you probably will want the passively cooled Xeon Phi 5110P PCIe card. This one has more cores fired up and a slightly slower clock speed, and can deliver its 1.01 teraflops within a 225-watt power envelope – the same thermal limit that other GPU coprocessors for servers need to stay within. The 5110P card has the Xeon Phi chip with 60 cores, 30MB of cache memory on the die, plus 8GB of GDDR5 memory and a peak of 320GB/sec of memory bandwidth.
This 5110P card is what the University of Texas is using in its "Stampede" supercomputer, which ranked number five on the latest edition of the Top500 supercomputer rankings. Intel and Dell, which built the machine, were cagey about the configuration because the Top500 list came out ahead of the Xeon Phi launch, but we now know that Stampede has 1,875 Xeon Phi cards in its current 5,775 server nodes, and there is obviously lots of room for expansion with the coprocessors. The plan is to scale up Stampede with over 100,000 Xeon cores and nearly 500,000 Xeon Phi cores in early 2013 to deliver up to 10 petaflops of peak theoretical performance. Around 8.4 petaflops of that oomph will come from the Xeon Phi coprocessors.
Generally speaking, Intel says the 3100 series of the Xeon Phi chips, as the family is fleshed out, will be aimed at compute-bound workloads such as Monte Carlo and Black-Sholes financial simulations and life sciences simulations, while the 5100 series will be best for digital content creation, seismic processing, and other memory-intensive workloads.
Unlike Nvidia, which is cagey about pricing for its Tesla GPU coprocessors, Intel is doing (to its credit) what it always does: putting a price tag on the cards. The passively cooled Xeon Phi 5110P is shipping for revenue at Intel now, and will be generally available on January 28 to the rest of us for $2,649. The actively cooled Xeon Phi 3120A card, which is hotter and yet has less memory and bandwidth, will be available sometime in the first half of 2013 with a price that is expected to be around $2,000.
What's the performance bump?
This being so early in the game for x86 and GPU accelerators andthe high-end Tesla K20 and K20X coprocessors just being announced Monday morning at SC12, Intel is not going to take aim directly at the Tesla GPUs in terms of performance. (It will soon, fear not.)
For now, Intel is happy to talk about how the programming model for the Xeon Phi chips give it an advantage over GPU accelerators – something Nvidia and AMD would argue with – and show how the addition of Xeon Phi cards to servers can accelerate performance.

How Intel compares Xeons, GPU accelerators, and Xeon Phis
Intel has been banging the instruction-set drum for the better part of five years, when it first began talking about Larrabee GPU chips and then what evolved into the Xeon Phi coprocessors, and about having both the CPUs and x86 accelerators use the same instruction set. Intel also makes much of the fact that the Xeon Phi chips run Linux and an OpenMP multiprocessing as well as the message passing interface (MPI) protocol, allowing for the machines to run code with relatively modest modifications that had been running on parallel x86 clusters.
Intel's C, C++, and Fortran compilers in its Parallel Studio XE set as well as the Cluster Studio XE extensions work on Xeon Phi chips. You add parallel directives to the code, and you compile the code to run on both x86 chips in standalone mode and on the x86-Xeon Phi combination. You get one set of compiled code, and if the Xeon Phi chips are present, the work is offloaded from the server CPUs to the x86 coprocessors, and they do the acceleration. If not, the CPUs in the cluster or the workstation do the math.
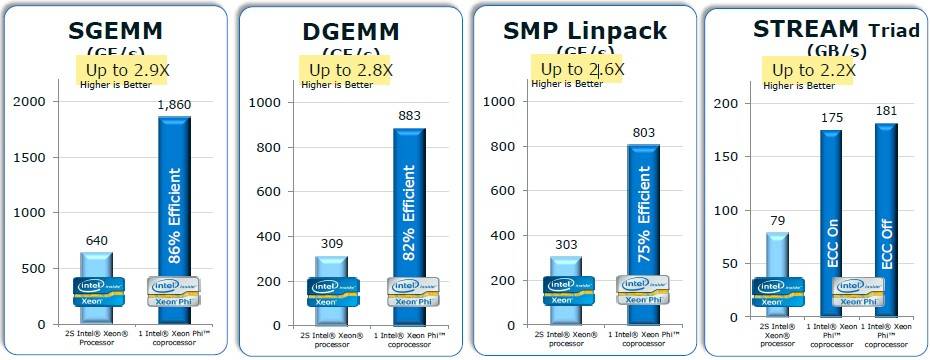
Relative performance of Xeon CPUs goosed by Xeon Phi coprocessors (click to enlarge)
In general, on a server with two Xeon E5-2670 processors, adding a single Xeon Phi card can boost the performance of various HPC workloads by between a factor of 2.2 to 2.9, according to Hengeveld. In the benchmark tests shown above, Intel is using an early release Xeon Phi card called the SE10P that had 61 working cores and a peak of 1.07 teraflops. So the speed-up on these tests is a bit better than what you will see with the production Xeon Phi 5110P cards.
The efficiency of the Xeon Phi in terms of how much work it did compared to its theoretical peak is perhaps the most important part of the chart above. On the SGEMM single-precision matrix math test, it was 86 per cent of peak, and on the DGEMM double-precision matrix math test, 82 per cent of the oomph was used on the workload. The Linpack Fortran vector and matrix math test fell to 75 per cent on this single-node setup, but that's respectable even if it is not earth-shattering. (Those three tests are showing gigaflops of floating point oomph.The Stream test shows GB/sec of bandwidth running the Triad set.)
Intel has not yet demonstrated how multiple Xeon Phi cards per server can boost performance, and how multiples of these nodes can be lashed together with InfiniBand or Ethernet networks to further scale performance. That is coming, for sure – particularly when Cray puts the Xeon Phi cards inside the new Xeon E5-based XC30 supercomputer using its "Aries" interconnect.
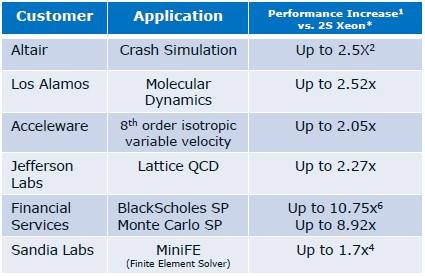
Customers are seeing big performance gains from Xeon Phi coprocessors
Intel has trotted out the speed-up that various supercomputer labs and application software suppliers are seeing as they extend their code to support Xeon Phi coprocessors, and they are showing anywhere from a 1.7X to 2.52X speedup, depending on the server configuration and application. ®
