This article is more than 1 year old
SGI UV 2000 supers are Intel and Nvidia inside
Cheap flops flip bits in shared memory super and rackers
Supercomputer makers used to stuffing processors and networks into machines to build clusters or shared memory systems have to adapt their machines to take advantage of various kinds of compute accelerators that offers cheaper flops, and Silicon Graphics is no exception.
To that end, the company has reworked its high-end UV 2000 shared memory supers and its Rackable hyperscale machines to borg the latest Intel Xeon Phi and Nvidia Tesla coprocessors.
SGI has been good about absorbing accelerators and other kinds of processors into its machines, and this is not the first time SGI has gone off the beaten x86 cluster path. Two years ago, at the SC10 supercomputing conference, SGI rolled out the "Project Mojo" Prism XL hybrid CPU-GPU clusters, which had a server sled that could host as many as four GPU coprocessors or Tilera Tile64Pro accelerators for deep packet inspection and other network workloads hanging off Opteron 4100 processors.
The Mojo design put InfiniBand clustering and Ethernet management switching in a center rack and put a rack of the Mojo blades (which SGI called sticks) into two racks, one on each side. The whole shebang could hold 500 single-wide GPUs and 126 single-socket Opteron 4100s driving them.
The system was designed to scale up to 36 cabinets and around 14 petaflops using AMD 9370 or Nvidia M2050 GPU coprocessors and burning somewhere around 50 to 60 kilowatts per compute rack.
Obviously, if you moved to Xeon Phi or Tesla K20 accelerators in this machine, you could cram a lot of compute into a compact space. For the three-rack base Prism XL system, it would be on the order of 505 teraflops peak theoretical double-precision floating point in a three-rack configuration using the Xeon Phi 5110P passively cooled x86-based coprocessor from Intel, and around 655 teraflops peak DP for the top-end Tesla K20 GPU coprocessor from Nvidia.
The Prism XL machines are still being sold, Bill Mannel, vice president of product marketing at SGI, tells El Reg, but they were not part of the accelerator love-in at the SC12 supercomputer conference last week.
Instead, SGI focused on getting the latest coprocessors from Intel and Nvidia into its UV 2000 "big brain" shared memory supercomputer, which marries SGI's NUMALink 6 interconnect with Intel's Xeon E5-4600 processors to create a shared memory system. SGI also rolled out support for the two classes of coprocessors in its Rackable systems rack machines, and rolled up some preconfigured ceepie-geepie starter kits as well.
To add accelerators to the UV 2000 machines, SGI has created a single-socket blade that puts the accelerator and main memory for the CPU on a motherboard and the single Xeon E5-4600 processor on a daughter card that plugs into this motherboard.
This mobo has a full-length, double-wide PCI-Express 3.0 slot and not only does it support the passively cooled Xeon Phi, Tesla K20, and Tesla K20X coprocessors, it will also allow companies to slide in Nvidia's Quadro graphics cards which are actively cooled.

Accelerator nodes for the UV 2000 sporting Xeon Phi and Tesla coprocessors
Initially, SGI is allowing for up to 32 of these accelerator blades to be added to a UV 2000 system. In an all-Xeon setup, the UV 2000 can support a maximum of 256 single-node processors for a total of 2,048 Xeon E5 cores and 64TB of memory. What would be even more interesting is for SGI to push the NUMALink 6 to its full 512-socket theoretical limit and offer a 256 CPU by 256 accelerator configuration.
That 32 accelerator limit is not a hardware limit, Mannel explains, but a software limit and he concurs with El Reg that a more interesting configuration would be 64 Xeon E5s paired with 64 accelerators, but stopped short of making a commitment that this was in the works.
SGI is taking orders for accelerated UV 2000 blades now and will have them generally available in January 2013.
The Rackable side of the house is also getting the Xeon Phi and Tesla K20 and K20X coprocessors in various nodes, thus:
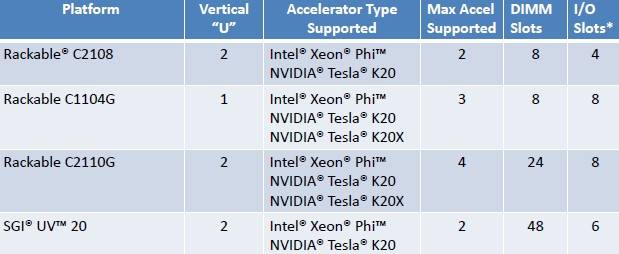
Where SGI is plugging in Xeon Phi and Tesla K20 and K20X accelerators
SGI is offering a ten-node starter kit for hybrid CPU-GPU machines, which are available now. These starter kits take the Rackable C1004G-RP5, which is a 1U Xeon E5 rack server, and puts two accelerators into and uses it as a head node in the cluster.
Another nine of these nodes are added as compute nodes, again with your choice of Xeon Phi or Tesla K20 accelerators. The starter configuration has a 36-port QDR InfiniBand switch to lash the nodes together and a 24-port Gigabit Ethernet switch for node management; both switches come from Mellanox Technologies.
The cluster runs Red Hat Enterprise Linux 6.2 and comes with SGI's Performance Suite and Management Center cluster management tools as well as Altair's PBS Pro preloaded. List price for the starter kit is under $200,000.
The UV 20 four-socket Xeon E5-4600 rack server (which does not have the NUMALink 6 interconnect) can also use the Xeon Phi and Tesla K20 coprocessors, but not the K20X for some reason. ®
