This article is more than 1 year old
Amazon fluffs up cloudy data warehousing service with Redshift
Bezos kicks Teradata, IBM, Oracle, and Greenplum in the ad hocs
re:Invent Amazon Web Services, has used its first re:Invent customer and partner conference in Las Vegas to launch a cloudy data warehousing service dubbed Redshift.
In the opening keynote at re:Invent, Andy Jassy, the Amazon senior vice president in charge of AWS, said that large companies – including Amazon itself, which is the largest consumer of capacity on the AWS cloud as well as running other systems that are not on the cloud – were unhappy with their in-house data warehouses.
"Large companies say it is too expensive and a pain in the butt to manage," explained Jassy. "And small companies are left out in the cold." They simply cannot afford these high-end data warehousing systems, not even cut-down versions that are supposed to be more attractively priced. And they don't have the skills to cobble together their own data warehouses, even using relatively inexpensive Windows and Linux systems as the foundation.
The cloud computing subsidiary of e-tailing giant Amazon has been peddling a relational database service for transaction processing, called Relational Database Service, for years. AWS has more recently added a Hadoop service, called Elastic MapReduce, and a NoSQL data store called, DynamoDB, to handle unstructured "big data." So it is only natural that Bezos & Co would complete the set and launch a data warehousing service, which it did today at its first-ever .
The data warehousing service is called Redshift, and it doesn't mean moving away from IBM and towards Oracle, but rather moving away from both of them and Teradata and Greenplum while you are at it.
A data warehouse is generally a parallel database with a shared-nothing storage architecture that runs on x86 iron, or maybe RISC/Unix gear if you have lots of dough and you don't know what else to do with it. The system is not designed to process online transactions or chew through unstructured data, but to cull through historical transactional data for insights using ad hoc queries to answer hundreds or thousands of questions about relationships in the data.
You could have set up a data warehouse on Amazon's EC2 compute cloud and using its EBS block storage service if you wanted to, just like you have been able to set up and run databases or a Hadoop cluster for years. But Amazon knows that what many companies want is a service where they dump their data, run their algorithms, and get their answers and all they have to do is give AWS some money and it takes care of all the scaling and management.
And thus, the Redshift service will be the next big thing coming out of AWS.
Like other Amazon platform services, Redshift is designed with pay-as-you-go pricing and no upfront costs, which is a stark contrast with any clustered system you might install in your own data center. Redshift is also designed to be easy to provision, grow to a massive scale when necessary, give great performance, do so at a low price, and work in conjunction with popular business analytics tools.
Redshift is in a limited preview right now, so the technical details behind the service are not yet clear. But Jassy said that Amazon has created the service using a columnar table structure, as many old-school data warehouses are now able to do. The columnar data store allows for certain kinds of ad hoc queries to run orders of magnitude faster.
The fact that Jassy's presentation says that the Redshift service also uses PostgreSQL drives to link to third party BI tools would seem to indicate that Amazon has parallelized the open source PostgreSQL database, much as EMC's Greenplum and IBM's Netezza have done for their data warehousing appliances.
While the base open source PostgreSQL database does not support columnar storage, Yahoo! whipped up a columnar variant of PostgreSQL and out it into production more than five years ago, and if Yahoo! can do it, Amazon can, too.
Amazon is using data compression on the server nodes that made up the Redshift clusters on its cloud, which means you can cram more data onto the nodes and queries run faster. AWS is probably sprinkling flash storage in the server nodes to help boost I/O, much as traditional data warehouse appliance makers such as Teradata, IBM, Oracle, and Greenplum have done in recent years. But Jassy did not say.
The combination of columnar storage and compression means that I/O operations on the data warehouse are an order of magnitude faster, and thus queries can finish a lot faster.
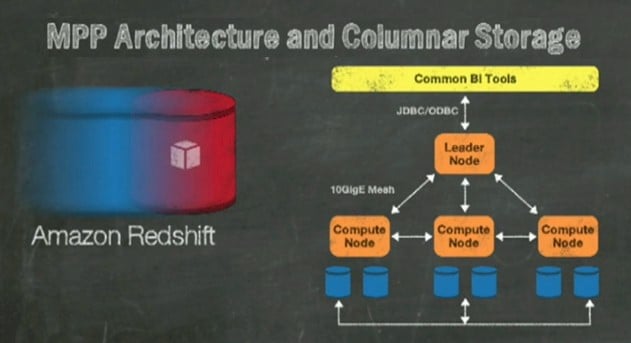
Amazon's Redshift block diagram is fuzzy, but it's thinking isn't
The Redshift service runs on two different types of node, giving you the ability to balance compute and memory against raw disk capacity.
The high storage extras large data warehousing node has two cores with 4.4 EC2 units (ECUs) of performance and 15GB of virtual memory; it has three disk drives with a total of 2TB of capacity and a moderate amount of networking (very likely a slice of a 10GE port) and moderate disk I/O.
For the big Redshift jobs, Amazon also is offering a high storage eight extra large (8XL) data warehousing instance that has 16 virtual cores, 35 ECUs of performance, 128GB of virtual memory, and two dozen disk drives with a combined capacity of 16TB.
You can start with a single small node and scale up to a 32 nodes for a maximum capacity of 64TB, while with the fatter data warehousing nodes you start at two and can scale up to one hundred for a total of 1.6PB of capacity. It doesn't look like you can mix and match node types, but this being Amazon you can no doubt move between node types. It may take some time to move over the data, which is presumably stored locally in each node type.
The parallel columnar database behind the Redshift service speaks the standard SQL query language that all relational databases have to speak (if they want to be heard, anyway) and has JDBC and ODBC hooks out to common business intelligence tools such as those from Jaspersoft, MicroStrategy, IBM (Cognos), and SAP (BusinessObjects).
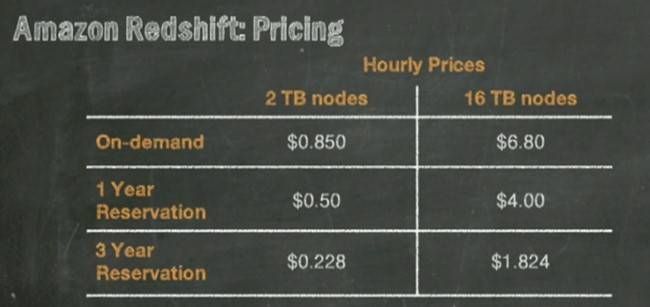
Pricing for the Redshift data warehousing service on AWS
Depending on who you go with, Jassy said that it costs something on the order of $19,000 to $25,000 per TB per year to run an on-premises data warehouse. That's an all-in number, including several database administrators and the hardware, software, and maintenance.
A 13-node 8XL Redshift cluster with heavy utilization using three-year reserved instances costs just under $1,000 per TB. Even assuming that on-premise number is inflated a bit for comparison, that is still a hell of a spread between internal IT ops and what Amazon can do with Redshift.
Being a large retailer, and the largest online store in the world, Amazon knows a thing or two about data warehouses. And so it took a subset of its data – 2 billion rows – and ran six of its most complex queries against it on its internal systems and the Redshift service.
The internal system had 32 nodes, 4.2TB of memory, and 1.6PB of disk capacity and cost "several million dollars," according to Jassy. The data and the queries ran at least ten times faster on a two-node Redshift cluster using the 128GB/16TB fat data warehousing nodes. This cost $3.65 per hour – less than a latte in Seattle – which works out to around $32,000 for an entire year.
"That's pretty game changing," said Jassy. No kidding.
The Redshift data warehousing service is in limited preview right now, with the full service launching in early 2013. ®
