This article is more than 1 year old
Couchbase adds JSON docs, geo replication to NoSQL
Taking on MongoDB in ease of use, scalability
Couchbase, one of the emerging providers of NoSQL databases (or data stores) for modern web applications, is cranking up and pushing out a new release, taking on rival 10gen's MongoDB for the hearts, minds, and money of web startups looking for ways to hold, dice, and slice large amounts of data.
Couchbase is not the same thing is CouchDB, a mistake that a lot of people make, says Couchbase CEO Bob Wiederhold. CouchDB is an Apache-licensed open source database that is coded in Erlang and was created by Damien Katz, who worked on the Lotus Notes/Domino team at IBM, back in 2005. The first stable release came out in the summer of 2010. Couchbase Server is a key-value data store that has its origins in the memcached data caching server, and Couchbase (the company) is the result of the merger of Membase and CouchOne, a commercializer of and contributor of the Apache CouchDB project run by Katz.
Couchbase Server leverages code and ideas from CouchDB, but has ported the Erlang code to C as well as coming up with a slightly different data store. And, interestingly, Katz distanced himself from the CouchDB project to focus on Couchbase Server earlier this year. Katz has been very clear that Couchbase Server should not be thought of as a variant of CouchDB, and Wiederhold reiterates this as Couchbase 2.0 comes out this week. Both CouchDB and Couchbase are available under Apache 2.0 licenses, but only CouchDB is an Apache project; the Apacheness of both and the similarity of the names sometimes leads to confusion to those not among the digerati.
With Couchbase Server 2.0, the key-value store is getting a JSON overlay so it can store and process documents, just like CouchDB already has. The way it works, every JSON doc can have a different record structure and you can store multiple documents with different structures is a common Couchbase data bucket, with the idea of keeping related items close to each other. You can, of course, query all of the fields in a JSON document, just as you would run queries in the key-value store that underpins Couchbase Server.
"We think that adding JSON documents will significantly expand the use cases and market for Couchbase Server," Wiederhold tells El Reg, adding that rival 10gen's MongoDB "hasn't been nearly as strong in terms of reliability and scale, based on the blog comments we see."
The issue is not absolute scalability, in terms of scaling across hundreds or thousands of nodes, but rather how easy – or difficult – it is to scale up a Couchbase or MongoDB data store and how error-proof it is. Because Couchbase uses a hashing algorithm to place documents on the cluster of servers underpinning the database, it distributes data in as dispersed a fashion as possible and without creating hotspots. Also, all nodes in a Couchbase cluster are identical (there's no masters and slaves structure), and that hashing algorithm allows for a new node to be added instantly to a cluster and start receiving data and documents.
Wiederhold says that most customers using Couchbase Server today have 50 or fewer nodes, with some doing 100 nodes or beyond. But the main advantage the database has is that it can give sub-millisecond response times on reads and writes (because of very clever memory and disk caching) while at the same time delivering high throughput. AOL, for instance, uses Couchbase to store over 500 million user profiles, which it uses to figure out what ads to serve them. Such ad serving has to take place in 40 to 50 milliseconds, so reading the database about each user has to take a much smaller amount of time.
Couchbase Server 2.0 includes a number of other features such as distributed indexing and querying, which uses a scatter-gather methodology that is a bit like the Message Passing Interface (MPI) protocol used in supercomputer clusters to distribute number-crunching work across a cluster. The update also has an incremental MapReduce function, which means you only have to re-index the documents that have changed since the prior index was created.
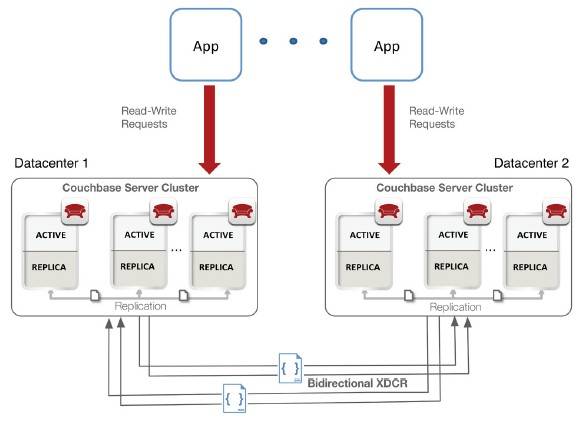
Cross data center replication, or XDCR, for Couchbase Server
The big new features, aside from JSON document support, is what Couchbase is calling cross data center replication, or XDCR for short. This basically extends that hashing algorithm out across the wide area network to remote data centers where backup clusters are running. Couchbase already allows for companies to specify how many replicas of datasets or documents they want to create inside of a single cluster.
This is an active-active cluster approach, and you can decide whether you want to replicate synchronously or asynchronously depending on the WAN latencies you have across the distances between the data centers. By default, the replication pushes changed data from primary nodes out across the WAN to backup nodes, and once it is stored in the memory of the remote node, then that is a commit. If you are more paranoid, you can wait until the data is actually pushed down to the disk before counting it as committed.
Couchbase Server 2.0 comes in a Community Edition, which is free of course, and which is rolled up as object code so you can install it and go. The Enterprise Edition is based on the Community Edition, but adds the latest bug fixes and security patches to the code; these are eventually added to the Community Edition. Enterprise Edition support costs $2,500 per year per node for 8x5 standard support, and $4,500 per node per year for premium 24x7 support.
Couchbase has over 350 customers, ranging from LinkedIn to Orbitz to Starbucks to Experian to Vodaphone. There are over 5,000 nodes at these companies in production at the moment, about half of which run on Amazon Web Services. Couchbase doesn't know precisely how many Community Edition licenses are out there in production, but it is getting tens of thousands of downloads per month. ®
