This article is more than 1 year old
Red Hat has BIG Big Data plans, but won't roll its own Hadoop
Kicks HDFS to the curb and replaces it with GlusterFS
Let's get this straight. Red Hat should package up its own commercial Hadoop distribution or buy one of the three key Hadoop disties before they get too expensive. But don't hold your breath, because Red Hat tells El Reg that neither option is the current plan. Red Hat is going to partner with Hadoop distributors and hope they deploy commercial Hadoop clusters on Red Hat Enterprise Linux and JBoss Java and use the Gluster File System, known now as Red Hat Storage Server 2.0.
Red Hat is hosting a Big Data and open hybrid cloud briefing today, laying out how Red Hat fits into the emerging Big Data arena and how its various products come together to help support workloads like the Hadoop Big Data muncher. Greg Kleiman, director of business strategy for the storage business unit, chatted with El Reg about the possibilities for Red Hat in Big Data while going over what the company is actually announcing today in addition to its overall strategy.
It is natural enough to think that Red hat might commercialize and open-source technology that becomes integral to infrastructure, which is why many believe that Red Hat should offer a complete software stack, including a relational database and a Hadoop muncher for unstructured data, among other things.
Shadowman has grown to rule the commercial Linux roost, and it bought itself a strong position in Java middleware and application development tools when it acquired JBoss. It also gained a pretty good contender for server and PC virtualization when it ate Qumranet to evolve it and create Red Hat Enterprise Virtualization, the commercial-grade KVM hypervisor. It has JBoss Data Grid as its NoSQL data store, which is based on the Infinispan project, as well as a partnership with 10gen for the MongoDB data store.
Red Hat is readying a commercial-grade OpenStack cloud control freak, has created its own OpenShift platform cloud out of myriad open source projects and acquired products, and has a CloudForms overlay to manage hybrid clouds – itself a mash-up of acquired and homegrown code. Similarly, Red Hat snapped up Gluster to get a clustered file system that runs on x86 iron and that can be used to underpin supercomputers, compute clouds, and soon Hadoop MapReduce workloads.
Sometimes, Red Hat is content to ride waves, other times it has to make them. At the moment, Hadoop is a wave that Red Hat is content to surf.
Red Hat's own-brand Hadoop distro?
"We are absolutely not announcing that today," Kleiman said with a laugh when asked if Red Hat would do its own Hadoop distribution. "We considered that, but at the moment we are not pursuing that. We are going to work through the existing Hadoop distributors. We are going to play the field and see what happens."
How boring, unless you are the one sleeping around with Cloudera, Hortonworks, MapR Technologies, and Greenplum and the one who stands to make hundreds of millions of dollars (maybe more) over the next few years getting support contracts for RHEL, JBoss, and Gluster, which was unveiled last summer as Red Hat Storage Server 2.0.
Eventually, Red Hat wants to cloudify your Big Data workloads
Among the many things that makes Hadoop shops cranky are the limitations of the Hadoop Distributed File System (HDFS) that underpins the Hadoop runtime and its MapReduce technique for chewing on chunks of raw data. It has some properties that are not good, one of them being a single point of failure in the NameNode – kind of like a file allocation table for the HDFS cluster that keeps chunks of data spread around the server cluster in at least triplicates for performance and redundancy reasons.
The JobTracker, another key element of Hadoop, is really at the heart of the system and it tells what compute jobs should be spread out over the cluster to chew on particular data sets. (The genius of Hadoop, aside from coping with high volumes of unstructured data, is that it moves compute jobs to the storage for execution rather than trying to move data sets off disk arrays to compute nodes. You send little routines out to big blocks of data, which is a hell of a lot faster.)
The Apache Hadoop project has gutted this NameNode architecture with Apache Hadoop 2.X, and with its CDH4 release, announced in June 2012, commercial Hadoop distie Cloudera jumped ahead and grafted the new NameNode architecture onto its Hadoop stack. Metadata for HDFS was always replicated, but the block reports for HDFS are stored in the NameNode - and were not replicated. So what Cloudera CDH4 and Apache Hadoop 2.X does is setup a failover NameNode that is clustered to the primary with the changing block reports "hot-tailed" onto the replicated data. MapR Technologies' M5 Hadoop distro "shards" the NameNode, breaking it into pieces across the main memory of multiple NameNode servers. Hortonworks Data Platform 1.0 puts the NameNode and JobTrackers inside of ESXi virtual machine containers and is sticking to the Apache Hadoop 1.0 code base for now.
Dump HDFS, use Gluster RHSS
With today's announcement, Red Hat is going to start telling customers that what they need to do is dump HDFS and use Red Hat Storage Server (again, what was wrong with the Gluster name?) instead. Shadowman says it is not only more scalable and reliable than HDFS, but it can also get around the NameNode problem by essentially lying to Hadoop.
The Hadoop plug-in for RHSS 2.0, which has been in tech preview since last summer, is not just a pipe and converter that allows data to be transferred between HDFS and Gluster clustered file systems, explains Kleiman. The plug-in is an API shim that speaks HDFS to the Hadoop APIs, but it is really translating all of the storage commands and formats into native Gluster. So you end up running MapReduce jobs on top of Gluster, not HDFS, and they have some very different properties.
Red Hat Storage Server runs on Linux-based x86 servers with SAS or SATA drives and you can RAID protect those drives (or not) as you see fit. The clustered file system can ride ext3, ext4, XFS, and other file systems running on each individual server node in the cluster, and the secret sauce in what is called GlusterFS is that it aggregates these file systems and presents a global namespace to the processors that access the cluster (whether they are the ones running GlusterFS or other server nodes like an HPC cluster that is just doing compute). For commercial implementations, Red Hat puts Storage Server 2.0 on top of RHEL 6 and the XFS file system.
The interesting bit about GlusterFS, and that makes it well suited for Hadoop jobs, is that the clustered file system does not have a metadata server a Lustre-based storage cluster or its analog with Hadoop, the dreaded NameNode.
GlusterFS uses an elastic hashing algorithm to place data across the nodes and it runs across all of those nodes; it also has geographic replication features if you want to protect data. And therefore, instead of making triplicates of data sets, Gluster makes only one copy and then gives you the option of geographically dispersing the data using its own tools. So you can build high availability and disaster recover into the Hadoop cluster without actually clustering all the key nodes. (You may want to do this as well for extra HA.)
So what is the performance of this Hadoop-on-GlusterFS? "The real answer is that we don't know yet," says Kleiman. "Our goal obviously is to have equal or better performance compared to HDFS."
Last summer, when Storage Server 2.0 came out, Shadowman was saying that the clustered file system was tested in the labs to scale across more than 500 servers and create a distributed NAS that was petabytes in size. Hadoop generally poops out at 4,000 nodes running HDFS because of the NameNode bottleneck with the 1.0 code stack. But it could turn out that a smaller number of GlusterFS nodes yields better performance than a larger number of HDFS nodes. The point is that you get rid of the NameNode problem entirely by simply switching to GlusterFS.
GlusterFS is open source under a mix of the GPL v2, LGPL v3, and GPL v3 licenses, but to help spur the uptake of Red Hat Storage Server, Kleiman says that later this year the company will donate the Hadoop plug-in for GlusterFS to the Apache Hadoop community rather than weaving it into its own stack. Kleiman was not at liberty to say when this would happen, but said it would not happen in a few months, but rather later this year. The hope is that the commercial Hadoop disties will roll it up in their commercially supported releases and help spur the adoption of Red Hat Storage Server among Hadoop shops, but Kleiman said Red Hat was perfectly willing to provide fee-based tech support for the connector separately from RHEL and RHSS licenses if the disties don't pick it up.
The other option, of course, is that the commercial Hadoop disties might just grab GlusterFS themselves and roll the whole thing in to their packaged offerings. For that matter, they could grab a Linux variant and roll up a complete stack. Open source code presents many options. But this is about money and support, and it seems likely that companies putting Hadoop in production will want Red Hat support for RHEL and RHSS and Cloudera, MapR, Hortonworks, Greenplum, or IBM support for their Hadoopery.
That was the big news on Red Hat's Big Data strategy, but there are other elements. Red Hat was keen to point out that over time, companies may want to virtualize their Hadoop and other big data workloads to make them more flexibly deployed and more easily managed, and therefore there was plenty of talk about Red Hat Enterprise Virtualization, the company's impending OpenStack cloud control freak, its OpenShift platform cloud, and its CloudForms uber-control freak for hybrid clouds that span private data centers and public clouds.
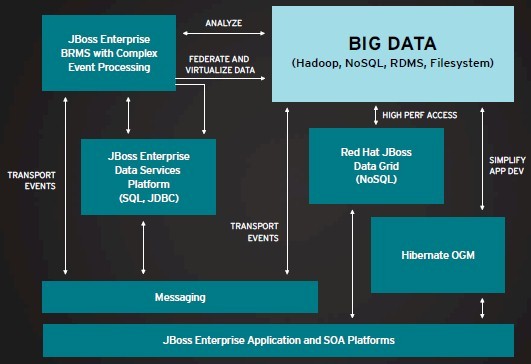
Big data is not just about infrastructure, but apps
Kleiman also wanted to remind everybody that Red Hat is also working on a Hive connector for its JBoss middleware. Hive, of course, is the data warehousing system that rides atop HDFS and allows people to make SQL-like queries against data stored in HDFS. Or, as it turns out, GlusterFS lying and telling Hadoop that it is HDFS. Technically, this is a JDBC driver that speaks Hive, as you can see here in this September 2012 JBoss Enterprise Data Services Platform document. So the funny bit is: you might have a Java application that pretends to be a Hive query that runs on Hadoop MapReduce that runs on a Gluster file system that is pretending to be HDFS.
Software is just plain freaking hilarious. ®
