This article is more than 1 year old
EMC morphs Hadoop elephant into SQL database Hawq
Learning to live with HDFS instead of kicking it to the curb
EMC has accomplished a remarkable bit of inter-species husbandry, marrying the Hadoop elephant to a Greenplum to birth an SQL-speaking Hawq.
The Hadoop big-data muncher has been sitting side-by-side with relational databases used in transaction processing and data warehousing systems, but they speak very different languages. Sure, you can use the Hive SQL-like data warehousing overlay for the Hadoop Distributed File System (HDFS), but queries are not necessarily fast. And if you want speed, you can use the Project Impala distributed query engine for Hive, announced by Cloudera last October to speed up Hive's SQL-like queries.
But what you really want to do is teach that Hadoop elephant to just speak SQL. Period. You want to take all of the inherent scalability and replication benefits of HDFS and allow it to be tickled with any standard SQL query or any tool that speaks SQL – it is, for the most part, the language of business analysts.
That, in a nutshell, is what EMC's Greenplum folks say they have done with Project Hawq, a multi-year effort at the EMC data warehousing and Hadoop unit that, according to Greenplum cofounder and senior director of products Scott Yara, draws on the ten years of foundational research and development that brought the Greenplum massively parallel relational database into existence and made it a contender against alternatives from Teradata, IBM, Oracle, and others.
Project Hawq, the SQL database layer that rides atop of HDFS rather than trying to replace it with a NoSQL data store, will be part of a new Hadoop package that EMC is calling Pivotal Hadoop Distribution, or Pivotal HD for short.

Greenplum cofounder and EMC database guru Scott Yara
That name is significant. Greenplum is part of the Pivotal Initiative, which EMC said back in December it was creating to mash up its parallel database, Hadoop, application frameworks, and a few other assets into one division.
The Pivotal name comes from the agile programming outfit that Greenplum used to help with some coding on its management software and that EMC decided to acquire last March when it rolled out and open sourced its Chorus management tool for Greenplum databases and Hadoop.
The Pivotal HD distribution was announced at an event in San Francisco on Monday, but the Pivotal division, the creation of which is the first major act of EMC chief strategy officer Paul Maritz after he stepped down as CEO of VMware in July 2012, has yet to be formally launched.
A Hawq riding an elephant steps on an Impala
The Pivotal HD rollout from EMC is based on the open source Apache Hadoop 2.0 stack, with lots of goodies ripped from the guts of the Greenplum parallel database and adjacent tools woven in for good measure.
It's not clear if EMC will open source all of these technologies, and that is one of the things El Reg will be pestering the company about. It is hard to call which way EMC will go, but considering that there is a Pivotal HD Community Edition, a free distribution used for experimentation, an Enterprise Edition that does not have the SQL-on-HDFS database feature but does have enterprise-grade support for a fee, and an add-on to the Enterprise Edition called Pivotal Advanced Database Services that adds this SQL query capability to data stored in HDFS, it doesn't look like EMC will be open sourcing the Greenplum family jewels.
The reason is that Project Hawq is the family jewels, although Yara called them the "crown jewels" in his launch presentation, saying that the database extensions to HDFS have been in development for over two years by an engineering team of more than 300 people. This, Yara said, was the largest Hadoop development team on the planet, and said several times that EMC "was all-in on Hadoop" because the company believed that Hadoop would be the foundation of a new "data fabric".

Hawq is the family jewels of the Greenplum database tweaked to extend HDFS
Incidentally, Hawq is not an acronym for any particular thing such as Hadoop Something Something Query, but rather just a bird name the engineers came up with to go along with Pig, Hive, and other animalistic Hadoopery nomenclature, with a marketing twist replacing the k with a q.)
The Hawq extensions to Hadoop's HDFS turn it into a database, explained Josh Klahr, product manager for the Pivotal HD line at EMC. "Hawq really is a massively parallel processing, or MPP, database running in Hadoop, running on top of HDFS," he said, "embedded, as one single system, one piece of converged infrastructure that can run and deliver all of the great things that Hadoop and HDFS have to offer as well as the scale and performance and queriability [his word, not ours] that you get from an MPP database."
If you don't believe Klahr, send him your emails. Personally, I figure there either have to be some limitations to this Hawq stuff or the relational database as we know it is dead.
"It really is SQL-compliant, and I don't use those terms lightly," Klahr explained further. "It is not SQL-ish, it is not SQL-like. The Hawq allows you to write any SQL query and have it work on top of Hadoop. SQL-99, SQL-92, SQL-2011, SQL-2003, and I am sure there are some other years in there as well."
The SQL engine running on top of Hadoop and HDFS is built to scale on top of hundreds to thousands of server nodes and it is derived from the optimizers in the Greenplum database – hence, why we won't see them opened up.
It has table security and table reporting all built in, and it uses standard Hadoop formats. You can point it at a text file, a sequence file, or Avro output, and you can read HBase columnar tables (if you have already made investments in HBase) and write database information in an optimized format that is native to Hawq, which adds performance benefits.
Compared to batch-oriented queries running against a Hadoop cluster, the combination of HDFS and Hawq shows anywhere from a 10X to 600X performance improvement, according to EMC. And that basically turns the batch system into an interactive one. This was the holy grail for mainframes back in the 1960s and 1970s, and it is what has been needed to have Hadoop become a part of the IT toolbox.
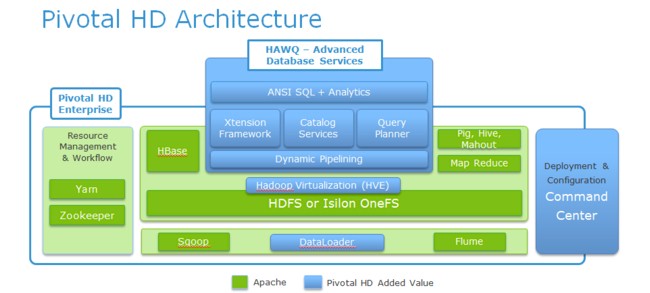
The Pivotal HD Hadoop stack, open bits in green and closed bits in blue
The Pivotal HD stack includes Hadoop 2.0 and its MapReduce parallel execution programming environment, plus HDFS. You can use Hive data warehousing, HBase key-value store, Pig development language, Yarn resource management, Mahout parallel analytics, and Zookeeper process management.
The Pivotal Hadoopery also includes what EMC calls Hardware Virtual Extensions, which makes Hadoop clusters aware if they are based on virtual machines rather than physical servers and is very likely a commercialized implementation of the "Project Serengeti" effort at VMware.
The stack also includes an installation and configuration manager, a job tracker called Command Center, a parallel data loader that comes right out of the Greenplum database and that allows hundreds of terabytes of data to be sucked into HDFS. The Spring Batch feature is a Java framework lifted from the Cloud Foundry project and tweaked for Hadoop.
The Pivotal HD distribution will ship in the first quarter, and El Reg confirmed that both the core Enterprise Edition and the Hawq Advanced Database Services add-ons would both be available by the end of the first quarter.
The software runs on EMC's Data Computing Appliances, which launched in the wake of its acquisition of Greenplum in October 2010. It will also run on the switch-hitting DCAs announced in September 2011 that could fire up Greenplum database or Hadoop nodes on the fly as workloads changed but did not literally merge the two workloads like Pivotal HD is doing.
You can also buy a software-only version of Pivotal HD if you want to run it on your own iron. Pricing information was not divulged. ®
