This article is more than 1 year old
Intel takes on all Hadoop disties to rule big data munching
'We do software now. Get used to it.'
Look out Cloudera, MapR Technologies, EMC, Hortonworks, and IBM: Intel is the new elephant in the room. Intel has been dabbling for the past two years with its own distribution of the Hadoop stack, and starting in the second quarter it will begin selling services for its own variant of the Hadoop big data muncher.
Intel is not just moving into Hadoop software and support to make some money on software and services, explained Boyd Davis, general manager of the software division of Intel's Data Center and Connected Systems Group. It also wants to accelerate the adoption of Xeon and Atom processors, as well as Intel networking and solid state storage when used in conjunction with Hadoop clusters.
In a nutshell, Intel thinks it has to do a Hadoop distribution itself to make sure it makes the server, storage, and networking money. And more importantly, Intel is thinking of Hadoop as a kind of foundational technology that is up for grabs.
Given this attitude, it is amazing that Intel doesn't just go all the way and say it needs its own Linux operating system, too. And if you think Intel is being logically inconsistent, Boyd said that with the software competency that Intel has now, it might have jumped in, had the Linux wave started today rather than in the late 1990s.
"Intel is a company that has grown in our capabilities around software a lot since the start of the Linux movement," explained Boyd at the launch event for the Intel Inside Hadoopery. "And of course, we have great partners in the Linux community that are driving the kernel forward. Who is to say if the Linux phenomenon were happening today we wouldn't try to do the same thing? I think it is a little bit more of when we have an ability to anticipate a trend as big as the Hadoop trend, if it is as big as we expect it to be. I think that just by taking an influence model we wouldn't have an opportunity to grow the market as fast."
Intel's desire, explained Boyd, was to speed up enhancements to the Hadoop tools as they run on Intel processors, chipsets, network controllers, and switch ASICs. But it is also to "add more value," which is another way of saying Intel wants more share of IT wallet.
And by the same logic, Intel could decide that the OpenStack cloud control freak is foundational technology. Or Linux. Or maybe the KVM or Xen hypervisor. Or any number of other things, like Open Compute Project servers.
The fact is, Intel sees an opportunity in very profitable software, and it is not about to miss this one as it has so many others in the past. Like everyone else, Intel knows it needs to be a software and services company, and it is Boyd's job to make that happen in the data center. And Hadoop is the best option Intel has.
Intel has been working on Hadoop technologies since it forged a benchmarking partnership with Yahoo! and HP back in 2009, and it has gradually come to the conclusion that its expertise in designing hardware and tuning software for it gives it some advantages over other commercial Hadoop disties.
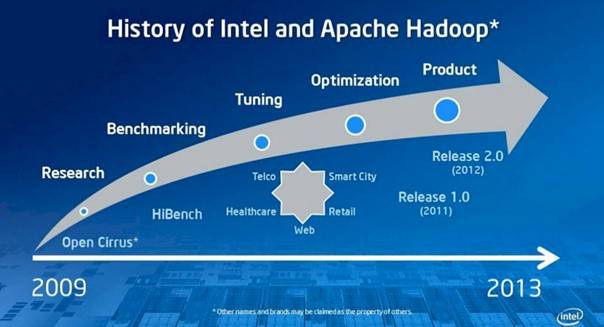
Intel has been gradually moving towards a formal Hadoop distro for years
As it turns out, after working on benchmarking and tuning, Intel was approached by China Unicom and China Mobile to help cope with some performance issues in the Hadoop stack when running on Intel Xeon processors.
In 2011 Chipzilla, rolled up a 1.0 release of what is now being called the Intel Distribution for Apache Hadoop – presumably to be called IDH1, dropping the A the way Cloudera does it, because IDAH 1.0 looks sillier. Last fall, at the behest of these Chinese customers and to get a few new customers like publisher McGraw-Hill and genomics researcher Nextbio on board, Intel rolled up IDH2.
With the IDH3 release, Intel is grabbing the Apache Hadoop 2.0 stack and doing some significant tweaking and tuning, explained Boyd. Intel has done a lot of work with the Hadoop Distributed File System, the YARN MapReduce 2.0 distributed processing framework, the Hive SQL query tool, and the HBase key-value store, he added.

How Intel is building its Hadoop stack
In the chart above, the elements in light blue are where Intel has made substantial performance enhancements, and the Hadoop stack modules in gray are just bits Intel is pulling directly from the Apache Hadoop project. Any code Intel has created to enhance any of the light blue modules will be eventually contributed back to the Apache Hadoop community; whether the community accept these changes into the Hadoop stack is another matter, and one for its members to decide. How quickly these are contributed is for Intel to decide.
And Intel promises not to fork the Hadoop code, too. "The goal is not to fork the code or drive any kind of dissension in the community," Boyd said.
That dark blue area at the top concerned Intel's Manager for Apache Hadoop, Chipzilla's very own control freak, which will not be open sourced. This tool will be used to deploy, configure, manage, and monitor the Intel Hadoop stack, and it will integrate with other Intel tools, such as its Data Center Manager power utilization control freak, its own rendition of the Lustre clustered file system, its cache acceleration software, and its Expressway service gateway.
The neat feature in this Manager for Apache Hadoop is that it is aware of AES-NI encryption and AVX and SSE4.2 instructions on Xeon E5 processors, as well as the presence of solid state disks and Intel network cards. It also has a feature called Active Tuner that Boyd says works by "using Hadoop on Hadoop" to do analytics on power and performance telemetry coming out of a Hadoop cluster to automagically tune it for a specific cluster. (Of course, it will no doubt work best on all-Intel technology.)
