This article is more than 1 year old
GE puts new Nvidia tech through its paces, ponders HPC future
Hybrid CPU-GPU chips plus RDMA and PCI-Express make for screamin' iron
GTC 2013 A top General Electric techie gave a presentation at the GPU Technology Conference this week in San José, California, and discussed the benefits of Remote Direct Memory Access (RDMA) for InfiniBand and its companion GPUDirect method of linking GPU memories to each other across InfiniBand networks.
And just for fun, the GE tech also specced out how he would go about building supercomputers using Nvidia's future hybrid CPU-GPU chips based on the "Project Denver" cores that Nvidia has been working on for the past several years.
Don't be at all surprised that GE is fiddling about with Nvidia chippery. The company does a lot of different things, and one of them is make military-specification computing and visualization systems for fighter jets, tanks, drones, and other weapons systems. Given the nature of the systems it creates, GE has become an expert in chips and network-lashing technologies, particularly given the real-time nature of the data gathering and processing that military systems require.
The GE techie who spoke at Nvidia's event was Dusty Franklin, GPGPU applications engineer at GE's Intelligent Platforms division, and Nvidia introduced his session at the conference saying he was one of the world's experts on RDMA and GPUDirect.
Speeding up the access to the memory in GPU coprocessors is important, Franklin explained, because the systems for which GE is building compute components are taking in lots of data very quickly. You have to get the CPU out of the way and just let the FPGA preprocess the data streaming in, and then pass it over to the GPU for further processing and analysis that the application running on the CPU can use.

GE's IPN251 hybrid computing card marries a Core i7, a Xilinx FPGA, and an Nvidia Kepler GPU with a PCI switch
On plain old CPUs, RDMA allows CPUs running in one node to reach out through an InfiniBand network and directly read data from another node's main memory, or push data to that node's memory without having to go through the operating system kernel and the CPU memory controller. If you prefer 10 Gigabit Ethernet links instead, there is an RDMA over Converged Ethernet, or RoCE, wrapper that lets RDMA run on top of Ethernet – as the name suggests.
With GPUDirect, which is something that InfiniBand server adapter and switch maker Mellanox Technologies has been crafting with Nvidia for many years, the idea is much the same. Rather than having a GPU go back to the CPU and out over the network to get data that has been chewed on by another GPU, just let the GPUs talk directly to each other over InfiniBand (or Ethernet with RoCE) and get the CPU out of the loop.
The PCI-Express bus has been a bottleneck since companies first started offloading computational work from CPUs to GPUs. At first, GPUs could only do direct memory access to the system memory on the node they were plugged into over the PCI bus. If you wanted to get data from another PCI endpoint, such as an FPGA or an Ethernet or InfiniBand network interface card, then you had to copy it first into system memory, into user spaces, and then push it out to the GPU.
But with the latest Kepler-class GPUs from Nvidia and its GPUDirect feature (also cooked up with Mellanox), if you use the CUDA 5 development framework GPUs can directly access memory in other GPUs over the network without talking to the CPU or its memory. Equally importantly, other devices hooked to the systems can pump data into and out of the GPUs without asking permission from the CPU, too.
What's the big deal, you say? The latency and throughput improvements with GPUDirect are rather dramatic, and when coupled with PCI-Express switching to link various computing elements, GE and others can create very sophisticated – and scalable – hybrid computing systems.
To prove that point, Franklin and GE's engineering team ran some tests of the combination of RDMA, GPUDirect, and PCI-Express switching between components on a shiny new IPN251 card, which has a little bit of everything on it.
The computing element on this battle-tested embedded computing and visualization system is an Intel quad-core 3rd Generation Core i7 processor, which has 16GB of DDR3 main memory allocated to it. This x86 chip is piped out to a PCI-Express switch, which has a Gen 1.0 link going out to a Xilinx Virtex-6 FPGA (that's the fastest bus link on that chip) and another Gen 3.0 link that hooks into a 384-core Kepler GPU with 2GB of its own GDDR5 graphics memory. The PCI switch also links into a Mellanox ConnectX-3 server adapter chip, which presents one InfiniBand port and one 10 Gigabit Ethernet port to the outside world.
For the real-time applications that GE is targeting with the IPN251, the important thing is to be able to take in signals from remote sensors, chew on them with the FPGA's custom algorithms and then quickly pass that data onto the GPU for rapid signal processing, with information then available for the CPU where the application is running.
Without RDMA and GPUDirect enabled, getting that data from the FPGA through the CPU memory stack and then into GPU is very CPU-intensive. And as the chunks of data ripping through the system get bigger, the latencies get longer and longer as the batch size increases. That PCI-Express 1.0 x8 link coming off the FPGA has its limits, but you can't even come close to pushing it as hard as the 2GB/sec limit it has in theory.
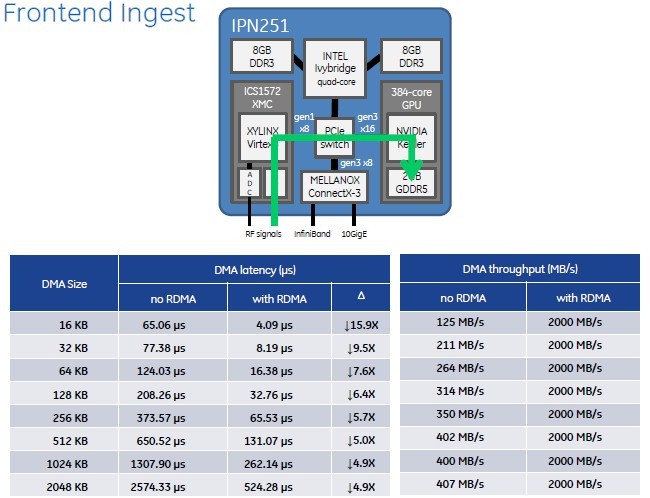
RDMA and GPUDirect really kick up the performance on the IPN251 hybrid card
For a 16KB DMA operation without RDMA and GPUDirect, there is a 65.06 microsecond latency and the data is coming into the GPU at around 125MB/sec. For anything above 256KB, performance flattens out to around 400MB/sec or so into the GPU and latencies climb very fast to 2.6 milliseconds. That is not a real-time system for a lot of mil-spec apps.
But turn on RDMA and GPUDirect and get the CPU monkey out of the middle. Now, regardless of the size of the chunk of data you are moving, GE found that it could pump data out of the FPGA and into the GPU at 2GB/sec, which is the peak load that the PCI-Express 1.0 x8 bus coming of the FPGA can deliver. Latencies on large data transfers are about five times lower, and on small chunks of data they approach 16X.
