This article is more than 1 year old
Oracle cuts down Big Data Appliance to make pilots cheaper
Talks up zippier Oracle apps – and new apps – tuned for Exadata engineered systems
It is hard to imagine a rack of servers and switches being too much of a machine for a pilot Hadoop system, but that is exactly what prospective customers have been telling Oracle. And so it is offering a cut-down "starter" version of its Big Data Appliance with a much lower price point.
George Lumpkin, Oracle's vice president of data warehousing product management, tells El Reg that contrary to what some people might be thinking, the Starter Rack of the Big Data Appliance X3-2 cluster is not aimed at small and medium businesses.
It is not a baby Hadoop cluster that will be suitable for modest data munching workloads, and in fact, says Lumpkin, the six server nodes in the cluster are the bare minimum of machines that are needed to load all of the software components of the Big Data Appliance just so you can see how they work and fit together.
You won't be able to get very much work done, and that is alright because, as a proof of concept machine, handling lots of unstructured data in Hadoop and the Oracle NoSQL (BerkeleyDB) database is not the point. If you want to do that, you have to build up the system.
The Big Data Appliance was previewed in October 2011 and started shipping in January 2012 using Xeon 5600-based servers. The initial setup was a full rack of servers (eighteen nodes) equipped with Oracle Linux (its clone of Red Hat Enterprise Linux) with Cloudera's CDH3 Hadoop distribution using Oracle NoSQL as the data store underneath it.
In December 2012, Oracle upgraded the Big Data Appliance with Xeon E5-2600 processors using its X3-2 systems. Oracle said that the new Xeon E5 iron delivered about 33 per cent more performance running Hadoop and Oracle NoSQL workloads. Oracle also upgraded operating system on the nodes to Oracle Linux 5.8 and the NoSQL database to the 2.0 level, which included some performance tweaks to help make those numbers.
With this week's announcement, Oracle is still using its Linux 5.8 release on the same hardware nodes, but the Hadoop stack is being upgraded to CDH4.2, the latest Cloudera release, and the Cloudera Manager control freak for Hadoop is upgraded to the 4.5 release.
The NoSQL database has also been upgraded, but Lumpkin did not know the release number at press time, and the open source R statistical analysis tool is upgraded to the 2.15 release.
Oracle Enterprise Manager, the uber control freak for all Oracle systems, operating systems, and applications, now has a plug-in that can reach into the Big Data Appliance and manage its hardware and interoperates with Cloudera Manager to play nanny to the Hadoop software stack.
The latest Big Data Appliances are preconfigured with NameNode HA, the redundant NameNode that Cloudera created for its distribution to get around the single-point-of-failure issue with this part of the Hadoop stack, which keeps track of where all the data is distributed around the cluster.
A full rack of the Big Data Appliance costs $450,000 and still has eighteen server nodes and about 600TB of raw capacity to store data in the NoSQL database. You can add more storage by linking racks of machines together over Oracle's own InfiniBand switches, which are based on Mellanox Technologies ASICs. Oracle premier support for this engineered system costs $54,000 a year.
You can see now why potential customers were balking at the base configuration of the Big Data Appliance, since $450,000 is a lot to spend on an appliance. Sure, that includes a "lifetime OEM license" to Cloudera's Hadoop, which is worth something. But still, that is a lot of dough to shell out for something that may not fit the bill.
Oracle, of course, is pretty confident that customers that are using Exadata database machines and Exalogic application server machines are going to want to use its Big Data Appliances (why are these not called Exadoops or something like that to be consistent?) in conjunction with database connectors to link the Hadoop machines to production OLTP systems and data warehouses.
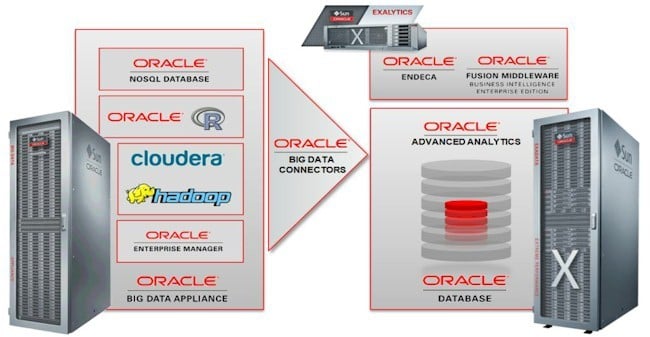
Oracle wants customers to buy all of its engineered systems
With the starter rack of the Big Data Appliance, the full complement of power distribution units and 40Gb/sec InfiniBand switches are in the rack, but it only comes with six of the X3-2 server nodes. These are set up to run all of the software components, and as we said above, this is a barely usable system in terms of capacity but sufficient for proofs of concept.
This setup, which has 200TB of capacity, costs $160,000. You can add another six server nodes for $160,000, and if you want to push it up to the full rack of eighteen nodes, you add yet another six nodes for another $160,000. So with the starter rack, you end up paying $480,000, or a $30,000 premium, for a single rack of the Big Data Appliance.
This, says Lumpkin, is a premium that customers are willing to pay to get a much smaller Hadoop test system. The important thing is that the Big Data Appliance shows up preconfigured and pretested, ready to accept unstructured data, and with Big Larry as the one throat to choke for support.
Oracle is also counting on all of the integration it has done between its engineered systems to be appealing to potential customers. The company says it can pump data between its Hadoop and database appliances at 12TB per hour.
The Big Data Appliance is also being added to Oracle's list of machines that are available as an on-premise infrastructure as a service, which Larry & Co announced back in January.
This special deal, which is like a 36-month lease with no interest where you pay for 75 per cent of the capacity and leave 25 per cent latent so it can be activated later, was initially available on Exadata database clusters, Exalogic middleware clusters, and Exalytics in-memory database appliances, Sparc SuperClusters (pairing Sparc T4 systems and Exadata storage servers) and Sun ZFS Storage Appliance arrays. Now you can buy a Big Data Appliance under the same deal.
Oracle is not talking about how many Big Data Appliances it has shipped, but Lumpkin says that the company has customers in the telecommunications, oil and gas, travel, and financial services industries that have acquired the Hadoop system, and as expected, customers are using the Hadoop machine to process network and application logs side-by-side with Exa machines.
In addition to rolling out the cut-down Big Data Appliance, Oracle is also talking up how it has tweaked and modified its E-Business, PeopleSoft, JD Edwards, Siebel, and Hyperion to use the fat main memory and flash storage in its Exadata appliances to run faster.
Oracle has also cooked up thirteen new applications for these suites that do "in-memory" processing when used on the Exadata appliances and run 10 to 20 times faster than they would on a cluster of rack servers. You can see these new applications listed here.
Steve Miranda, executive vice president of application development at Oracle, says these thirteen new apps from Oracle are only certified to run on Exadata systems, and that this is the case because without the memory and flash in the Exadata storage servers and the fast InfiniBand switching, they would not perform acceptably.
And just to be clear, none of them run on the Exalytics in-memory appliance, which is a fat Xeon server running Oracle's TimesTen in-memory data base for specifically doing very fast analytics on data sucked out of Oracle 11g databases. ®
