This article is more than 1 year old
Google boasts of app tuning prowess on 'warehouse scale clusters'
Making Gmail and search sit up and bark on NUMA servers
The hot-shot techies at Google are schooling IT shops once again, and this time the company is discussing some tuning and testing it has done to boost the performance of its applications running on multiprocessor servers with non-uniform memory access (NUMA) clustering to lash together two or four processors together into a single system image.
Tuning up applications so they can explicitly support NUMA is not trivial, but the smartest IT shops – such as hyperscale web application providers like Google, financial services and high frequency trading companies, and HPC centers – monkey around with their apps, trying to pin portions of code to specific processor cores and moving their data around to those cores to try to squeeze every ounce of performance out of the Xeon or Opteron servers they use .
Jason Mars and Lingjia Tang of the University of California San Diego, who do a lot of research in conjunction with the Chocolate Factory, and Googlers Xiao Zhang, Robert Hagmann, Robert Hundt, and Eric Tune have just released a performance study on NUMA-enabled servers that shows performance tuning on these machines is important even when you are running applications on what they call "warehouse scale computers."
THese are what you and I would call a data center dedicated to a fairly uniform and massively distributed workload. The paper was presented at the 19th IEEE International Symposium on High Performance Computer Architecture, and was recently released on the Research at Google Hardware and Architecture site.
With NUMA architectures, processors are slightly more loosely coupled together than with Symmetric Multiprocessing (SMP) architectures, but the net effect of both is that you have multiple processors sharing a single memory space and for all intents and purposes presenting themselves as one giant processor-memory complex to the operating system and its applications.
The details are different in how this is accomplished between SMP and NUMA machines, and it is largely moot these days because most modern chipsets use NUMA technology because of the scalability limits of SMP, which uses a shared memory bus or crossbar for all processors in a complex.They all share memory as one and, importantly, have uniform access to that memory.
With NUMA, as the name suggests, the processors have their main memory hanging off their sockets and they have local access to that local main memory as well as remote access to all of the other processors in the system through point-to-point interconnects.
NUMA is easier to implement in the processors, the glue chipsets, and the operating systems, but locality – the proximity of data in memory to the instructions that need it running on a processor – is an issue. If you get too many remote accesses to main memory, performance suffers. Or, as it turns out, sometimes it really doesn't.
Google's warehouse scale cluster paper looked at how you tune NUMA when you have clusters of machines, and what kinds of performance benefits you might expect.
The Chocolate Factory looked at two workloads running on two different machines in its research paper, and the iron used in the test was not particularly shiny and new.
For a test using the live Gmail service (specifically, its Gmail backend server), Google and the UCSD researchers employed a quad-socket box based on the Opteron 8300 series processors from Advanced Micro Devices. These processors came out in 2007, mind you.
As the Gmail backend server jobs ran on a portion of the Google data center, the techies kept track of where the processors were pulling data from – either local or remote memory – and assigned them a locality score. In this case, a locality score of 0.33 indicates that a memory access was two hops away (the maximum in the machine) while a locality score of 1 indicates the memory request was done out of processor's locally attached memory (the smallest possible hop).
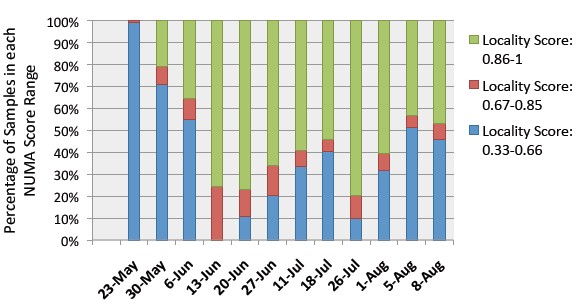
NUMA locality scores on the Gmail backend server
As you can see from the above three-month sample of data, locality on the NUMA system changes over time, and does so because of the restarting of jobs or the machine, kernel updates, or high-priority jobs coming into the system and demanding first dibs on compute and memory resources. So tuning is not just a one-time affair and then you walk away.
The thing to remember – and the thing that the Google paper shows with lots of elaborate diagrams – is that the higher the locality score, the lower the percent of CPU that a job requires. Google found that when most of the memory accesses were remote, it took 40 per cent more CPU to get the job done.
The researchers also ran NUMA locality tests on the two-socket servers used to power its Web-search frontend, a key component of its search engine. In this case, the box has two Intel Xeon X5660 processors and only one QuickPath Interconnect link between the two sockets.
Rather than passively observing what happens with the search backend, Google forced all data accesses to be local and saw what happened to performance, and then forced all memory accesses to be remote and observed the differences. Then it forced a 50-50 split and observed the results.
There are different elements of the Web-search front end, and in some cases because of the caching architecture of the server and the workload running across multiple machines in a cluster, having all memory accesses be remote is actually better than having a 50-50 split, even if it is worse than having everything local.
This was the case, for instance, with the BigTable data store that sits behind a whole bunch of Google services and that rides atop the Google File System.
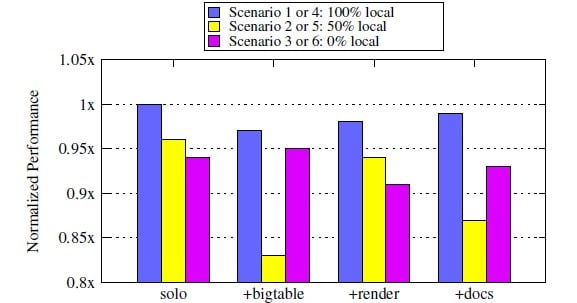
Different parts of Google's Web-search frontend stack respond to NUMA locality differently
In the chart above, solo refers to the Web-search frontend code, and then what happens then this code is run alongside BigTable, the Search frontend render (which collects the results from many backends and presents them to the user in a HTML page), and cluster-docs, which is a Bayesian clustering tool to take keywords or text documents, and as Google puts it, "explain" them with meaningful clusters. Each of these applications hog different resources, and so they have an effect on the Web-search frontend as it chunks along on the two-socket NUMA box.
The upshot, says Google, is that on the Gmail backend running on quad-socket Opteron boxes, tuning the code for NUMA could result in a 15 per cent performance boost, and for the Web-search frontend running on two-socket Xeon boxes, it was more on the order of a 20 per cent boost. That may not seem like much, until you consider that this is about what you can get out of a server CPU generational jump these days.
How you actually tune the code to do this, well, Google did not say. That's a trade secret. ®
