This article is more than 1 year old
Intel widens Xeon Phi HPC coprocessor lineup
We are family – and spoiling for a feud with Nvidia Teslas
ISC 2013 The pitch that Intel's salespeople have to make to push Xeon Phi x86-based coprocessors just got a little easier and more interesting. And in the same week that a hybrid Xeon-Xeon Phi machine - China's Tianhe-2 - took the title as the fastest supercomputer in the world.
And that is going to make life a little bit harder for Nvidia and its Tesla GPU coprocessor line and indeed for anyone trying to offload floating point math from CPUs to another device.
Intel is, of course, fired up about its Xeon Phi chip, formerly known as the "Many Integrated Core" or MIC processor. MIC is the remnant of a failed attempt to move into the graphics processing market with a chip based on the x86 instruction set. Plenty of products in the IT racket end up doing a job they were not initially intended for, and there is no dishonor in that. Intel wants to sell lots of Xeon Phi coprocessors in workstations, departmental HPC systems, and large capability-class machines that dominate the Top500 supercomputer rankings, and it certainly needs to make some extra money as the PC business goes through gut-wrenching changes that will almost certainly be echoed in the server racket in the years to come.
And in the short-term, anything that helps sell Xeon Phi chips hurts Nvidia's GPU business and its future server processor business, too.
"We believe that heterogeneity is here to stay," explains Rajeeb Hazra, general manager of the Technical Computing Group inside of Intel, which is part of the Data Center and Connected Systems Group that makes chips and chipsets for server, storage, and networking devices. And, perhaps more importantly, HPC center and commercial customers seem to concur with this notion.
In a briefing with press to go over the new Xeon Phi offerings, Hazra cited survey data from a few years back, when under 30 per cent of customers in the HPC segment surveyed by IDC said they would use any kind of coprocessor in their HPC systems. The latest IDC survey shows more than 70 per cent now believe that they will use coprocessors alongside processors in a heterogeneous (what we would call hybrid) system.
And, lucky for all of the HPC players, the market definition is expanding from the traditional government and academic labs doing simulation to sophisticated big data and simulation projects that mash up very large data sets that were too expensive to play with up until now, when servers and storage and bandwidth have all fallen in price enough for them to be economic as well as technically possible. This, among other factors, is driving the HPC systems market from $11bn in 2012 to $15bn in 2015, according to Intel.
We could argue that this merging of big data with simulation is not ethically or culturally desirable, but odds are we will lose that argument. Humans and their governments have never shown the ability to walk away from a technology that someone thinks they can make money on, and there is no reason to believe we are going to start in 2013.
We will no doubt convince ourselves that the European Human Brain Project and the US Brain Initiative, which together will cost billions of dollars, will lead to some insight. We will build what we think are good enough simulations of the human brain to convince ourselves that we can simulate human thinking, and then correlate data about millions or billions of real people and try to make some guesses about what people are thinking, and why.
What these and similar projects will do is keep the government labs buying more gear from favored vendors. And what will actually happen is that we will create a fake brain that will make an even more irritating automated call center rep and unemploy untold millions of people worldwide, and it will be called progress.
But I would bet on Google coming up with truly smart systems - and perhaps the foundation for SkyNet - before the traditional HPC centers of the world. They have more skin in the game than government funding for some supercomputer centers. Think about the economic value of replacing a good chunk of the knowledge workers of the world. Maybe we should work on our neolithic survival skills a little more and play with our iPhones a little less?
In the meantime, here's some shiny and crunchy new Xeon Phi coprocessors. As El Reg previously reported, Intel has been working to create a differentiated lineup of Xeon Phi coprocessors based on its "Knights Corner" 62-core, Pentium-derived parallel processing chip. And at the International Supercomputing Conference in Leipzig, Germany today, Intel will announce variants of the Xeon Phis with different feeds, speeds, and packaging but all based on the same Knights Corner chip.
There's no tick of a redesign and no tock of a process shrink, so don't get too excited. All of the new Xeon Phi cards and boards are based on the same Knights Corner chip that finally debuted last November using existing 22 nanometer Tri-Gate processes from Intel's wafer bakers.

There are now three families of Xeon Phi coprocessors
The existing Xeon Phi 3100 series is now fleshed out with active and passive cooling models, the latter being designed to slide into servers and workstations and make use of the cooling embodied in the enclosures of their machines without requiring a fan on the coprocessor itself.
These are the versions of the Xeon Phi that will will deliver the best bang for the buck and midrange performance with up to 6GB of GDDR5 graphics memory on the card and 240GB/sec of memory bandwidth. These plug into PCI-Express 2.0 slots. (The PCI-Express 3.0 slot in a system can accept these cards, but they will move at PCI-Express 2.0 speeds.)
There was a 5100 series card announced last year with passive cooling, but the new 5100 series is a system card that is meant to be woven more tightly into machines than the 3100 series can be and therefore aimed at high-density systems. The 5100 series will deliver over 1 teraflops of double-precision floating point oomph and more than 300GB/sec of memory bandwidth across its 8GB of on-board GDDR5 memory. Hazra says that several OEM customers are already working the Xeon Phi 5120D board into their designs.
The Xeon Phi 7100 series cranks up the clock speed on the Knights Corner chip, boosts the GDDR5 memory up to 352GB/sec, and gets 1.2 teraflops of floating point oomph.
Here's the more detailed feeds and speeds on the new Xeon Phi coprocessors:
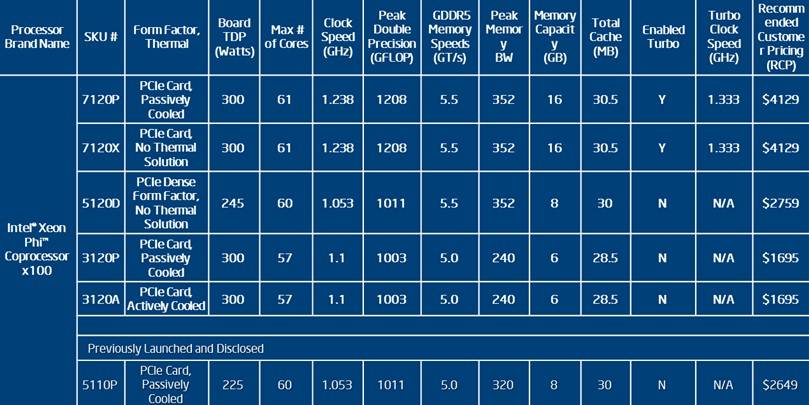
The feeds and speeds of the Xeon Phi family (click to enlarge)
As is usually the case with Intel, the top-bin parts are quite pricey compared to the low-bin parts. Also, the 3100 series prices were expected to be in the range of $2,000, but Intel is going for a slightly lower $1,695 price point, no doubt to put a little pressure on Nvidia's Tesla K20. The Xeon Phi 7100s are aimed at the K20X variants of the chips, in theory.
In practice, these two sets of products are so different it is hard to make direct comparisons based on raw flops alone. But, it is a job that El Reg will tackle in a future article now that the Xeon Phis have been updated and fleshed out. ®
