This article is more than 1 year old
VMware preps Project Serengeti Hadoop virtualizer for biz bods
Certifies various big data munchers to run on ESXi hypervisor
Hadoop Summit When you are a server virtualization company, as VMware is, there is no workload that you don't think can't – or shouldn't – be abstracted away from its underlying bare metal, and thereby made more malleable and portable. In this regard, Hadoop is just another thing for VMware to wrap itself around - perhaps make a little money on the side, too.
For several years, VMware has been suggesting that Hadoop should not run on bare metal x86 servers. A year ago it stopped talking about it and did something to make it easier, using a set of tools developed under the code name Project Serengeti to speed up the deployment and execution of Hadoop.
Serengeti made its debut last June at Hadoop World, and it took the Spring Java framework, now part of the Pivotal subsidiary jointly owned by EMC and its VMware minion, and used it to corral Hadoop, which is written in Java.
The efficiency benefits of virtualized servers are well known, and widely applied in the corporate data centers of the world these days. Hadoop shops are understandably a bit skeptical about this because CPU utilization is not so much an issue for them as it is for other generic server workloads. Everyone knows that Hadoop is more I/O and storage bound than CPU bound, so driving up CPU utilization may not get Hadoop shops anywhere; in fact, it may upset the balance between disk drives and CPU cores in a Hadoop cluster node.
But, provided the virtualization is done right, and the balance between compute and storage can be maintained, the operational benefits of having a bunch of heavenly elephants chewing on your data instead of physical ones can outweigh any downsides. That's VMware’s sales pitch, anyway.
It is hard to argue that virtualizing an entire Hadoop cluster, with its management, query, and data abstractions tools and various kinds of nodes all wrapped up nicely in virtual machines, is not a desirable thing; they can then be replicated and failed-over, just like any other virty infrastructure. And for developers, Serengeti allows for an entire virtual Hadoop cluster to be installed on a single physical machine for coding and testing, which is useful.
Roaming the Serengeti
Perhaps more importantly, by virtualizing Hadoop, you can bring that workload, which is largely siloed at companies today, into the same virtualized server pool that web, application, and database infrastructure runs atop. One neat application of a virtualized Hadoop cluster, which El Reg discussed last fall, would be to have two distinct Task Tracker and JobTracker nodes for two different Hadoop clusters share the same data nodes, interleaving work across a single NameNode.
The NameNode is the key bit of the Hadoop Distributed File System that keeps track of where unstructured data chunks are spread around the cluster; it is akin to a file allocation table in a disk drive, and if you lose a NameNode, you lose your HDFS just like if you lose both FATs you lose your disk drive's data.
So you might, for instance, have virtual cluster one use one set of replicated data on the physical nodes and let virtual cluster two use the other set, and thereby get twice the throughput through the cluster.
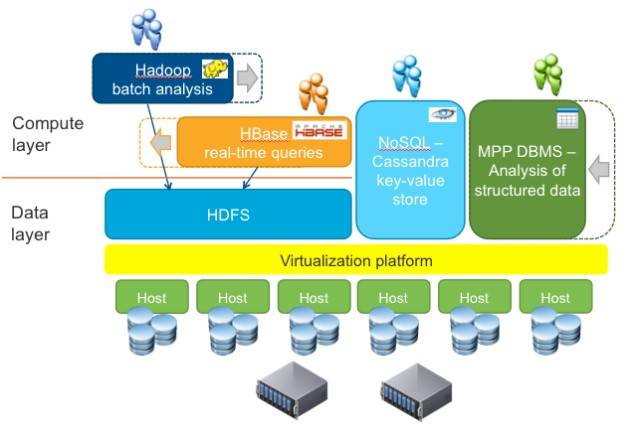
Block diagram of Project Serengeti
Serengeti doesn't only know how to virtualize and replicate core Hadoop servers, but also is aware of the HBase data warehousing system that rides atop of HDFS. This can configure active and hot standby replicants of HMaster nodes for the data warehouse, and can also scale out HBase RegionalServers once the data warehouse is set up atop HDFS. These features were added to Serengeti back in April with the 0.8.0 release.
And now, VMware is gearing up to put Serengeti into production. At the Hadoop Summit in San Jose today, Virtzilla will let loose a beta of a subset of the ESXi hypervisor and vSphere add-ons called Big Data Extensions, which is the first commercially supported implementation of Serengeti. Fausto Ibarra, senior director of product management at VMware, tells El Reg that the Big Data Extensions will be rolled up into the next vSphere release for free, a word that Virtzilla doesn't use very often. The next vSphere, presumably 5.2, is expected to launch at VMworld at the end of August and will likely ship later in the fall.
You can download it at this link and use it in conjunction with ESXi and vSphere 5.1.
The commercialized Serengeti software does not require VMware's Distribute Resource Scheduling add-on to ESXi, nor its vCenter control freak, says Ibarra, to get elastic capacity for either HDFS or HBase. But if you have DRS, then "it will work even better." Precisely how was not clear.
The Big Data Extensions have been certified to work with the open source Apache Hadoop 1.2 stack as wel as with Cloudera CDH 3.X and 4.2, MapR 2.1.3, Hortonworks Data Platform 1.3, and the all-in-the-family Pivotal distro (which doesn't have a release number yet).
Retailers, high-tech bods and financial guys already using it
Interestingly, says Ibarra, customers have been coming to Serengeti from two different paths. Some customers who are familiar with ESXi and use it for virtualizing their servers are keen on bringing Hadoop into the virtualized storage pool. And yet other customers who have physical Hadoop clusters but who have not virtualized their servers using VMware's hypervisor and tools are shifting to ESXi to virtualize Hadoop and other workloads.
Ibarra won't say how many companies are using Serengeti either as a prototype or in production, but large retailers, high-tech manufacturers, financial services companies, and startups are using it even before it is commercially supported.
Momentum with Serengeti will be particularly important, given the open source nature of Hadoop. Open source projects tend to have an affinity for each other, and Hadoop distie HortonWorks, Linux distie Red Hat, and OpenStack cloud controller distie Mirantis have teamed up to create Project Savanna, which will virtualize Hadoop atop OpenStack and the KVM hypervisor.
In addition to previewing the production-grade Serengeti tool, VMware will also announce today that the Pivotal HD 1.0 distribution of the elephantine big data muncher is the first commercial release to support the Hadoop Virtual Extensions (HVE) code that VMware created and donated to the Apache Hadoop project. The HVE extensions make the Hadoop modules virtualization-aware and are necessary to make Serengeti work better.
Here's one example of how HVE works. If you have two virtual data nodes in a Hadoop cluster and they are on a single physical server, they know they are on the same physical server; meaning they can talk faster over the memory bus than over the virtualized network interface, and thus that is precisely what they do.
Here's another example. Hadoop likes to make triplicate copies of data chunks, for both performance and reliability reasons. HVE knows to put two copies of the data on one single physical server, but to make sure the third copy is not only in a different server, but in an entirely different rack of servers.
Ibarra says that the HVE code is part of the Apache Hadoop project and that all of the distributions will pick it up and add it to their distros in the next few months. It is not clear how HVE might help the Project Savanna effort, but odds are it can interface with KVM and OpenStack in some fashion.
Pivotal HD 1.0 is also being formally certified to run on ESXi, following on certification for MapR's Hadoop distro last week and Cloudera's several weeks ago. No announcements were made for Hortonworks' distro, but given the Project Savanna effort that competes with Serengeti/BDE, you can see why there might be some foot dragging here. ®
