This article is more than 1 year old
Cray bags $30m to upgrade Edinburgh super to petaflops-class
Hector XE6 to be upgraded to Archer XC30
It is not much of a surprise, seeing as how the UK's national supercomputing service at the University of Edinburgh is a long-time Cray customer, that they would return to Cray to replace its existing XE6 system and replace it with a petaflops-class machine based on the latest Cray interconnect and Intel processor technology.
The new machine, to be called "Archer," will be based on Cray's latest XC30 iron, which pairs Intel's Xeon E5 processors with the "Aries" interconnect developed by the supercomputer maker through a contract with the US Defense Advanced Research Projects Agency.
The Engineering and Physical Sciences Research Council is providing the $30m in funding for the Archer system, which includes a production box with nearly three times the performance of the existing XE6 system, which has over 800 teraflops of aggregate number-crunching oomph and is nicknamed "Hector" – actually, they spell that "HECToR", for High-End Computing Terascale Resource, but we're not going to be drawn into such orthographic silliness.
The precise configuration details for the system were not provided by Cray or the University of Edinburgh, most likely because the machine will be based on the as-yet-unannounced "Ivy Bridge-EP" Xeon E5 processors from Intel. Earlier this year, Chipzilla said to expect the Xeon E5 chips to be launched in the third quarter, and early shipments for key cloud and supercomputer customers for the Ivy Bridge variants of these chips began several months ago.
The Hector system is comprised of 30 cabinets, which have a total of 704 of Cray's two-node XE6 blade servers. Each node on the blade has two sixteen-core "Interlagos" Opteron 6276 processors running at 2.3GHz. Each socket on the XE6 blade has 16GB of main memory, and with 2,816 compute nodes, that works out to 90,112 cores and 88TB of main memory.
The XE6 blade has two "Gemini" router interconnect chips, which implement a 3D torus across the nodes and allow it to scale up to multiple petaflops. The Hector machine also has a Lustre clustered file system that scales to over 1PB of capacity.
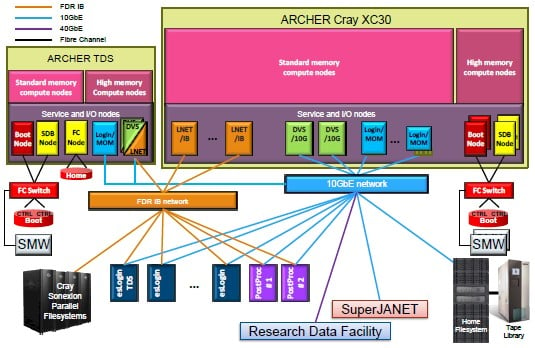
Schematic of the Archer development and production HPC systems
The XC30 supercomputer, developed under the codename "Cascade" by Cray with funding from DARPA's High Productivity Computing Systems program, started a decade ago. That funding came in two phases, with the initial lump sum of $43.1m being used to outline how Cray would converge various machines based on x86, vector, FPGA, and MTA multithreaded processors into a single platform. (GPU coprocessors had not become a thing yet in 2003 when the initial DARPA award came out.)
Three years later, DARPA gave Cray a $250m research award to further develop the Cascade system and its Aries Dragonfly interconnect as well as work on the Chapel parallel programming language. No one outside of Cray or DARPA knew it at the time, but the second part of the HPCS contract from DARPA originally called for Cray to take its multistreaming vector processors (all but forgotten at this point) and its massively multithreaded ThreadStorm processors (at the heart of the Urika graph analysis appliance) and combine them into a superchip.
But in January 2010, DARPA cut $60m from the Cascade contract and Cray focused on the very fast and expandable Dragonfly interconnect. The whole project cost $233.1m to develop, and now Cray has the right to sell iron based on that technology.
Cray got another $140m in April 2012 when it sold the intellectual property to the Gemini and Aries interconnects to Intel. Cray retains the rights to sell the Aries interconnect and is working with Intel on future interconnects, possibly codenamed "Pisces" and presumably used in the "Shasta" massively parallel systems that Intel and Cray said they are working on together as they announced the Aries interconnect sale.
The important thing as far as the University of Edinburgh is concerned is that the XC30 system has lots and lots of headroom – in fact, a fully loaded XC30 is designed to scale to well over 100 petaflops. But the UK HPC center is not going to be pushing the limits of the XC30 any time soon, with the Archer system having a little more than 2 petaflops of oomph. (Nearly three times the performance of the Hector machine, as the Cray statement explained.)
The plan for Archer, according to the bidding documents, calls for the university to get a test and development system as well as a much larger production system, with both boxes having compute nodes with standard memory but with a subset having fatter memory configurations.
A 56Gb/sec InfiniBand network links out to the Sonexion file systems (which has a total of 4.8PB of capacity and 100GB/sec of bandwidth into the system) and the login servers that sit in front of the production Archer machine. A 10Gb/sec Ethernet network hooks into other local storage and tape archiving, as well as to other network services.
The Archer deal includes the cost of the XC30 systems and the Sonexion storage as well as a multi-year services contract, all worth a combined $30m. (Yes, this kind of bundling makes it very tough to figure out what the system and storage hardware costs individually from services, and this is absolutely intentional.) Archer is expected to be put into production this year.
As we mentioned earlier, the Edinburgh HPC center is a long-time Cray customer, having installed a T3D parallel system in 1994 and added a T3E system in 1996 that peaked out at 309 gigaflops (you read that right) when it was retired in 2002. ®
