This article is more than 1 year old
Meet the man building an AI that mimics our neocortex – and could kill off neural networks
Palm founder Jeff Hawkins on his life's work
An absolutely crucial ingredient to AI
Time "is one hundred per cent crucial" to the creation of true artificial intelligence, Hawkins told us. "If you accept the fact intelligent machines are going to work on the principles of the neocortex, it is the entire thing, basically. The only way.
"The brain does two things: it does inference, which is recognizing patterns, and it does behavior, which is generating patterns or generating motor behavior.
"Ninety-nine percent of inference is time-based – language, audition, touch – it's all time-based. You can't understand touch without moving your hand. The order in which patterns occur is very important."
Numenta's approach relies on time. Its Cortical Learning Algorithm [white papers] amounts to an engine for processing streams of information, classifying them, learning to spot differences, and using time-based patterns to make predictions about the future.
As mentioned above, there are several efforts underway at companies like IBM and federal research agencies like DARPA to implement Hawkins' systems in custom processor chips, and these schemes all recognize the importance of Hawkins' reliance on time.
"What I found intriguing about [his approach] – time is not an afterthought. In all of these [other] things, time has been an afterthought," one well-placed source currently working on implementing Hawkins' ideas told us.
So far, Hawkins has used his system to make predictions of diverse phenomena such as hourly energy use and stock trading volumes, and to detect anomalies in data streams. Numenta's commercial product, Grok, detects anomalies in computer servers running on Amazon's cloud service.
Hawkins described to us one way to understand the power of this type of pattern recognition. "Imagine you are listening to a musician," he suggested. "After hearing her play for several days, you learn the kind of music she plays, how talented she is, how much she improvises, and how many mistakes she makes. Your brain learns her style, and then has expectations about what she will play and what it will sound like.
"As you continue to listen to her play, you will detect if her style changes, if the type of music she plays changes, or if she starts making more errors. The same kind of patterns exist in machine-generated data, and Grok will detect changes."
Here again the wider AI community appears to be dovetailing into Hawkins' ideas: one of Prof Ng's former Stanford students Honglak Lee published the paper A classification-based polyphonic piano transcription approach using learned feature representations in 2011. However, the implementation of this classification engine differs from the CLA approach.
How to memorize information like the human brain
Part of the reason why Hawkins' technology is not more widely known is because, for current uses, it is hard to demonstrate a vast lead over rival approaches. For all of Hawkins' belief in the tech, it is difficult to demonstrate a convincing killer application for it that other approaches can't do. The point, Hawkins said, is that the CLA's internal structure gets rid of some of the stumbling blocks that will eventually trip up rival algorithms in the future.
One of those stumbling blocks is the appreciation of time, as mentioned above. Hawkins believes his CLA's implicit dependence on processing events as and when they happen means that it will become the dominant AI system over its competitors.
In Hawkins' model, input signals from sensors are fed through a hierarchy of neurons at high speed; each level refines the incoming data into patterns that the next level above can process until the system develops a stable representation of whatever is producing those input signals. From there it can build up a general understanding of the world around it, and reliably predict what will happen next when it receives fresh stimuli.
This simulates brain cells quickly forming and breaking connections between each other as sensor signals ripple through one's grey matter.
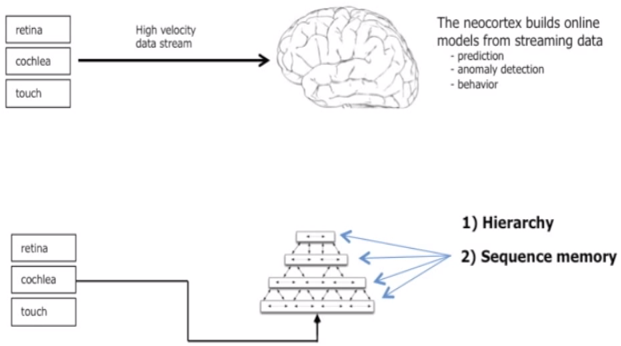
Hawkins' model of the neocortex ... sequence memory at each level of the hierarchy
"At the bottom of the [neocortex's] hierarchy are fast-changing patterns and they form sequences – some of them are predictable and some of them are not – and what the neocortex is doing is trying to understand the set of patterns and give it a constant representation – a name for the sequence, if you will – and it forms that as the next level of the hierarchy so the next level up is more stable," Hawkins explained.
"Changing patterns lead to changing representations in the hierarchy that are more stable, and then it learns the changes in those patterns, and as you go up the hierarchy it forms more and more stable representations of the world and they also tend to be independent of your body position and your senses."
He believes this approach is more effective than the neural-network-like models used by his rivals, and that's thanks to his hierarchy's storage system that he terms "sequence memory". Each level in the Hawkins' neocortex hierarchy uses sequence memory to cache the information it has processed. This allows the system to appreciate how the world changes over time when it makes its predictions.
Sparse Distributed Representations (SDRs), partially based on the work of mathematician Pentti Kanerva in Sparse Distributed Memory [PDF], are used to store data at each stage in the hierarchy.
Each SDR of a memory is written, roughly speaking, as a 2,000-bit string, where each bit has a specific meaning: setting a bit to 1 acknowledges a particular attribute about whatever is being represented.
An example: everyday computer software stores the letter 'A' in a UTF-8 byte as 0x41 (bits 0 and 6 are set to 1). 'B' is 0x42 (bits 1 and 6), and so on. No single bit describes the character or a part of it; the byte simply stores the UTF-8 code.
But the SDR for a memory of the letter 'A' may have bits 32, 33, 78, 901 and 904 set to 1, meaning two slanting lines pointing up, a mid-point horizontal intersect, no descenders, double height of normal letters. Each bit has a semantic meaning defined by the learning algorithm.
In practice, perhaps two percent of the bits in each SDR are active, so that's about 40 attributes defined for each memory. Storing every single bit in such sparsely populated 2,000-bit words is inefficient, so instead the code stores just the indices of those 40 set bits and discards the zeros – this gives the system the chance to compress that new representation down to, let's say, the indices of 10 bits. If you search for a 2,000-bit SDR matching that 10-bit pattern, whatever SDR you recall from storage is going to be pretty close to the SDR you wanted anyway.
Now you're storing and recalling data like the human brain.
Hawkins believes SDRs give input data inherent meaning through this representation approach.
"This means that if two vectors have 1s in the same [bit] position, they are semantically similar. Vectors can therefore be expressed in degrees of similarity rather than simply being identical or different. These large vectors can be stored accurately even using a subsampled index of, say, 10 of 2,000 bits. This makes SDR memory fault tolerant to gaps in data. SDRs also exhibit properties that reliably allow the neocortex to determine if a new input is unexpected," the website for Numenta's commercial product Grok explained.
