This article is more than 1 year old
It's ALIVE: Unstructured data upstart whips out data-AWARE array
I know what you stored last summer
Stealth exit startup DataGravity has introduced a hybrid flash/disk array with rich metadata recording and reporting functions for file creation, keyword content, content change and access, as well as data protection functions and collaboration help.
DataGravity was founded by CEO Paula Long, co-founder of EqualLogic, which was sold to Dell for $1.4bn in 2008, and president John Joseph, also with EqualLogic executive-level experience.
We're told by a Data Gravity spokesperson that this data-aware array's technology "is the first of its kind to analyse data at the point of storage" but it is not a business intelligence/big data analysis array and is better suited for file management, collaboration, governance and data compliance work involving unstructured data. Basically, at first glance, it looks like a niche product.
The product is the Discovery Series, with two models: the DG2200 and DG2400 with 48TB and 96TB capacities and 2.4 or 4.8TB of flash respectively. They provide iSCSI block and NFS/CIFS/SMB file access. Virtual machines are claimed to be managed natively. Metadata is generated as files are ingested, with over 400 file and data types supported.
These are dual controller systems, with primary node and intelligence node controllers connected by an 8-lane PCIe backplane. The primary node provides primary storage with the other node holding protection and intelligence data. The array's virtualisation technology enables "separate and dynamically allocated pools of storage for primary data and protection/intelligence data, each with their own fault domains."
These pools are based on disk drives with SSD caching. Disk drives are dynamically allocated to each pool and a free pool, without degrading the RAID set.
The primary node is responsible for storing data, tracking user access, and analysing incoming data streams in real time.
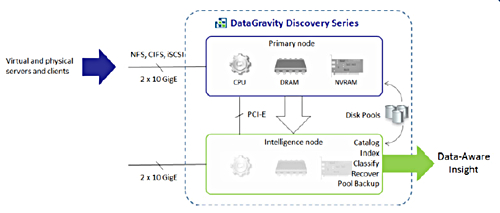
DataGravity Discovery architecture
The intelligence node maintains high-availability and point-in-time DiscoveryPoints as well as a searchable index of content and metadata. Data writes are mirrored "between the primary node and the intelligence node. Write data is maintained until the primary node commits the writes to disk and passes mirrored write data to the intelligence node."
It is a high-availability design in which "the HA write path is enhanced to pass additional metadata about the activity occurring on the primary array and uses this and the fine grain writes that were mirrored to the intelligence node for continuous data protection and data-aware analytics processing."
Metadata aspects collection aspects include:
- Record file operational, security, and content insight that is correlated to people and time using operations-based activity tracking.
- Record what data is changing and when.
- Ability to provide data-aware insights for VM (VMware) and iSCSI LUNs - understanding both content and who is interacting with the data objects.
- Tier metadata so that it can be combined and searched to answer multifaceted questions about the data.
The data protection is based on snapshots constructed "from the mirrored write cache on the intelligence node" and stored in a logically separate intelligence data pool. The features provide "perform near instant data restores in the case of missing or modified data at any level of granularity: blocks, files, files in a VM or LUN, and entire File Systems, VMs, or LUNs. This is all done without impacting primary I/O in terms of performance or availability."
The snapshots, which are always compressed and deduped on a targeted basis, can be mined for insights by the intelligence node processor and so don't affect primary storage operations.
It has built-in thin provisioning, in-line compression and targeted deduplication. However, there is no mention of replication or protection by storing data off the devices. No doubt this will come.
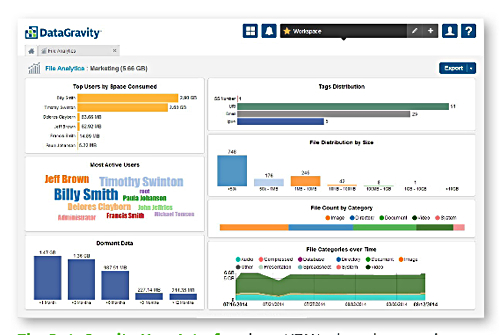
DataGravity Discovery GUI
The software provides excellent file-related discovery features, such as locating experts on any topic based on file titles and/or content, and so assisting collaboration. Excessive users or rogue users can also be identified.
Chris says
Our view is that DataGravity has joined Nimble Storage, Tegile and Tintri in the hybrid array stakes but with a distinctively different, file metadata rich product that will enable admin staff to better manage their file resources and access.
The Discovery technology provides a huge boost to admin staff and others' ability to understand what is going on in the array in terms of its file, VM and LUN operations and in terms of user activity with appealing visualisation tools. At first glance it appears to be a niche-appeal system ... but every unstructured data store could conceivably benefit from this approach and the technology could have wide and generic appeal.
It is a version 1.0 product set and will obviously develop its capabilities with, we think, some kind of scale-out capability and replication to widen the data protection capabilities.
Check out a datasheet here (PDF), architecture here (registration required for PDF), and videos here.
Discover Series array MSRP pricing is between $50,000 and $100,000 and product can only be obtained from DataGravity's channel partners. Availability is slated for October. VMworld attendees can see it in action at the DataGravity booth, #1647, from 24 to 28 August in San Francisco. ®
