This article is more than 1 year old
Hungry, hungry CPUs: Storage vendors hustle to get flash closer to compute
PUSH that data faster, storage boy
Multi-socket, multi-core CPUs are demanding entities: they have a gargantuan appetite for data which they suck up through a CPU-memory channel from DRAM, the server's memory.
This access happens in nanoseconds, billionths of a second. Getting data from places beyond memory, such as PCIe server flash cards, SSDs directly attached to the server or fitted to networked arrays, or disk drives, takes much longer and the compute core has to sit there, idling, waiting for the data it needs.
In a modern factory, decades of mass-production, just-in-time delivery and build-to-order experience mean that any factory assembling process is designed so that all the components necessary are available, on hand just when needed. The whole point of factory processes is that an assembly line doesn't stop, that multiple lines can operate at once, and that component logistics processes are in balance and deliver components in the right amounts and at the right speed to the assembly points in a production process.
A server is a data factory and it has, at its apex, a simple – in outline - process involving bringing data to compute. There is a sequence of stages getting that data to compute, such as from disk or sensor to the server's memory and then to the CPU cores. Fast caches are used to buffer slow data delivery sources downstream from memory.
But server compute efficiency has improved in leaps and bounds, newer generations of processors, server virtualisation and current containerisation are enabling servers to run more applications, meaning the cores want more and more data - more immediately - with every compute cycle.
A two-socket by eight-core server can often have a greater data need than its memory and downstream storage infrastructure can deliver at any one time.
Flash memory improves data IO speed at whatever stage it is used in this downstream infrastructure and often this enough – put SSDs in the networked array to replace disks. Put flash caches in the array controller. Put SSDs in a server's own directly-attached storage (DAS) slots. Put flash storage on PCIe flash cards which have faster data access than SATA or SAS-connected SSDs in the server's DAS infrastructure.
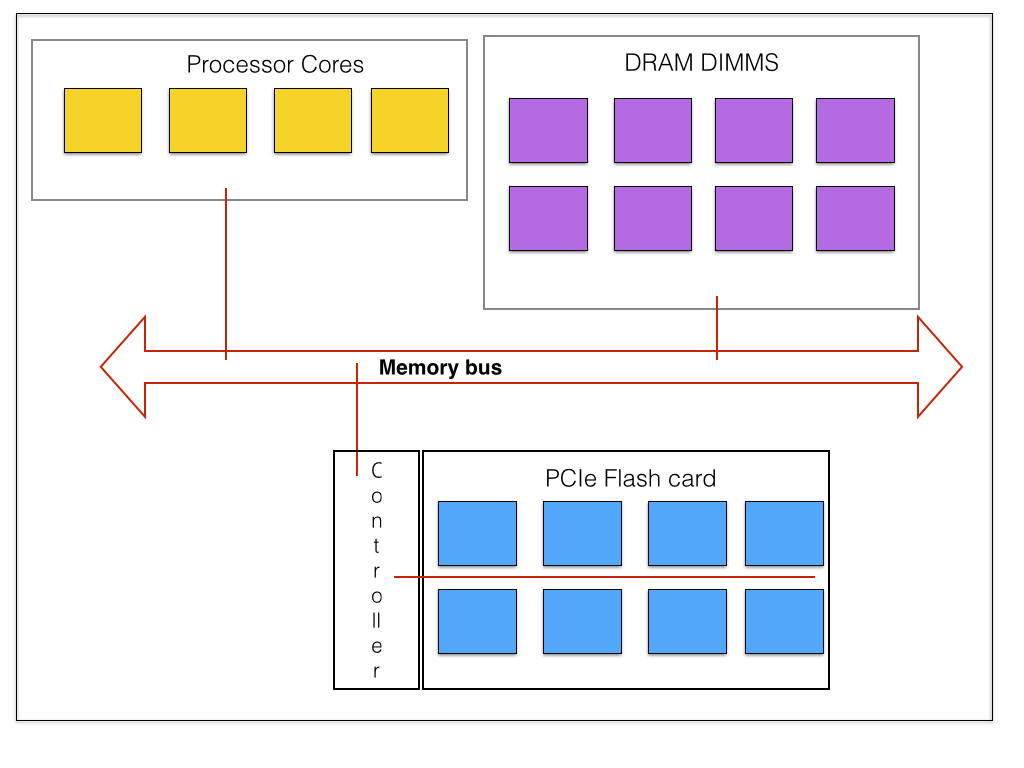
Server scheme with DRAM and PCIe flash.
Yet even this may not be fast enough as there is a data protocol conversion between a PCIe card and the memory bus en route to DRAM. What if we could put flash though directly onto the memory bus, in the same was as DRAM chips are accessed, through DIMMs, dual in-line memory modules.
- Memory access latency - nanoseconds - billionths of a second
- Disk access latency - milliseconds - thousandths of a second
- PCIe flash access latency - microseconds - millionths of a second
- Flash DIMM access latency - claimed to have 80 per cent lower latency than PCIe flash
Diablo Technologies of Canada has enabled this with its Memory Channel Storage (MCS) and it partners with a flash chip and SSD supplier, SanDisk, who sells the resulting ULLtraDIMM technology products to OEMs such as Huawei, Lenovo and Supermicro.
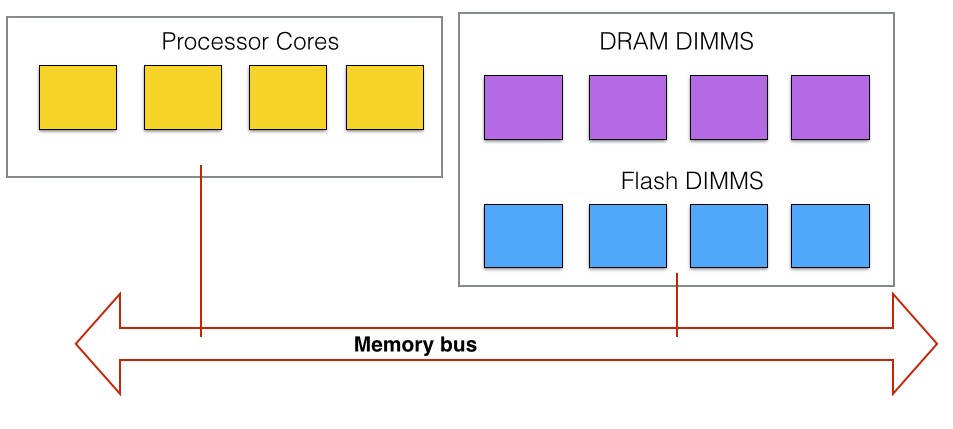
Flash with DIMM memory bus access
The memory channel utilises parallel access to increase data access speed.
Diablo testing with a 15 per cent read/write ratio saw PCIe flash having a 105 microsecond mean write latency while its MCS flash had a 29 microsecond mean write latency – 3.6X better.
In the MCS scheme the flash DIMMS exist in the same overall memory space as DRAM. Currently MCS-baed products use a DDR3 interface, DDR standing for double data rate type 3 or third generation. It transfers data at twice the speed of a preceding DDR2 specification.
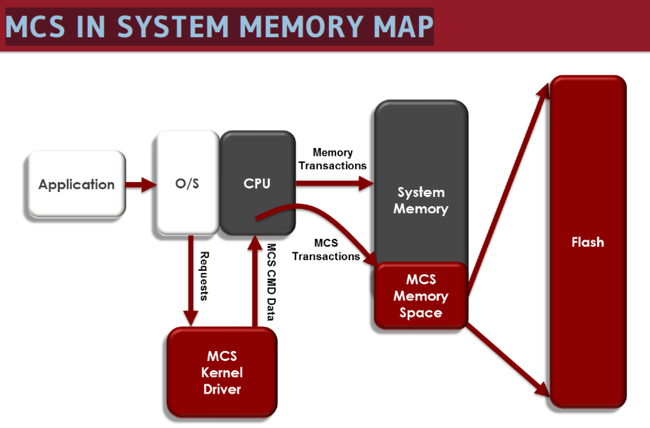
Diablo Technologies image.
DDR4, the fourth generation DDR standard, has a higher date rate again and its modules have twice the density of DDR3 modules and it has a lower voltage requirement than DDR3. The speed increase potential - the technology is developing - is about twice that of DDR3.
Diablo suggests that MCS technology is good for virtual SAN (VSANM workloads as it can:
- Eliminate a need for external storage arrays
- Provide extremely fast commit to clustered nodes for high-availability
- Has predictable IOPS and latency for heavy workloads
There are other advantages to bringing flash, a persistent store, closer to compute, such as less data movement in a system leading to lower energy costs, but we’re concentrating on the performance advantages here.
Why is it worth having such flashDIMMs as we'll call them? Why not put everything in DRAM? It's because DRAM is more expensive than flash and also because flash, with its NAND technology, is non-volatile and, unlike DRAM, doesn’t lose its contents if power ceases to flow. Memristor tech is similarly non-volatile.
Note this is not intrinsically a flash-only idea, this bringing closer together of non-volatile storage and compute. Any non-volatile memory could, in theory, be interfaced to DIMMs in thus way, assuming the business case was strong enough. HP's developing memristor technology could, in the future, be given a DIMM-based memory bus interface.
Memristors are, along with ReRAM (Resistance RAM) and Phase-Change Memory (PCM) candidate technologies for the coming post-NAND era. It’s anticipated that NAND cells cannot shrink much more after reaching 15-12nm or so in size. A follow-on technology will be needed to deliver the increased capacity and faster access speeds we’re going to need, because CPU resources will continue to improve – more cores for example – and server efficiency will also improve with containerisation of apps.
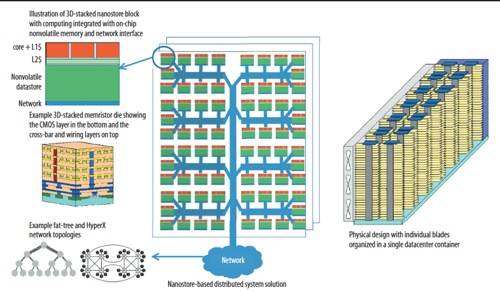
HP Nanostore idea
The trend to bring flash closer to compute is the latest iteration of a longer term trend, which is to bring storage generally closer to compute. HP talked about a Nanostore concept two years ago, in which NAND flash was integrated on the same chip as a processor.
Check out an IEEE paper from HP Labs about the concept here (pdf).
The point about improving CPU resources made earlier is amplified in this paper. It states: “Historically, the first computer to achieve terascale computing (1012, or one trillion operations per second) was demonstrated in the late 1990s. In the 2000s, the first petascale computer was demonstrated with a thousand-times better performance. Extrapolating these trends, we can expect the first exascale computer (with one million trillion operations per second) to appear around the end of this next decade.”
Storage faces a continually increasing demand to deliver more data, faster, to compute. There are ancillary needs such as lower power draws and reducing data movement through an IT system but performance is the main need. The way to do this is to bring storage closer, spatially and performance-wise, to computer processor cores and reduce IO wait time, that classic problem that is always getting solved and then re-occurs again. Nanostores and Memristors will only be one of the latest attempts to solve that long-standing problem. ®
