This article is more than 1 year old
NetApp brings Hadoop functionality to its ONTAP customers
Users can dip their toe in the elephantine waters
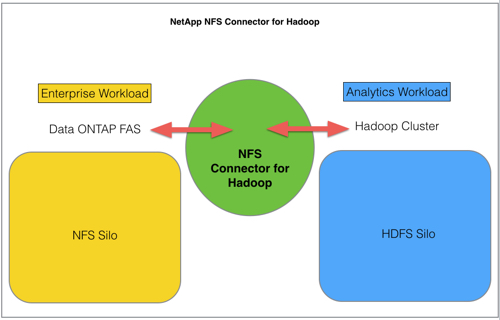
Doing what it's so so good at, NetApp has added a connector product, enabling its Data ONTAP customers to run Hadoop analytics on their NFS data store without having to copy data from WAFL into HDFS.
Its NFS Connector for Hadoop enables Hadoop analytics to be run on the incoming Big Data from its various sources, and then combine that with looking at structured data as well. This is essentially combining the two kinds of data to get a more rounded view of what’s going on in a business or public sector organisation.
This avoids having to migrate masses of data from FAS arrays into the HDFS (Hadoop’s file system) cluster.
The Hadoop cluster can work primarily on HDFS, and treat ONTAP as a secondary file system, and moreover it can conceivably run only on the FAS arrays without a separate HDFS silo.
That might be a way for ONTAP users to dip a toe into Hadoop waters and test the temperature.
The connector, which is open source and hosted on GitHub:
- Works specifically with MapReduce for the compute part of the Apache Hadoop framework
- Can support Apache HBase (columnar database)
- Can support Apache Spark (processing engine compatible with Hadoop)
- Works with Tachyon in-memory file system that can run with Apache Hadoop and Spark
In a blog Val Bercovici from NetApp’s CTO Office says: “NetApp plans to contribute the code to the main Hadoop trunk".
NetApp also has its NOSH (NetApp Open Solution for Hadoop) scheme with Cloudera which you can check out here.
Get more info from NetApp’s NFS Connector Technical Report. Download the NFS connector for Hadoop from here. ®
