This article is more than 1 year old
Hyper-scaling multi-structured data? Let's count the ways
Molluscoid magic is just the start
Comment Hyperscaling storage for unstructured data, file and object silos is conceptually straightforward. You buy yourself commodity hardware and get parallel filesystem software or object software. Hyperscale block storage generally means buying a monster SAN. But what happens if you need to have hyperscale storage across block, file and object bases?
That's when you need molluscoid magic; say hello to Ceph, InfiniDat ingenuity or ScaleIO's scheme.
They would have to cope with four kinds of data;
- Block, as classically used by databases and seen in storage area networks (SANs)
- File, as used by the generality of applications with data located in folders containing files, stored either on local, directly-accessed storage (DAS) or network-attached storage (NAS or filers)
- Object, with the object's contents used to compute its address and locate it in a sea of connected object storage nodes
- Unstructured data typically stored in Hadoop with multiple server nodes using the Hadoop Distributed File System (HDFS) and each running computations against its locally-stored data for parallel processing
As data grows and grows storage systems scale to tens of nodes and then go into hyperscale territory with hundreds of nodes and exabyte-level capacities; this will do for a rough definition of hyperscale.
At hyperscale normal storage structures can break down; traversing a file:folder structure with a billion files and a million folders, or more, can take an age in CPU cycle terms. A single and central metadata system becomes a choke point for access, a bottleneck that slows everything down. Some kind of parallelised, accelerated access is needed to thread your way through the metadata monster that controls access to the millions of data structures you have, files, objects, etc.
This is the service IBM's Spectrum Scale, its rebranded GPFS (General Parallel File System) provides, and it's what Isilon systems do with metadata cached in flash for faster access. If you need storage to scale at such levels for multiple kinds of data then there are relatively few candidates:
- Object Storage -- can do file as well but not block
- Open Source Ceph - for multi-structured data - object, file and black
- Infinidat - for multi-structured data - object, file and black
- EMC's DSSD all-flash array and ScaleIO virtual SAN
- Open Source Gluster - can store objects and files bit not block
We'll rule out object storage as it's effectively limited to object and file access, being ill-suited to block-access. It's also a networked storage schema and not generally intended for Hadoop-style workloads with compute on the nodes. Similarly we'll rule out Gluster as it is file and object only
Ceph is a special case of object storage that does fit our bill though.
Ceph
Ceph - think cephalopod (octopus) - was created for a PhD dissertation in the 2006/2007 period by Sage Weil at the University of California' s Santa Cruz campus. He graduated in 2007 and carried on working on Ceph with colleagues, and set up Inktank Storage to deliver Ceph services and support in 2012. Red Hat bought Inktank for $175m in April, 2014.
Weil's dissertation abstract states;
The emerging object-based storage paradigm diverges from server-based (e. g. NFS) and SAN-based storage systems by coupling processors and memory with disk drives, allowing systems to delegate low level file system operations (e. g. allocation and scheduling) to object storage devices (OSDs) and decouple I/O (read/write) from metadata (file open/close) operations. Even recent object-based systems inherit a variety of decades-old architectural choices going back to early UNIX file systems, however, limiting their ability to effectively scale.This dissertation shows that device intelligence can be leveraged to provide reliable, scalable, and high-performance file service in a dynamic cluster environment. It presents a distributed metadata management architecture that provides excellent performance and scalability by adapting to highly variable system workloads while tolerating arbitrary node crashes. A flexible and robust data distribution function places data objects in a large, dynamic cluster of storage devices, simplifying metadata and facilitating system scalability, while providing a uniform distribution of data, protection from correlated device failure, and efficient data migration.
The software is based on RADOS, a Reliable Autonomous Distributed Object Store, across multiple nodes with file and block access layered on top.
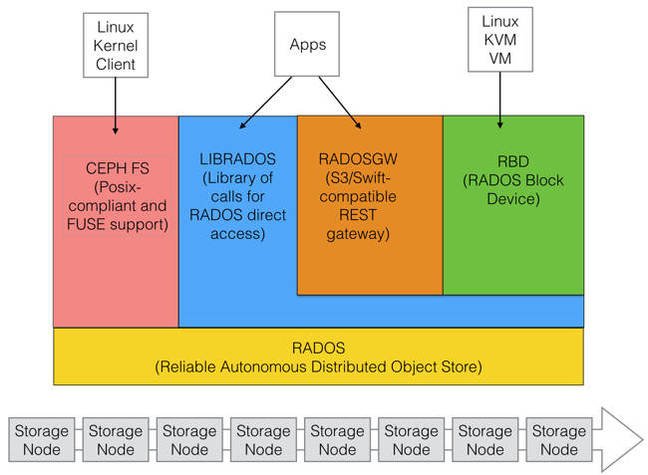
Basic Ceph structure
Direct object store access is via the LIBRADOS call library, which supports C, C++, Java, Python and PHP. CEPH FS provides a POSIX-compliant file system access route from apps running in Linux systems. Files and folders are turned into objects. The Ceph client has been included in the Linux kernel.
RBD is the RADOS Block device with block access calls translated by LIBRADOS into RADOS calls. There is also an S3 and OpenStack Swift-compatible REST gateway using LIBRADOS to get down into RADOS.
Data is striped by Ceph across its clustered storage nodes. The cluster can be expanded or contracted with data balanced across the nodes to avoid unbalanced loading. Ceph features include thin provisioning, replication, erasure coding, and cache tiering. It is said to be self-healing and self-managing.
The current release version of Ceph from RedHat is v0.94, known as Hammer, and described as the eighth stable release. It replaces the Firefly release.
SuSE also has a Ceph distribution, SuSE Enterprise Storage, calling Ceph "the most popular OpenStack distributed storage solution in the marketplace."
SuSE Ceph uses the Firefly release and will, no doubt, soon get upgraded.
Fujitsu CD10000
As an example of a Ceph array we can look at Fujitsu's ETERNUS CD10000 which scales from 4 to 224 nodes and up to 56PB of capacity currently. The nodes interlink with InfiniBand providing high-speed data and meta-data transfer between them, but this will change with the upcoming generation. Fujitsu has designed the ETERNUS CD10000 as single appliance, bundling Ceph, hardware, interconnect and service, with a management layer it says will allow adminstrators to manage both Ceph and the hardware as a single instance.
Storage capacity is based on a combination of PCIe SSDs for the fastest data access, 2.5-inch 10K disk drives for not quite so fast access, and 3.5-inch disk drives for bulk capacity needs, making three tiers in all.
There will be more than 13,000 disk drives in a 224-node CD10K system. Because object storage uses a more efficient way of storing and protecting data against disk failure than RAID the overhead of RAID schemes is not needed. Also reconstructing data after any drive failure is faster than a RAID-based reconstruction, a point that is increasingly relevant as the system scales in capacity.
The supported application interfaces are KVM, Open Stack Swift, Amazon’s S3, and CephFS. The CD10000 includes RADOS block device functionality.
Nodes can be added non-disruptively and the data load is rebalanced across the set of nodes. Old nodes can be swapped for new ones, and data is migrated with no system downtime. This means that as Fujitsu updates the system, with new controller/storage hardware, old and new nodes can be intermingled with no need for a fork-lift upgrade.
The system is inherently fault-tolerant and self-healing and Fujitsu says its customers get the benefits of open source software without having to go through a do-it-yourself hardware sourcing exercise.
