This article is more than 1 year old
Startup BlueData in the green after pocketing millions from Intel et al
Here comes 'Hadoop-as-a-Service'
Big data startup BlueData has to get bigger pockets; it’s just trousered $20m in C-round funding from Intel Capital, existing investors and a secret strategic investor.
That takes total funding to a modest far-from-unicorn-status $38m and the cash will be used to “accelerate our momentum in the Big Data market.” The company was founded in 2012 and its first two rounds of $8m and $15m occurred in 2013.
Co-founder and CEO Kumar Sreekanti was an research and development VP at VMware. Tom Phelan, the other co-founder, was a senior staff engineer at VMware, concerned with ESXi’s storage multi-pathing, vFlash, server-side SSDs and a vmdk caching project.
They aim to decouple compute from storage. Hang on. Isn’t that what Velostrata is aiming to do? It is, so how is BlueData different?
BlueData’s EPIC software provides on-demand data access from on-premises Hadoop or Spark clusters to your on-premises HDFS data. The compute and storage is de-coupled but the compute is on-premises and not in the cloud.
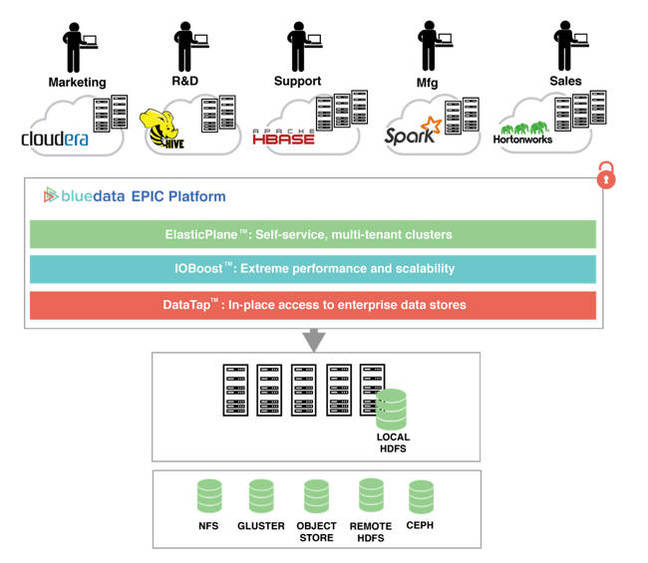
BlueData EPIC software platform concept
EPIC is 3-layered, starting with DataTap, yes, you read that right and no, it’s not DataONTAP, following that up with IOBoost which must, duh, boost IO, and then capping it with ElasticPlane which is a set of self-service, multi-tenant, Hadoop or Spark clusters, with support for containers and hypervisors.
DataTap provides:
- HDFS abstraction to run any Big Data application unmodified,<>li>
- Optimized, fast connectivity to NFS, HDFS, Swift API, Gluster and Ceph,
- Claimed “faster time-to-results, faster time-to-value for Big Data.”
You can use the no-charge EPIC LITE or the annual subscription-based EPIC Enterprise. Get a free download of EPIC LITE here. The Hadoop/Spark clusters have data access to Local HDFS (pre-installed) (or local file system with EPIC LITE), Remote HDFS, Remote NFS and/or Remote Gluster.
Okay, now BlueData is enabling, it says “Hadoop-as-a-Service or Spark-as-a-Service on-premises". Part of the deal with Intel, alongside the Intel Capital funding, involves BlueData “working together closely with Intel in areas including Hadoop and Spark, virtualsation and container technology, as well as caching and security/encryption.”
In a blog Sreekanti writes: “There has been some early adoption of Big Data in public cloud environments, but the majority of enterprise deployments remain on-premises due to considerations around security, governance, and data gravity. These deployments have been predominantly bare-metal configurations, and the traditional Hadoop architecture is relatively rigid and inflexible.”
Big Data workloads need to transition from physical to virtual to a cloud-like experience (e.g. Hadoop-as-a-Service) on-premises.
New innovations help make this possible: including technology advancements that make data locality irrelevant for Hadoop and the rapid emergence of container technology to simplify application deployment.
Sounds interesting? Read an earlier blog by Sreekanti about EPIC here and get an EPIC datasheet here.
This seems to about short-cutting Hadoop/Spark cluster spin-up time and complexity.
Its about Hadoop or Spark as-a-service. I guess we could say thus us about Analytics-as-a-Service (AaaS), on-premises and that BlueData makes it shortAaaS ... geddit? Oh, never mind. ®
