This article is more than 1 year old
Analytics are better with shared storage and not scale-out, says IBM
Conveniently, we happen to have this shared storage thing lying about. How about that?
IBM has a packaged IBM Data Engine for Analytics – Power Systems Edition, a cluster that includes the integrated servers, parallel file system storage, network switches, and software needed to run MapReduce-based workloads.
It is described as a technical-computing architecture that supports running Big Data-related workloads more easily and with higher performance.
IBM proposes using a shared storage model as an alternative to scale-out architectures that associate the cluster storage with the data nodes. We're told it allows storage and compute resources to scale completely independently.
The model uses Big Blue's Elastic Storage Server (ESS), an integrated storage system, including servers, storage enclosures, disks and Spectrum Scale software. In IBM marketing language its "Data Engine for Analytics provides a platform in which data from traditional systems of record can coincide with new forms of unstructured data from systems of engagement". The Data Engine for Analytics (DAE) is a system of insight.
Big Blue says:
[With] Spectrum Scale Native RAID, the cluster data is managed using higher-level erasure codes to protect against multiple disk failures while offering significant disk savings over the 3x replication found in typical HDFS installations. ESS stores data using declustered RAID6 with support for either 2-fault or 3-fault disk fault tolerance... ESS distributes the data and parity information evenly across all disks in the system [which] allows for storage rebuilds triggered by a disk failure to complete faster than traditional RAID rebuilds by distributing the work across many disks rather than just a few.
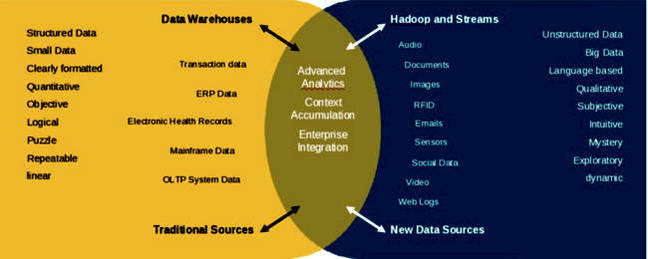
IBM's systems of insight
IBM's DAE software includes:
- Platform Cluster Manager Advanced Edition (PCM AE)
- InfoSphere BigInsights Enterprise Management, which includes:
-
- Platform Symphony Advanced Edition with SLAs for multi-tenancy
- Spectrum Scale Advanced Edition
- Standard open-source Map-Reduce applications are enabled through the inclusion of IBM Open Platform for Apache Hadoop
Additional analytics are available through the optional inclusion of BigInsights Data Scientist or BigInsights Data Analyst.
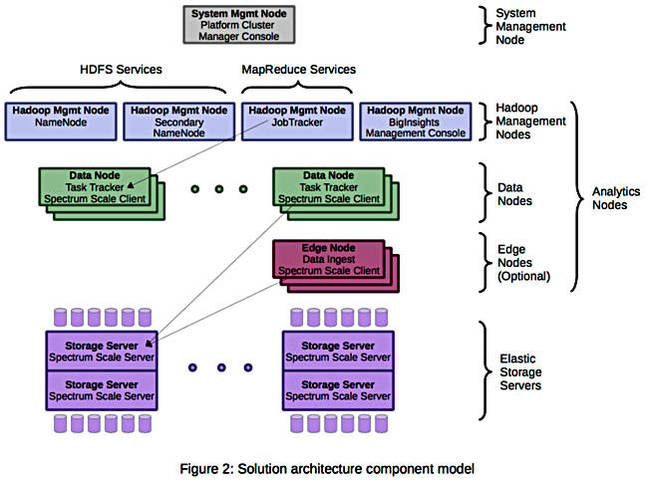
DAE diagram
Big Blue says a cluster that supports Big Data-related workloads has two main aspects: the Hadoop Distributed File System (HDFS) and a MapReduce engine. DAE implements the HDFS and MapReduce environment using IBM's BigInsights Enterprise Management.
The full system is assembled and installed at an IBM delivery centre prior to delivery with all included software preloaded, somewhat similar to EMC's VCE converged system operation. On-site services staff integrate it into the customer data centre.
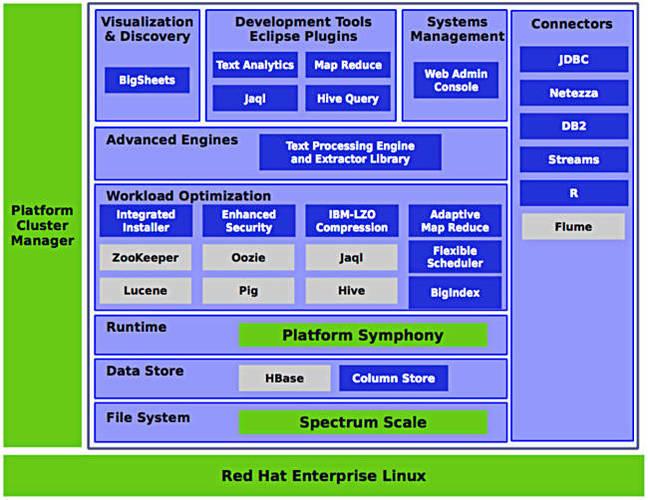
DAE software stack.
The IBM Data Engine for Analytics – Power Systems Edition is described in this 45-page System Reference Guide and there is a load of detail in it. The first application pattern supported by this sarchitecture is MapReduce, with additional workflows due to be added in the future. ®
