This article is more than 1 year old
Robin flies into storage aviary: Will it soar, or is it just winging it?
Is it a bird? Is it a data plane? No, it's a virtualisation container upstart
A new robin has landed in the storage startup tree, whose song promises to clear up the sprawling horrible inefficient mess that is today's Big Data munching and analysing customer IT infrastructure. If that strikes a chord then read on.
It is Robin Systems and it has just gained $15 million in A-round funding led by a USAA subsidiary and DN Capital, with participation from Hasso Plattner Ventures and existing investors. Total funding is now, by today's standards, a modest $22 million. What is all this about?
The company was started up in 2013 by Krishna Yeddanapudi with, we estimate, $7 million seed funding. He was previously an architect at Violin Memory (2011-2012), a chief systems architect at Technicolor (2009-2011), and a software architect at Tivo (2004-2008). Before that he was a software consultant for various companies.
Yeddanapudi says: "We are pioneering [the] creation of [the] industry's first Data-Centric Compute and Software Containerization software to help enterprises accelerate, consolidate, and simplify their modern data applications. Robin's software dramatically improves the performance for distributed applications like Hadoop, NoSQL, Elasticsearch, etc."
Technology background
Robin's technology uses "a combination of Linux containers, Flash, and storage virtualization technologies." We are told Robin provides the most efficient and highest-performing operating infrastructure, ranging from modern data applications including Spark and Hadoop to traditional applications such as NoSQL.
It also eliminates data duplication by enabling data sharing across applications and clusters.
Overall it's claimed to help enterprises reduce hardware and operating costs, boost application performance, and gain business agility. In a word, how?
First of all, its technology is aimed at customers using products such as mongoDB, Hadoop, Ceph, Gluster, Cassandra, Tachyon and Swift. We're not talking classic RDBMS here, and Robin calls these customers "data-centric enterprises," which strikes us as crap terminology; for what are Oracle users if not data-centric?
Ignoring that, Robin says these business' IT infrastructure is inefficient, with 3-way data copies, dedicated file systems, dedicated storage, and dedicated compute. There is "unnecessary data duplication across clusters and applications, [which] causes storage wastage and network overload."
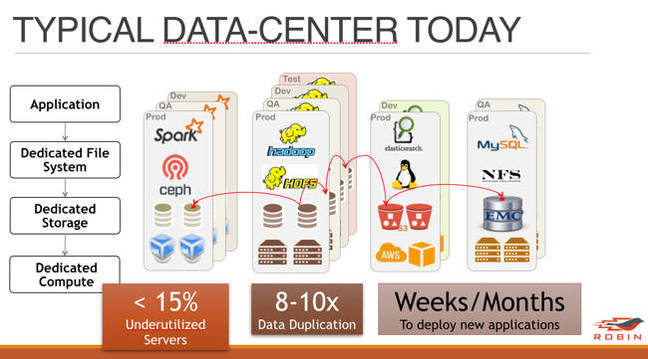
Technology background idea
Okay. It wants faster queries and data ingestion, compute and storage HW consolidation, and "dramatically faster deployments."
Now we're getting to the "how?"
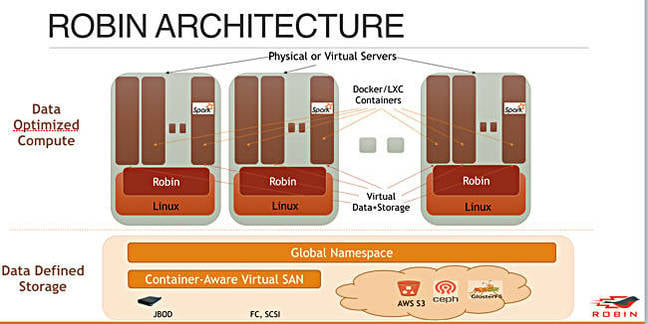
Its architecture and software, featuring more than a dozen patent-pending innovations, starts with data-optimized compute, including data-optimized cluster configuration and data-aware placement. Secondly, a data acceleration layer speeds app performance. Thirdly, data-defined storage uses a virtual storage pool, built from JBODs with Fiber Channel and iSCSI access. It is said to eliminate data duplication through a global namespace and tiering, with AWS S3, ceph, and the GlusterFS mentioned.
Clustered physical or virtual Linux servers run Docker or LXC containers. These access a Robin software layer about which we know little. The storage is RAID6-based and can be scaled independently from compute. Queries are accelerated using intelligent host-side SSD caching. Data can be shared across Hadoop clusters to cut out duplication.
That's all the "how " we are getting; not much is it? It will have to do.
Customer validation
Robin has a couple of unidentified customer examples showing it can deliver what it says it can deliver:
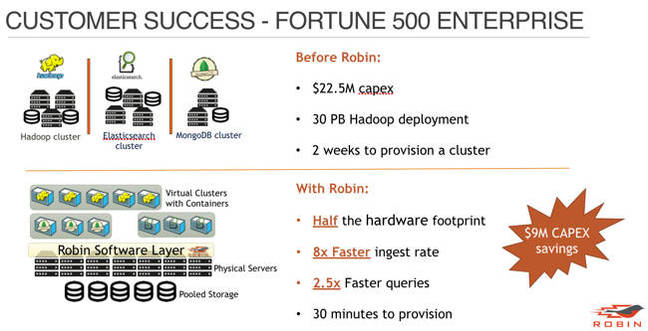
First customer example
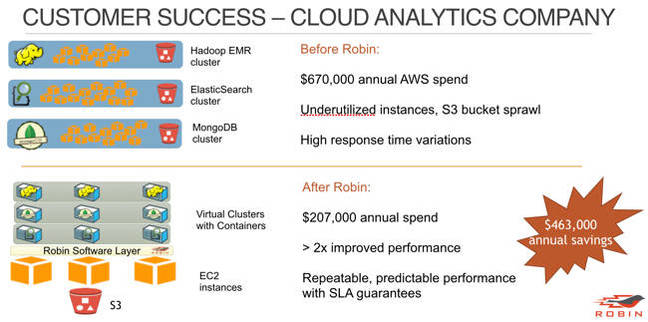
Second customer example
These seem solid enough, insofar as the outlines above are real.
Exec staff
Robin's chairman and founding investor is Rajeev Madhavan, said to be a serial entrepreneur and former founder of Magma Design Automation, which was acquired by Synopsis in 2012. Madhavan claims, "Companies are struggling with bloated hardware costs, data and cluster sprawl, and application performance problems. Robin Systems is uniquely positioned to relieve that struggle. We're excited to have the backing of a diverse group of investors who share our vision for revolutionizing data management."
It has also gained a new CEO, Premal Buch, and a number of other management staff. Buch joins Robin from Altera, where he was VP for Software Engineering. He previously spent 15 years with software company Magma Design Automation, Mafhavan's old company, where he eventually served as general manager of its largest business unit.
Other new execs include:
- Cheng Tang as VP of engineering. His background includes time at Oracle and Cisco.
- Sushil Kumar as VP of Marketing after 15 years with Oracle.
- Amir Assar, VP of Sales after a number of years with IBM.
There are some 40 employees overall.
An advisory board includes former Endeca CEO Steve Papa; Anand Rajaraman, founder of Kosmix and Junglee; Eric Baldeschwieler, founder and ex-CEO of HortonWorks; Fred van den Bosch, ex-CEO of Librato and ex-CTO of Veritas; Andrew Feldman, ex-CEO of SeaMicro; Manoj Leelanivas, CEO of Cyphort; and Ben Verghese, Engineering VP at Illumio.
The new cash will be spent on further developing its technology "to reinvent the infrastructure for modern data and applications."
Robin's software for enterprise on-premises private clouds, for 100s-to-1,000s of nodes, is available now with $/GB-based pricing. Cloud-based software is coming by the end of the year, targeting public cloud IaaS users with 10s-to-100s of nodes and pricing based on a percentage of AWS savings.
Its website is here if you want to dig a little further.
What we have here is a software technology concept with promising initial customer validation for use in the Big Data world. It's attracted funding to develop this technology, better productize it we might say, and show what it can do.
The fresh funding is buying a raft of execs to grow the company and some serious product development. Expect energetic marketing as it raises its profile and starts looking for partners, we guess, to sell its wares. This Robin wants to start singing so everyone can enjoy its song. ®
