This article is more than 1 year old
Memory and storage boundary changes
Two transitions starting that will radically speed up storage
Analysis Latency is always the storage access bête noire. No one likes to wait, least of all VMs hungry for data access in multi-threaded, multi-core, multi-socket, virtualized servers. Processors aren't getting that much faster as Moore's Law runs out of steam, so attention is turning to fixing IO delays as a way of getting our expensive IT to do more work.
Two technology changes are starting to be applied and both could have massive latency reduction effects at the two main storage boundary points: between memory and storage on the one hand, and between internal and external, networked storage on the other.
The internal/external boundary is moving because of NVMe-over-fabric (NVMeF) access. How and why is this happening?
Internal:external storage boundary
Internal storage is accessed over the PCIe bus and then over SAS or SATA hardware adapters and protocol stacks, whether the media be disk or solid state drives (SSDs). Direct NVMe PCIe bus access is the fastest internal storage access method, but has not yet generally replaced SAS/SATA SSD and HDD access.
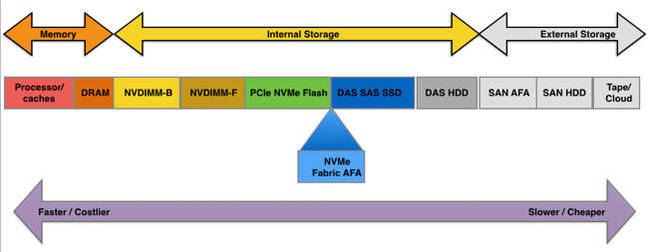
Memory and storage access latency spectrum, with NVME fabric-accessed arrays positioned
To get access to much higher-capacity and shared storage we need networked external arrays, linked to servers by Fibre Channel (block access) or Ethernet (iSCSI block and/or file access). Again, we'll set object storage and Hadoop storage off to one side, as we're concentrating on the generic server-external storage situation.
Network-crossing time adds to media access time. When hard disk drives (HDDs) were the primary storage media in arrays, contributing their own seek time and rotational delays to data access time, then network delays weren't quite so obvious. Now that primary external array storage is changing to much faster SSDs, the network transit time is more prominent. Although Fibre Channel is now moving to 16Gbit/s from 8Gbit/s, and Ethernet is moving from 10GbitE to 25 and 40GbitE, the network delay is doubled, because the accesses involve a round trip.
InfiniBand could speed things up but is expensive and, beside the latest technology, still slow. That technology involves externalizing the PCIe bus and running the NVMe protocol across an Ethernet fabric, or its equivalent, to the external array.
NVMeF access latencies are 200 microseconds or less. To put that in context, we've constructed this latency table from various sources, ranking media access from the fastest to pretty darn slow:
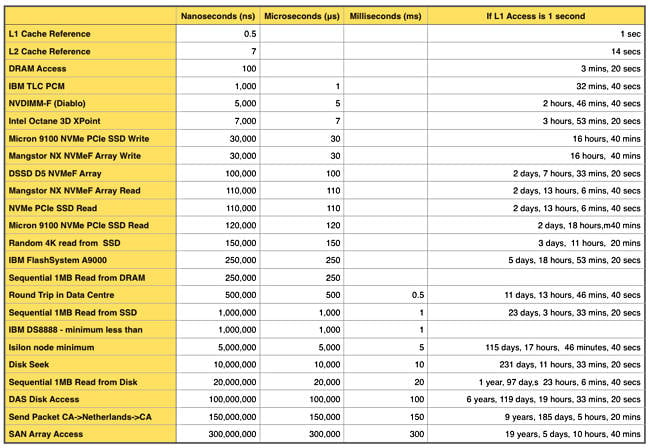
It looks precise but the numbers are rough and ready, and serve to indicate the relative increases in access delay as we progress from L1 CPU cache access down the table to SAN array access.
The rightmost column puts this in an everyday context, normalizing an L1 cache access to 1 second and then putting everything else on the same scale as this. So an L2 access takes 14 times longer, meaning 14 seconds, and DRAM access takes 400 times longer: 6 minutes and 40 seconds. An NVMe PCIe SSD write takes 60,000 times longer than an L1 cache access, 30,000 nanoseconds, which sounds incredibly quick, or 16 hours, 40 minutes on our L1-cache-takes-1-second scale, which sounds incredibly slow.
Look at the SAN access: 300 msecs, which is 19 years, 5 days, 10 hours and 40 minutes on our L1-cache-is-1-sec scale. A DAS disk access takes less than half that, 100 msecs, while an NVMe fabric access takes just 30 microsecs for a write and 100 microsecs for a read.
That's over an NVMe link based on externalizing the PCIe bus, InfiniBand or Ethernet hardware and using RDMA access. To put that in relative terms, an NVMeF write takes 16 hours and 40 minutes and a read 61 hours, 6 minutes and 40 seconds.
The microsecond NVMeF read/write numbers are pretty similar whether DSSD D5 or Mangstor NX arrays are used.
This access latency difference between a Fibre Channel or iSCSI-connected SAN and an NVMeF-connected equivalent (what DSSD calls shared DAS) is so extraordinarily large that several suppliers are developing products to blow traditional SAN array access times out of the water. These include DSSD, E8, Mangstor and Mangstor partner Zstor.
The memory:storage boundary
The memory storage boundary occurs where DRAM, which is volatile or non-persistent – data being lost when power is turned off – meets storage, which is persistent or non-volatile, retaining its data contents when power is turned off.
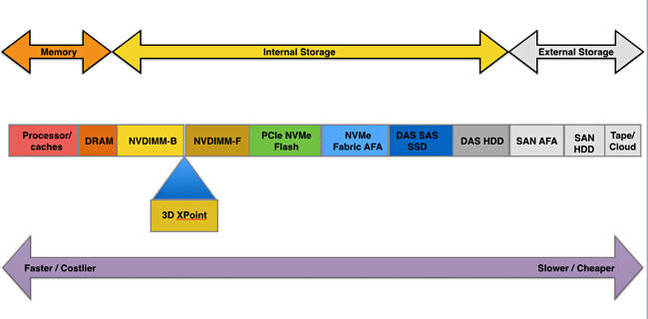
NVDIMM-Bs are memory DIMMs with flash backup, hence they have memory access speed
There is a speed penalty here, as access to the fastest non-volatile media, flash, is very much slower than memory access (0.2 microsecs vs 30/100 microsecs for read/write access to NVMe SSD.)
This can be mitigated by putting the flash directly on the memory bus, using a flash DIMM (NVDIMM‑N), giving us a 5 microsecond latency. This is what Diablo Technology does, and also SanDisk with its ULLtraDIMM. But this is still 25 times slower than a memory access.
Intel and Micron's 3D XPoint technology is claimed to provide much faster non-volatile storage access than flash. The two say XPoint is up to 1,000 times faster than SSD access but not as fast as DRAM, but they don't supply actual latency time.
OK, let's say an average SSD (non-NVMe) has a roughly 200-microsec latency. Dividing that by 1,000 gives us a 200-nanosec latency, the same as DRAM – obvious bollocks, and Intel/Micron are clearly comparing XPoint to some horrendous old dinosaur of an SSD to get their 1,000 multiplier.
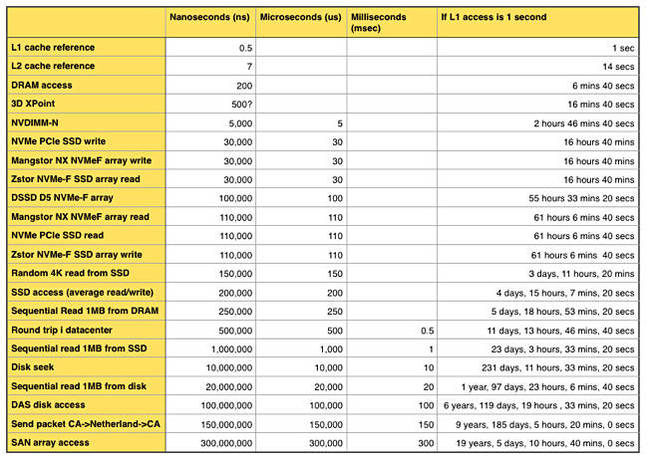
Updated latency table with 3D XPoint and non-NVMe SSD access added
So let's say XPoint has a 500-nanosec latency, apply the 1,000 multiplier and say the comparison SSD has a latency of 500 microsecs: yep, dinosaur SSD technology territory for sure. Repeat after me: "We LOVE marketing-droids."
Anyway, IF XPoint lives up to its billing, the memory:storage boundary moves left on our spectrum and, application software developers willing, gets another significant boost in the speed of applications – the ones that use XPoint that is.
After XPoint there may be some other new technology, such as spin-torque memory or whatever HP's memristor finally turns out to be, that will move this boundary further to the right again.
Are these two storage boundary movements described here really happening?
In El Reg's storage desk judgement, yes. They will take time, and face technology challenges, but the radical decreases in data latency they promise to deliver are so huge that their coming is inevitable. ®
