This article is more than 1 year old
Memory-based storage? Yes, please
Just a few compromises first
Comment Memory-based storage? Yes please, And I'm not talking about flash memory here; well, not in the way we usually use flash, at least.
I wrote about this a long time ago: in-memory storage makes sense. Not only does it make sense now, but it's becoming a necessity. The number of applications taking advantage of large memory capacity is growing like crazy, especially in the Big Data analytics and HPC fields, and in all those cases where you need large amounts of data as close as possible to the CPU.
Yes, memory, but not for everyone
We could argue that any application can benefit from a larger amount of memory, but that's not always true. Some applications are not written to take advantage of all the memory available or they simply don't need it because of the nature of their algorithm.
Scale-out distributed applications can benefit the most from large memory servers. In this case, the more memory they can address locally, the less they need to access remote and slower resources (another node or shared storage, for example).
Compromises
RAM is fast, but it doesn't come cheap. Access speed is measured in nanoseconds but it is prohibitively expensive if you think in terms of TBs instead of GBs.
On the other hand, flash memory (NAND) brings latency at microseconds but is way cheaper. There is another catch, however – if it is used through the wrong interface it could become even slower and less predictable.
Intel promises to bring more to this table soon, in the form of 3D Xpoint memory, a new class of non-volatile storage which will have better performance than flash, persistency and a competitive price point (between flash and RAM). But we're not there yet.
In any case, this entire game is played on compromises. You can't have 100 per cent RAM at a reasonable cost, and RAM can't be used as a persistent storage device. There are some design considerations to take into account to implement this kind of system, especially if we are talking about ephemeral storage.
Leading-edge solutions
I want to mention just two examples here: Diablo Technologies Memory1 and PlexiStor SDM.
The first is a hardware solution; a memory DIMM which uses NAND chips. From the outside it looks like a normal DIMM, just slower – but a DIMM none the less (as close as possible to the CPU).

A special Linux driver is used to mitigate the speed difference, through a smart tiering mechanism, between actual and "fake" RAM. I tried to simplify as much as I could in the table above, but the technology behind this object is very advanced (watch this SFD video if you want to know more) and it works very well. Benchmarks are off the charts and savings, by using fewer servers to do the same job in less time, are unbelievably good as well.
PexiStor has a similar concept but it is implemented as a software solution. NVMe (or slower) devices can be seen as RAM.
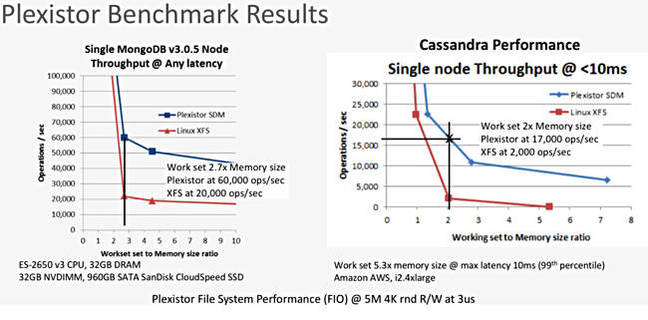
Once again, this is a simplification, but it gives the idea. Performance is very good and overall cost is lower than for the Diablo. Since this is only software, you can run it in an AWS flash-based EC2 instance, for example. And the other good news is that the software is free – at the moment. The bad news lies in the maturity of the product; but I'd keep an eye on Plexistor because the concept is really appealing.
It's clear that looking at the level of sophistication, maturity and performance predictability, these two products target two different types of end users at the moment, but they are equally interesting from my point of view.
And the rest of us?
Large memory servers started as a point solution to speed up access to traditional storage, when flash memory was absurdly expensive. It is now becoming an interesting feature to do the same thing when large-capacity storage systems are involved (scale-out NAS and object storage, for example).
Not all applications can take advantage of large memory servers, and caching is still a good option.
It is less efficient, but has similar benefits to the ones described above, while it's easier and cheaper to implement. An example? Take a look at Intel's CAS software. It comes free with Intel flash drives and has some really neat features. The benchmark Intel has shown at the last Tech Field Day, regarding the usage of CAS in conjunction with Ceph, is quite impressive.
Closing the circle
Data growth is hard to manage, but these solutions can really help to do more with less. Moving data closer to the CPU has always been crucial, now more so than ever, for at least three reasons:
- CPUs are becoming more and more powerful (latest best-of-breed Intel Broadwell CPU, launched last week, has up to 22 cores and 55Mb cache) and I'm sure that you want to feed those cores at full speed all the time, right?
- Capacity grows more than everything else. Low $/GB is essential and there is no way to use all-flash systems for everything. In fact, it's still quite the contrary; if flash is good for solving all primary data needs now, it's also true that all workloads that involve huge amounts of data are still on other (slower) forms of storage. Once again, multiple tier storage is not efficient enough (HDD-flash-RAM, too many hops to manage). It's better to have very-cheap (relatively) and ultra-fast local memory.
- As a consequence of 1 and 2, it's more common now to have large object stores and compute clusters at a certain distance from each other in a multiple or hybrid cloud fashion (look at what you can do with Avere, for example). In this scenario, since network latency is unavoidable, you'd better have something to bring data close to the CPU and, again, caching and ephemeral storage are the best technologies for this at the moment. ®
