This article is more than 1 year old
Scale Computing is a tiny fish in a small pond. Fancy its chances?
It's a small hyper-converged world... and EMC swims nearby
Comment Scale Computing is one of 13 suppliers attacking the hyper-converged infrastructure market. Not all will survive. What has it got that makes it distinctive and gives it the potential for success?
Scale’s difference is based on its SMB customer approach, meaning low-cost and simplified admin, and cleaned up IO stack.
This, it says, will give it the business strength need to grow into a big company, because no other supplier can match its product’s performance, ease of administration and affordability for small and medium businesses (SMBs).
The company was founded in 2007, and incorporated in 2008, by three guys who had sold a previous, startup for $43.5m. That had been their second startup. Scale is their fourth. The founders are CEO Jeff Ready, CTO Jason Collier and Engineering VP Scott Loughmiller.
They figured that the average vSphere virtualised server had an incredibly complicated, multi-layered IO stack that just sucked up CPU cycles and time to traverse. Secondly they thought it was too complicated and expensive for SMBs or their resellers to select, integrate, deploy, operate and scale IT systems based on separate server, storage, switch and system software components.
Thirdly, the VMware tax was significant.
Here are the top line hyper-converged appliance suppliers:
- Atlantis
- Cisco (with SpringPath)
- DataCore
- Dell
- EMC
- HPE
- Gridstore
- Lenovo via SW partners
- Maxta
- Nutanix
- Pivot3
- SimpliVity
- VMware
That's a lot of competition, and with better second generation products coming from EMC and HPE, as well as wide, meet-in-the-channel partnerships with Cisco and Lenovo and their HCIA software suppliers. How can Scale withstand this marketing blitzkrieg?
As an example of CPU cycle sucking and time-wasting Scale characterises UI/O in a VSA (Virtual SAN Appliance) approach like this; application->RAM->Disk into application->RAM->hypervisor->RAM->SAN controller VM->RAM->hypervisor->RAM->write-cache SSD->Disk.
Often, a Scale blog claims, “this approach uses so much resource that one could run an entire SMB data centre on just the CPU and RAM being allocated to these VSA’s.”
Wouldn’t it be better to hit these three nails on the head with one hammer, a clusterable hyper-converged, scale-out system with a KVM hypervisor and a much-slimmed down IO stack? Yes, they said, and set about building it.
Cleaned-up IO stack
The HC3 system runs a KVM-based bare metal HyperCore hypervisor and has the SCRIBE (Scale Computing Reliable Independent Block Engine ) storage layer. This is designed to be used by HyperCore directly. It discovers all block storage resources in an HC3 cluster and aggregates it it into a pool, which is not a virtual SAN, with block-level accessibility by HyperCore.
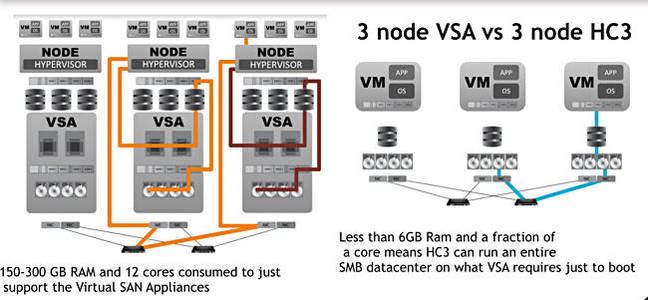
Scale’s comparison of VSA and HC3 IO paths
There are no intervening storage protocols, no file systems, no virtual hard disk files, and SCRIBE is not running as a virtual machine or a virtual SAN or as a controller VM. It is a set of kernel modules inside the hypervisor, “allowing direct data flows to benefit from zero-copy shared memory performance” as a Scale backgrounder states.
As a result: “HC3 VMs are able to access their virtual disks directly as if they are local disks, without the use of any SAN or NAS protocols, regardless of which node the VM is running on at the time.”
SCRIBE allocates storage in chunks ranging from 512 bytes to 1MB. Two or more copies of every chunk are written to the storage pool in a way to create a RAID 10 level of redundancy, and use wide striping as a way to aggregate the I/O and throughput capabilities of all the individual disks in the cluster.
Scale says: “HC3 is able to use wide-striping to distribute I/O load and access capacity across the entire HC3 cluster, achieving levels of performance well beyond other solutions on the market with comparable storage resources and cost.”
Scale thinks it gets a more than 60 per cent efficiency gain from this IO stack clean-up, this elimination of nested files on filesystems.
Scale's chief technology guy and evangelist Jason Collier told us an all-disk HC2100 3-node cluster puts out about 3,000 sustained IOPS (4KB blocks, queue depth of 1, 33:67 read:write mix), while the hybrid HC2150 puts out around 31,000. There is a 1.8X price differential between the two systems with their 10X performance differential.
The Reg reviewed Scale’s kit here, before the flash-enchanced HC2150 and HC4150 nodes came along, and found it suffered no performance impediment whatsoever compared to other HCIA-type nodes with beefier Xeons and VMware or Hyper-V.
Scale has only now introduced hybrid flash/disk nodes (with SLC flash), saying that, up until now its disk-only nodes combined with its efficient IO stack made node performance high enough not to need flash, either as a cache or as a storage tier.
Funding and sales
Scale has had steady funding. Here’s the timetable for that:
- 2007 - started up
- 2008 - incorporated
- 2009 – Two part A-round of $3m and $2m
- 2010 - B-round of $9m and C-round of $17m
- 2012 - $12m D-round and first product launched
- 2014 - undisclosed E-round
- 2015 - $18m F-round
Total funding has passed $63m. It is approaching 1,600 customers, has sold more than 5,500 systems, and has 100 employees. Part of the benefit of the 2015 funding round was, we think, the development and launch of the hybrid HC2150 and 4150 nodes.
Collier said Scale has all-flash nodes in its lab and was tight-lipped about them, but smiled a lot when asked about performance and cost.
El Reg's view
Scale Computing is differentiated by its SMB-directed product, closely integrated software stack, affordability, ease of use and admin, and performance. With 5,500 systems in the field and 1,500+ customers gained in three years then it has found a market niche that is huge (how many SMBS are out there?) and ill-served by other suppliers with more expensive (very) and complex products offering no performance advantage. ®
