This article is more than 1 year old
ARM Cortex-A73: How a top-end mobe CPU was designed from scratch
RISC-taking bods branch out with new low-power, high-performance ideas
Analysis For its latest top-end smartphone processor core – the Cortex-A73 – ARM designed its microarchitecture more or less from scratch.
Whereas its predecessor, 2015's Cortex-A72, was drawn up in Austin, Texas, the new A73 microarchitecture was designed by a team in France, starting about three years ago. Although we're told the French engineers began with a blank canvas, the 64-bit A73's design is, in various ways, inspired by the Cortex-A17, ARM's highest-performance 32-bit core.
While the microarchitecture is new, the A73 features the usual ARMv8-a instruction set, so from an application programmer's point of view, code will execute as expected. By looking at the A73's blueprints, though, we get a glimpse into the world of modern CPU design.
First of all, the headline changes for the A73: it's expected to appear in phones using chips made out of 10nm FinFETs early next year, although some manufacturers may stick to 16nm or 14nm gates for some of their A73-based system-on-chips. A 10nm A73 core is a little less than 0.65mm2 in size, making it ARM's smallest ARMv8-a core, allowing the architecture to keep up with the demand for thinner and thinner phones. Smaller chip equals thinner phone, hopefully.
When you compare a 16nm FinFET A73 to a 16nm FinFET A72, ARM reckons you'll get a 15 per cent increase in performance and 15 per cent increase in power efficiency from the new core, based on the microarchitecture rewrite. When you dial down the process node to 10nm – that is, compare a 10nm A73 to a 16nm A72 – performance and power efficiency should each increase by 30 per cent.
So, assuming a system-on-chip fabricator takes advantage of the 10nm node, half the performance boost will come from the smaller gate size and half will come from the redesign, we're told. That's the sort of performance upgrade that's awaiting next year's A73-based smartphones.
Bear in mind Apple and Samsung design their own ARMv8-compatible CPU cores for their own phones, and are unlikely to be using the A73 off the shelf for their next iPhones and Android gadgets. However, ten chip outfits including HiSilicon, Marvell and Mediatek have licensed the A73 blueprints, so the new processor brains will make their way into devices, one way or another.
Four of a kind
The A73 cores can clock in at up to 2.8GHz. Up to four A73s can be clustered alongside up to four Cortex-A53 cores for system-on-chip in a beefy device, or up to four Cortex-A35 cores for a mid-level gadget. We could even see hexa-core designs, with two A73s and four A53s, which would have the same footprint as an octo-core A53, according to ARM.
The A53 or A35 siblings are expected to run lighter tasks, and the A73s are powered up when more work needs to be done by the device. The architecture (ARM's big.LITTLE) can juggle workloads across these different cores: it's not an all or nothing approach with apps either running on the more powerful core cluster or the less powerful one. The operating system should be able to schedule some threads for the fat cores and other threads for the non-fat cores.
When you want to throttle your phone...
Speaking of which, when software running on the device is motoring hard, and utilizing as much of the cores as it can, the processor is going to start getting warm. Unlike like a server or desktop CPU, the mobile system-on-chip can't spin up a fan to cool itself, so to avoid a fiery pocket meltdown situation, it has to throttle back its power consumption, by dialing down the clock frequency of the fatter cores, which then hits performance.
Previous cores have distinct peak and off-peak states: peak being when the chip is giving its all, delivering top performance while also getting hot and power hungry, and off-peak being, well, when the chip is running normally. Since most of the time, people pull out their mobes just to flick through Twitter or check their messages or read El Reg (cough), the workload stays relatively low.
If there's a big demand for performance, the SoC can only run in peak mode for a short amount of time before the owner gets burned or the battery dies, so ideally you want to stay running out of peak mode for as long as possible while still getting the job at hand done.
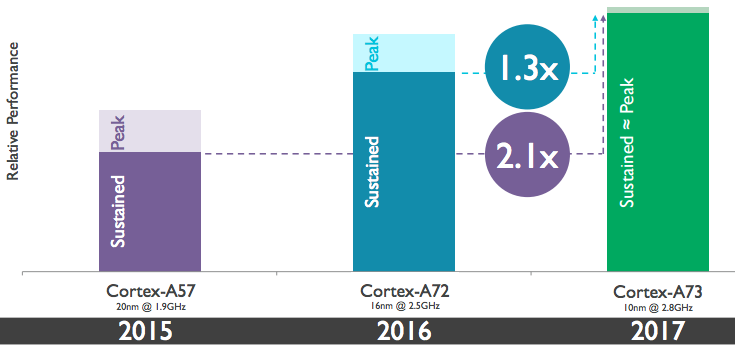
ARM reckons its A73 can stay in out of peak mode for much longer, drawing 750mW per 2.8GHz 10nm FinFET core and achieving twice as much performance as a 20nm 1.9GHz A57 or a third more performance over a 2.5GHz 16nm A72, before kicking into a peak setting.
The bottom line for smartphone owners is less throttling and more sustained performance per milliwatt, compared to previous Cortex family members. That means fewer frames dropped and fewer delays while processing big streams of information. This is expected to suit demanding apps like augmented and virtual reality software, if those games ever hit the mainstream, which will constantly tax the CPU and GPU cores while running.
What's new
So, why the redesign? It's pretty logical when you think about it: if you come up with a new and more efficient way of organizing some of the core's inner systems, given the complex nature of CPUs, it's a lot easier to start again with the improvements in mind, than to bolt on new circuitry or jury-rig them in place.
"It's not dissimilar to the car industry, where we’ll see Audi or BMW design a new car every six years," Peter Greenhalgh, ARM's director of technology, told The Register.
"You need to rewrite your microarchitecture when you've had ideas everywhere across the design. It's the best way to bring them all together: decisions you’ll make at the front-end have implications to the back-end."
For example, the A73 organizes its registers into one generic register file, rather than having separate banks for its general-purpose and NEON registers like the A72 uses. This approach streamlines the register renaming and flow of instructions into the issue queues, which makes a "fundamental difference in out-of-order execution," Greenhalgh said.
It gives the processor more flexibility in identifying register dependencies in code and removing them when executing instructions in parallel. If the CPU works out that, for example, code running in a loop isn't going to directly affect what happens next, then bam: it can be parallelized.
Ultimately, this reduction in complexity of the register remapping stage helps increase performance and lowers power usage by the core.
Another interesting change in the A73 is the use of a two-wide instruction decode stage, rather than the three-wide stage in the A72. The A73 has a four-stage fetch unit that feeds program instructions into a decode stage. This unit splits the incoming code into two separate flows of micro-operations that feed into the register rename and dispatch stages, which feed through into four issue queues, and then into seven lanes of execution circuitry, with each lane handling a different family of instructions (one lane does branch instructions, another a subset of integer operations, and so on.)
The A72 decodes instructions into three separate streams, but this was determined to be perhaps a little overkill for software typically running on mobile phones. A two-wide decode stage, Greenhalgh told us, provides a good-enough balance of efficiency and performance.
The name of the game is to reduce complexity, reduce die area and reduce power usage while improving performance. By reducing power usage, not only do batteries last longer, but it means handset designers can squeeze in more complex cameras and other peripherals without blowing the device's energy budget.
Mobile apps and browsers tend to touch a lot of memory, and are essentially data pumps pushing information around rather than performing large amounts of math (the graphics calculations are done in the GPU). As such, Greenhalgh said, the A73 team has "written a very high-performance memory system capable of sustaining a higher bandwidth than the A72," and RAM attached to the cores can be organized in a more power-efficient manner.
While on the subject of workloads: branching. Mobe apps tend to bounce around their application space an awful lot, jumping from code block to code block. One way to maximize performance is to predict, on the fly, where the program flow is going to go next: will a comparison between two values make the code branch off to some other routine, or continue on? By predicting the program flow, instructions can be fetched speculatively after the branch and lined up ready for execution, rather the core's pipeline stalling because it's not known whether a branch will be taken or not.
Just take a typical function in WebKit, the engine that powers Safari on iOS and OS X: RenderView::layout(). It makes lots of little decisions, even decisions in a loop, which will require lots of branching, and predicting where these will go – especially in the loop – is essential to maximizing performance.
A disassembly of RenderView::layout() reveals the jumpy nature of apps typical on mobile devices – click on the screenshot for the full flow. (Yes, it's the x86 disassembly of Safari on OS X but it won't be too dissimilar to an ARMv8-a build on a phone.)
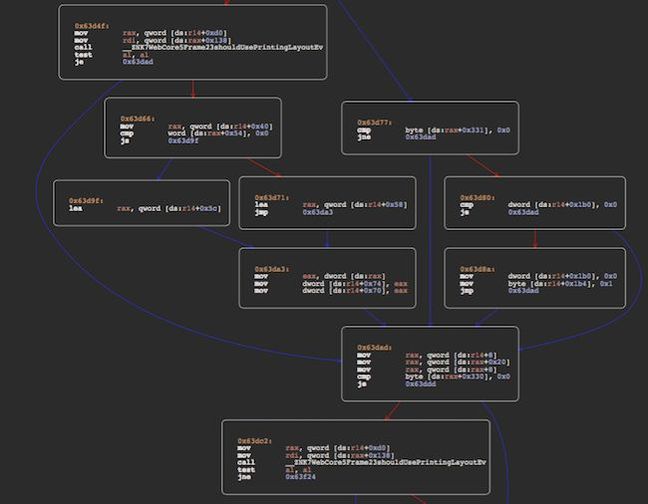
ARM's branch predictor, simply put, works by keeping count of the number of times a branch is taken. If the count is high, the core can assume this jump will occur the next time. If the count is low, the core can assume the jump is rarely taken. In a loop, for example, the CPU will quickly realize a jump to the start of the loop is regularly taken, and only the final check when the loop is over will miss its prediction.
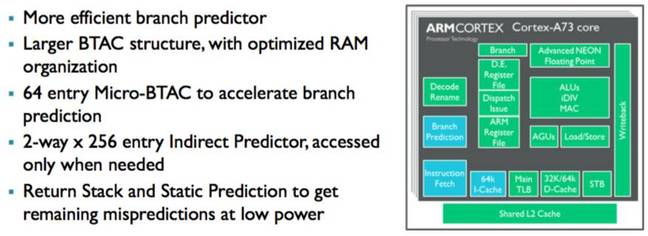
The A73 has a rewritten branch predictor, and a large branch target address cache (BTAC) that keeps a record of where branches end up, as well as other optimizations, all chosen to make the most of typical apps that run on phones. The mechanism has been designed to cope with typical smartmobe apps, allowing them to run as smoothly as possible.
"The application environment does stress the branch predictors heavily," said Greenhalgh. "With the A73, we've invested a lot of time in the branch prediction to make it as efficient as it possibly can be."
Since the A73 is designed to maintain sustained performance for things like augmented reality apps, how does that affect the predictor design – will program flow prediction tuned for web browsers and typical phone apps optimize next year's augmented reality (AR) tools and games?
"It’s hard to tell, largely because it's a new area and the apps are changing quite rapidly. We haven’t got a AR benchmark yet because it’s so new," said Greenhalgh. "What we're hearing from our partners is that AR application environment does map to web browsers, so we're seeing similar performance."
As an aside, Greenhalgh said ARM's mobile cores, even its 64-bit ones, will not drop their 32-bit (AArch32) mode for a long while because there's still plenty of apps out there that are 32-bit only. Some makers of 64-bit ARMv8-compatible (AArch64) server-grade cores may well drop 32-bit mode, but that's up to them.
"In deeply embedded products or in the server world, we will increasingly see AArch64-only," Greenhalgh added.
Since we're getting into the weeds now, here's the more gory details of the microarchitecture.
