This article is more than 1 year old
Wow, still using disk and PCIe storage? You look like a flash-on victim, darling – it isn't 2014
Server slingers, like models, it's OK to be DIMM
Comment For generations of PowerEdge, ProLiant, UCS and other x86 servers, the future has been fairly simple: more powerful multi-core processors, more memory, more PCIe bandwidth and shrink the space and electricity needs.
For example, a Gen8 ProLiant DL3603 server had 1 or 2 Xeon E5-2400/2400 v2, with 2/4/6/8/10 cores, and 12 x DDR3 DIMMs, up to 1600 MHz (384GB max). The replacement Gen9 ProLiant DL160 server uses 1 or 2 Xeon E5-2600 v3 Series, with 4/6/8/10/12 cores, and is fitted with 16 x DDR4 DIMMs, up to 2133 MHz (512GB max).
The hardware got better but the application and operating software didn’t have to change much at all, except down at detailed driver hardware interface levels, as Gen 8 ProLiant gave way to Gen 9 ones. Application code read data from persistent storage into memory, got the CPU cores to chew on it, and wrote the results back to persistent storage. Rinse, repeat, job done.
That is about to change.
The massive collective power of multi-core CPUs and virtualised server software means that apps are spending proportionately more time waiting for IO from persistent storage. There is also an increasing need for servers to work faster on larger chunks of data, with a desire to avoid the latency-intensive IOs to persistent storage.
The finger of latency blame is pointing at three places, and declaring:
- Disk is too slow for random data IO.
- Flash, though faster than disk, is still too slow for IO.
- The disk-based IO stack in an OS takes too much time and is redundant.
You can bring storage media “closer” to the server’s DRAM and CPU cores by directly attaching it, moving from disk to flash, and then moving from disk-based SATA and SAS protocols to PCIe with NVMe drivers, which improves matters, but not enough.
It takes too much time to read in data from PCIe flash to DRAM, and the data needs to be in DRAM or some other memory media in order for the CPU cores to get hold of it fast.
The answer that the industry seems to be agreeing on comes from the point of view that DRAM, although fast, is still too expensive to use at the multi-TB per server level. The answer is to put solid state storage on the memory channel using memory DIMMs and, although it is non-volatile, treat it as memory. Data is moved from NAND DIMM for example, to DRAM DIMM, using memory transfer load and store instructions, and not traditional slow IO commands via the operating system stack.
A SAS MLC SSD read takes roughly as little as 150 microsecs. An NVMe SSD read can take 120 microsecs. An NVDIMM-F read can take 5-10 microseconds, more than 10-20 times faster. Here is a chart of NVDIMM types:
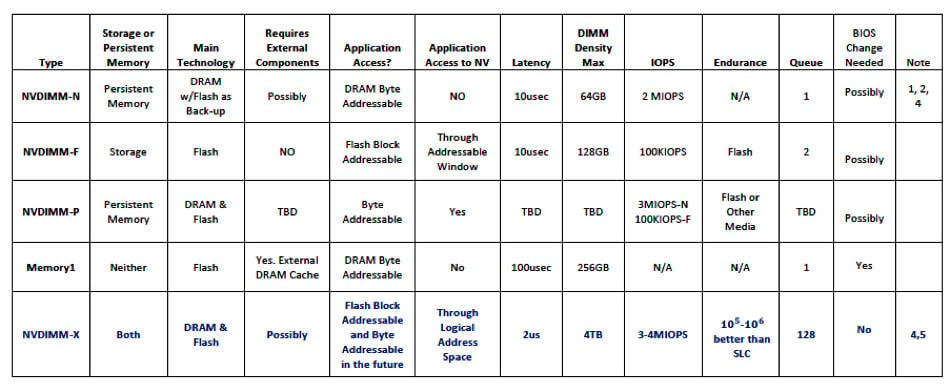
Xitore NVDIMM chart (click for larger version)
The Memory1 and NVDIMM-X (Xitore developing NVDIMM tech) data in the chart is not germane to the argument we’re pursuing here, so just ignore them.
Say an NVDIM-F takes 10 microsecs; that’s 10,000 nanosecs, and a DDR4 DRAM access can take 14ns, more than 700 times faster, and that is slow to a CPU with a Level 1 cache access taking 0.5ns. The latency needed for a PCIe SSD access: 30 microsecs for a write and 110 microsecs for a read, with Micron 9100 NVMe PCIe SSDs. This means that the Micron NVMe SSD takes 11 times longer than the NVDIMM-F to access data. (These figures are illustrative and specific product mileage may vary, as they say.)
Now bring post-NAND media into the equation, such as Intel and Micron’s 3D XPoint. It has 7 microsecs read latency, almost 16 times faster than the Micron NVMe SSD. And that’s in its initial v1.0 form.
These numbers are encouraging the non-volatile media and drive vendors to evangelise the idea of NAND and XPoint DIMMS (and other media such as ReRAM) to the server vendors. Your servers, they say, will be able to support more VMs and have those VMs run faster because IO waits can be side-stepped, by treating fast storage media as memory.
There is a need for system and application software to change so that it too stops issuing time-consuming IO commands and does memory load-store commands instead, as the NVDIMM non-volatile media can be addressed as memory, with byte-level and not block-level addressing.
Let’s imagine a Gen10 ProLiant server uses such NVDIMMs. It can’t do so until the operating systems support NVDIMM-style load-store IO, and until key system and application SW vendors, like web browser, database, mail and collaboration software vendors, support this new memory-style IO as well or are convincingly set on doing so.
HPE, and Cisco and Dell and other server vendors would have to understand what the ratio of NVDIMM to DRAM capacity would have to be. They would need to be able to calculate the ratio of such NVDIMM capacity to PCIe flash and SAS/SATA disk capacity, and all this means running test workloads through prototype systems, analysing the results and optimising system components to balance performance, power draw, temperature and cost.
The development of the next generation of servers is going to become much more complex than that of the existing generation, as all this NVDIMM-related hardware and software complexity gets added on to the development of the expected and generally well-understood and traditional CPU, DRAM, IO adapter, etc, developments. We can expect Intel to throw FPGAs from its Altera business into the mix as well, to speed specific application workloads.
Server vendors have a hard development job to do, but if they get it right, much more powerful servers should result, and we’ll all like that. ®
