This article is more than 1 year old
Zeta Systems: NVMe over Fabrics speed is real... and here's why
NVMe over fabrics vs direct NVMe drive = little difference
Analysis How does local NVMe drive access compare to accessing the same drive over an NVMe over Fabrics link? Zeta Storage Systems has compared the two access methods and found... not a lot of difference at all.
Zeta’s Lee Chisnall, its CNO (Chief Nobody Officer – think storage product management and marketing) says: “I think that is what sysadmins really want to know: how many IOPS do I lose by running the NVMe devices over a network?”
The test rig had two Supermicro-based Xeon CPU E5-1620 v4 @ 3.5GHz systems with 16GB of RAM – one used as an initiator and the other as a target. The NVMe drive was an Intel DC P3700 / 400GB / PCIe card. One test was run over 40Gbit Ethernet using a Mellanox ConnectX-3 Pro MCX314A-BCCT card on both initiator and target, and a second with InfiniBand using Mellanox’s ConnectX-3 MCX354A-FCBT adapter, again at both ends of the link.
The two Supermicros ran Linux with a 4.8-rc8 kernel and the FIO test involved Version 2.13, runtime 2, 1-4 workers, 32 queue depth, run 20 times and then averaged.
The testing involved running NVMe natively over RDMA network with no iSER or SCSI at all. The initiator sees the NVMe device as the same as a local NVMe and not a SCSI LUN:
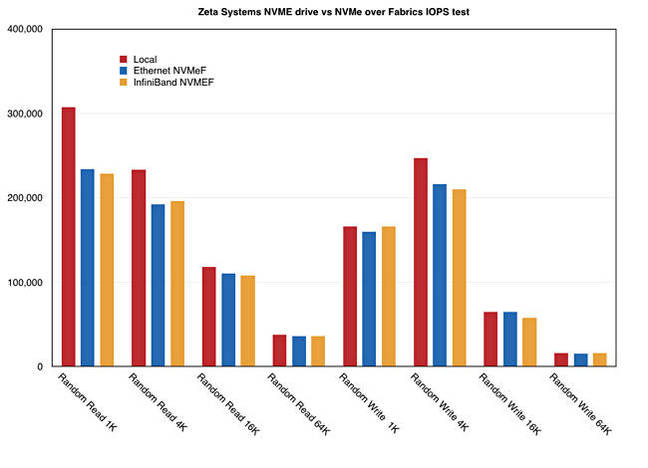
Chart comparing direct NVMe drive access and NVMe over Fabrics access
Local random read drive access with 1KB blocks is faster than the RDMA over either InfiniBand or Ethernet, but the difference was less with 4K blocks, almost vanished with 16K blocks and was virtually non-existent with 64K blocks.
The random write situation was different with some local drive superiority with 4K blocks and virtually none with 1K, 16K and 64K blocks. Also writing 4K blocks was faster than writing 1K ones.
Chiswell points out:
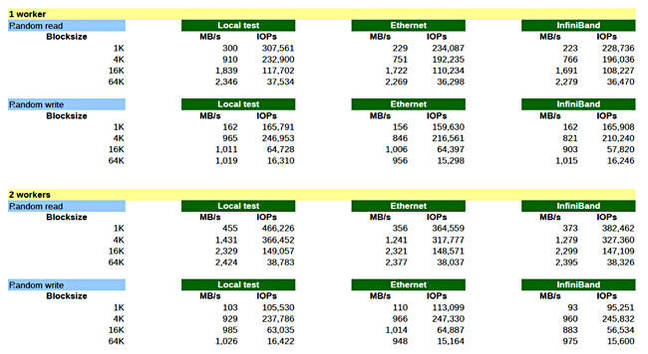
- With a single worker at 1K blocksize, random read performance is around 75 per cent of native
- With a single worker at 64K blocksize, random read performance is around 93 per cent of native
- With 4 workers, random read performance is near native – around 99.4 per cent
- Ethernet is basically matching InfiniBand once you look at the total overall performance from all tests
He says: “The Ethernet performance really surprised me. I was not expecting it to match InfiniBand.”
Also: “While there is more bandwidth in the InfiniBand adapter we used (54.3 vs 40), the NVMe device is not capable of getting anywhere near that level of performance, so the Ethernet bandwidth is not an issue in this test. It would be in a test which features higher performing NVMe.”
Here is the full table with both IOPS and MB/sec listed, and 1 and 2 users active:
Chiswell tells us: “I believe we are the first vendor with a software-defined storage product (that runs on commodity hardware) that will have support for an NVMeF target. We have it working internally with a release scheduled at the end of October. It will be a standard feature in our Zetavault product with management in the web GUI.
“We already have support for NVMe where you can create volumes from an NVMe device(s) and export them as SCSI LUNs over iSCSI, iSER, SRP and FCP. NVMeF will be an alternative way to export the NVMe storage to initiators.”
He believes that “NVMeF will be a commodity technology, without the need to buy expensive boxes. Just run it on Dell/HP/Lenovo/Supermicro boxes.” ®
