This article is more than 1 year old
DeepMind boffins are trying to help robots escape The Matrix and learn for themselves in the real world
It's hard being human
Google DeepMind is trying to teach machines human-level motor control using progressive neural networks – so that the robots can learn new skills on-the-go in the real world.
The idea is to build droids that can constantly learn and improve themselves, all by themselves, from their own surroundings rather than rely on lab-built AI models created in simulations. Wouldn't it be great to have machines that each learn as individuals rather than all have a common copy of an updated model uploaded to them from the lab?
DeepMind's paper titled Sim-to-Real Robot Learning from Pixels with Progressive Nets appeared on arXiv last week, but it was overshadowed by another DeepMind paper in Nature.
"Progressive neural networks offer a framework that can be used for continual learning of many tasks and which facilitates transfer learning, even across the divide which separates simulation and robot," the paper's boffins state.
Simply put, London-based DeepMind has found a way to transfer knowledge from one AI model to another, so that software can efficiently learn how to perform tasks in simulations and continue learning in the real world as opposed to being trained purely in a dream world.
This software can therefore learn how to tackle situations that were not previously simulated, or learn how to use a particular skill to solve a seemingly unrelated problem.
DeepMind is very keen on what's called deep reinforcement learning – a trendy approach in AI at the moment in which a system is trained by letting it try out lots of different methods, earning a reward every time it improves.
That's fine in a fast-paced simulated world – where you can try thousands of attempts a second – but not so much when you're physically moving a robot around and learning from mistakes in the real world. It takes time for motors to move. A more efficient method of learning is needed, and some way to move knowhow out of a simulation and into the physical world.
So, DeepMind is trying to transfer knowledge gained from a simulation-taught deep reinforcement model to a progressive neural network. The progressive network operates Jaco, a real-world robot arm.
Jaco's job is to look for an object in front of it and learn how to successfully pick it up. It takes visual information from a camera and tries to make the right decisions to grab the widget before it. The better the robot does, the more it is rewarded with points and the idea is to get as many points as possible; that's how the AI model learns through reward. If you want to be a little cynical, it's sort of like brute-force training with treats. It's how DeepMind made its video-game playing AI.
Converting this input image data into an output movement of Jaco – something DeepMind calls “pixel-to-action” – is tricky. It requires a lot of attempts and training time, as well as robustly built robots able to withstand the repeated movements.
Algorithms used in deep reinforcement learning have been effective at demonstrating good control of movement, but it has largely been used only in simulations. Now comes the tricky task of bringing that simulation-taught knowledge to the real world.
In order to prime the real-world AI model with knowledge from a simulation-taught model, the researchers connected columns in the simulation-trained neural network to columns in the real-world robot-trained AI. This splices the lab-taught brain onto the reality-based mind, giving it enough knowhow to get going with plenty of opportunity to learn new tricks in its physical environment.
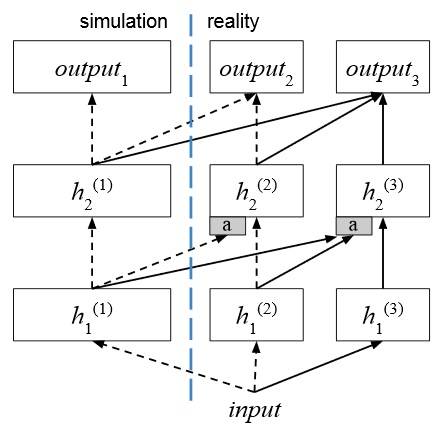
How progressive networks are used for simulation-trained and robot-trained data (Illustration by DeepMind)
During the physical training phase, after the two AI models are hooked up, if the robot arm manages to reach its target to within 10cm (4in), it is awarded a point, for example. An agent is considered good if it scores 30 points in 50 steps.
To train with Jaco, a target is randomly positioned within an area of 40cm by 30cm (16in by 12in) and about 60,000 steps are attempted.
It is not as easy as it sounds. “The progressive second column gets to 34 points, while the experiment with fine tuning – which starts with the simulation-trained column and continues training on the robot – does not reach the same score as the progressive network,” the paper admits.

Left: Real images of Jaco. Right: Simulated images of Jaco (Photo by DeepMind)
Although adding more progressive network columns makes transfer learning more effective, it is risky, as the “rewards will be so sparse or non-existent in the real domain that the reinforcement learning will never take off.”
It also would take approximately 53 days with constant training over 24 hours to train the robot to simulation standard, according to researchers – and that’s just teaching a single robot arm to grab an object. Due to its design, the system gets quadratically more complex and processor-intensive as you expand it, so it is far from a production-ready approach right now.
DeepMind's parent Alphabet is keen to discover new ways of making robots more intelligent. Different research wings, including Google Brain, DeepMind and the more secretive Google X, have been collaborating on robotics projects.
Judging from this research, there is still very far to go before killer robots can be built. ®
