This article is more than 1 year old
NASA's hyperwall wonderwall uses virtual flash SAN
Distributed NVMe SAN solves slow off-node access latency issues
Case study How do get fast parallel data access to 128 compute nodes doing simulation processing off a slow, although massively parallel access data set?
You could employ flash cache burst buffering, as DDN might propose, or try out an NVMe flash drive-based virtual SAN, which is what NASA Ames did in a visualisation situation.
NASA's Advanced Supercomputing (NAS) facility is located at the NASA Ames Research Centre. The High-End Computing Capability Project (HECC) is about enabling scientists and engineers to use large-scale modelling, simulation, analysis and visualisation to help ensure NASA space missions are successful.
As part of that, the project has developed a Hyperwall, a 16 column by eight row grid of vertically mounted display screens, to show an active visualisation of a simulation at large scale. An example of such a simulation is projects such as ECCO (Estimating the Circulation and Climate of the Ocean) which involves flow field pathfinding. Simulations like this involve large and high-dimensional data sets produced by NASA supercomputers and instruments.
Scientists can use different tools, viewpoints, and parameters to display the same data or datasets and rattle through visualisations to check the results.
The problem that Excelero's NVMesh sorted was how to drive the hyperwall's 128 display screens and 130 compute nodes (128 + two spares) behind them fast enough. The work is based on processing a huge data set with an enormous number of small and random IOs. A Lustre file system backed by disk drives was inadequate, as the theoretical 80GB/sec file system produced only 100s of MB/sec of throughput.

NASA Ames Hyperwall visualisation multi-screen display
A 2TB flash drive was placed in each compute node behind the hyperwall. Then programmers split the data set up into 2TB or smaller pieces and copied them to each compute node. Processing then had to take note of data locality during the compute and interactive phases of the visualisation process, which complicated the programming.
Flow field pathfinding involves two techniques:
- In-core methods are used on data that is in memory or on fast, local media such as flash
- Out-of-core techniques are applied when the data to be manipulated is not local to the compute node, meaning a longer access time
Slow simulations meant less effective scientist and engineer use of the hyperwall visualisations. That was the issue that Excelero claims its NVMesh technology fixed.
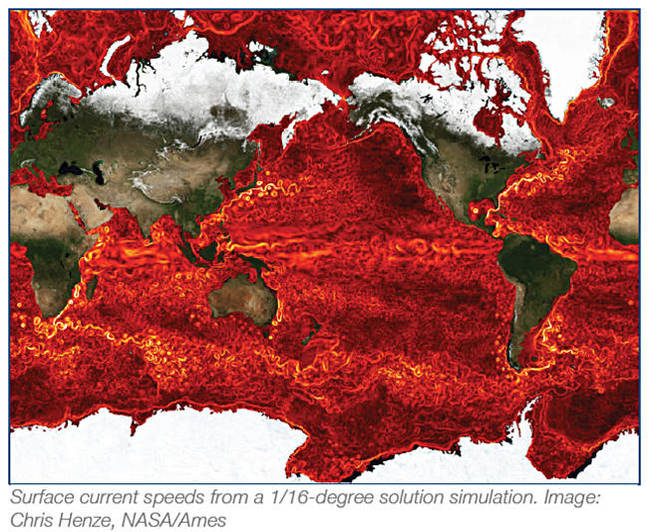
ECCO simulation display
NVMe virtual flash SAN
If all the 128 node 2TB flash drives are aggregated into a pool, a single 256TB logical device, a virtual flash SAN, accessed by RDMA, then every flash drive would effectively be local to every compute node. For the compute node apps, directly accessing network device targets and leveraging RDMA gives them parallel read access.
NASA Ames' visualisation group installed NVMesh and got the features of centrally managed block storage – logical volumes, data protection and failover – without a SAN's traditional performance limitations. Excelero says this transforms the performance, economics and the feasibility of multiple use cases in visualisation, analytics/simulation, and burst buffer use.
NVMesh has three main modules:
- The Storage Management Module is a centralised web-based GUI, RESTful API that controls system configuration,
- A Target Module is installed on any host that shares its NVMe drives, validating initial connections from clients to the drives, and then keeping out of the data path,
- A Client Block Driver runs on every host/image that needs to access NVMesh’s logical block volumes.
In converged deployments, the Client and Target Modules co-exist on the same server.
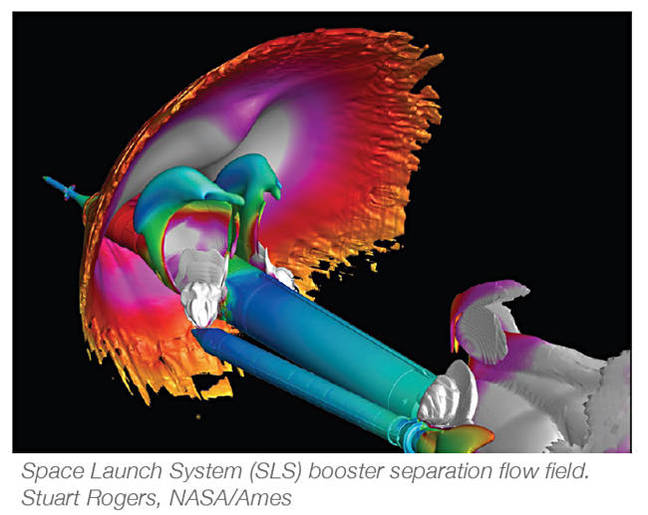
SLS visualisation
Ephemeral flash
Excelero says that, in this instance, because the simulation data is protected in the main Lustre file system, the 256TB device was treated as ephemeral, although using non-volatile media.
So it was created without data protection as a RAID-0 logical volume striped across all 128 nodes/devices. For simplicity, the device was attached to a single node, formatted with an XFS file system and populated with data. The file system was then unmounted and mounted (read-only) on all 128 compute nodes.
NVMesh logical block volumes can be used with clustered file systems and can also be protected against host or drive failures.
Latency matters
This NVMeshing added 5μsec data access latency, mostly from the network, over local NVMe drive latency.
There was no need for data locality constraints in programming; all data accesses behave as if they are local to every compute node. Preliminary results with fio (flexible IO tester) benchmarks running in all 128 nodes demonstrated over 30 million random read 4K IOPs. The average latency for those IOPs was 199μsec; the lowest value was 8μsec. Throughput has been measured at over 140 GB/sec of bandwidth at 1MB block size.
Excelero points out that, when utilising native NVMe queuing mechanisms, this method completely bypasses a target host's CPU (those with NVMe drives) preserving processing power for applications.
The simulation result is that visualisations run smoother and faster and NAS Ames scientists and engineers can interact with them more naturally, thus becoming more productive. ®
