This article is more than 1 year old
Primary Data's metadata engine 'speeds up' NAS, saves 'millions'. Leaps burning buildings, too?
DataSphere's claims – make believe or real?
Analysis Primary Data has updated its storage silo-converging DataSphere product, and says it’s ready for mainstream enterprise use, not just test and dev. The new release can save millions of dollars, handle billions of files and accelerate Isilon and NetApp filers.
The v1.2 product gives enterprise customers, Primary Data says, the ability to finally automate the flow of data to the right storage at the right time. It’s hierarchical storage management (HSM) done right with control and data planes separated, a global namespace, and the public cloud used as a back-end storage tier.
Its policy engine can, we’re told, automatically pump data to the best storage tier within its global namespace to meet performance, price and protection requirements. The software looks after blocks, files and objects.
V1.2 features include:
- Manage billions of files.
- Accelerate scale-out NAS performance for unstructured data and other file workloads with support for Dell EMC Isilon and NetApp ONTAP arrays.
- Direct interfaces for Amazon S3 and compatible cloud platforms; scale cloud uploads and downloads linearly while preserving the namespace for applications.
- Support for Linux and macOS, and SMB support for Windows Server 2008/Windows 7 and later.
- Non-disruptive H/A failover and volume retrieval for recovery without impact to ongoing I/O processing.
- Preserve application performance and optimize capacity usage by offloading cloning directly from clients to underlying storage.
- Visibility into file and client performance, with hot file visibility and real-time performance graphs across different storage resources visible on user dashboard.
- Faster performance with metadata algorithm intelligence and resource usage while continuing to maintain client I/O even while data is in flight.
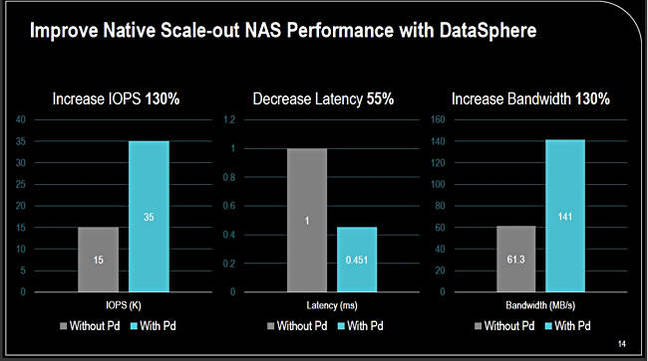
DataSphere v1.2 performance from Primary Data deck. We understand the comparative system was an Isilon filer
CEO Lance Smith says the chart refers to a rendering application, and DataSphere load-balances better than a scale-out Isilon system does, enabling higher utilization of the backend nodes. DataSphere does a better job than Isilon’s SmartConnect, according to Primary Data.
The underlying storage delivers statistics to DataSphere every 15 seconds covering IOPS, bandwidth, the most popular files, etc, so hot spots can be identified.
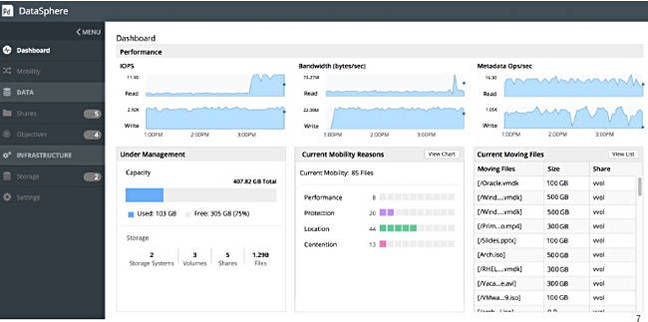
DataSphere v1.2 screen with performance charts
A key feature, as we understand it, is DataSphere’s ability, when introduced to new a enterprise and its policies set, to identify files that should not be on tier one storage and move them down-tier to more suitable locations. This ends, DataSphere, says, over-provisioning of high-speed storage. It can also identify files that should be on tier one storage and move them there so that performance SLAs can be met.
We understand that DataSphere’s enterprise customers can have 1PB of storage and that DataSphere says it can, as a rule of thumb, save a million bucks off existing storage bills per PB. Cofounder and CTO David Flynn says this is almost linear. If a customer has 2PB of existing storage then they should be looking at saving $2m.
Primary Data says DataSphere is applicable to all storage in a multi-protocol, multi-tiered, multi-vendor storage estate. This is unlike, say, Cohesity and Activio, which are focussed on secondary storage only.
By using DataSphere, we’re told, you can end storage array vendor lock-in, bypass performance bottlenecks, and avoid over-provisioning.
The software comes as the DataSphere product with the metadata engine, analytics – Primary Data says they are smart objective analytics – and quality of service. It’s sold via an annual subscription, and has high availability.
Customers can also take out an annual subscription to DSX extended data services with a client data portal, a data mover, cloud connector, and open-sourced client code. This is scale-out software with a customer’s chosen environment.
Hyperconverged infrastructure
The software handles storage in hyperconverged environments, by the way. You run DSX on the local storage and make it part of the pool.
Primary Data says VSAN and similar software settles blocks all over a hyperconverged node group. So everyone can suffer from a distracted neighbor problem.
DataSphere has understanding of what’s happening to files and can affinitize files to the local node that uses them. Flynn says, “We understand what’s being used. It’s extraordinarily compelling.” You can’t do this with alternative software approaches.
Reg comment
Using DataSphere is no point fix to a problem. It’s a decision to throw a DataSphere abstraction layer across all of your storage estate and use it to manage and monitor that estate better than you can currently. It effectively virtualizes your existing storage and buying it is a big deal.
It delivers, we understand, what HSM products have promised and failed to deliver for years, with single pane of glass management. The Primary Data pitch is that by using its software you can get better performance, cost and service delivery from your storage than you can at the moment by managing the bits individually. Your multi-protocol, multi-tier, multi-vendor storage estate is a data factory and needs to be automated and managed as such, not as an artisanal workshop with management focussed on optimizing individual pieces of the storage estate.
It obviously needs a proof of concept in your environment to check out the overall benefit claims and the relevant point claims such as accelerating NetApp and Isilon filer performance.
Over time, Primary Data says, it will extend DataSphere’s applicability into small and medium enterprises. For now it’s for larger enterprises than this, with a PB of on-premises as a rule-of-thumb start point. If you meet that then Primary Data would like a chat. And your approach might well be: "Oh yeah? Prove it." ®
