This article is more than 1 year old
Intel bolts bonus gubbins onto Skylake cores, bungs dozens into Purley Xeon chips
Inside Chipzilla's new security measures
Deep dive Intel has taken its Skylake cores, attached some extra cache and vector processing stuff, throw in various other bits and pieces, and packaged them up as Xeon CPUs codenamed Purley.
In an attempt to simplify its server chip family, Chipzilla has decided to rebrand the components as Xeon Scalable Processors, assigning each a color depending on the sort of tasks they're good for. It's like fan club membership tiers. There's Platinum for big beefy parts to handle virtualization and mission-critical stuff; Gold for general compute; and Silver and Bronze for moderate and light workloads.
These new 14nm Skylake-based Purley Xeons fall under the rebrand. And in typical Intel fashion, it's managed to complicate its simplification process by introducing a bajillion variations.
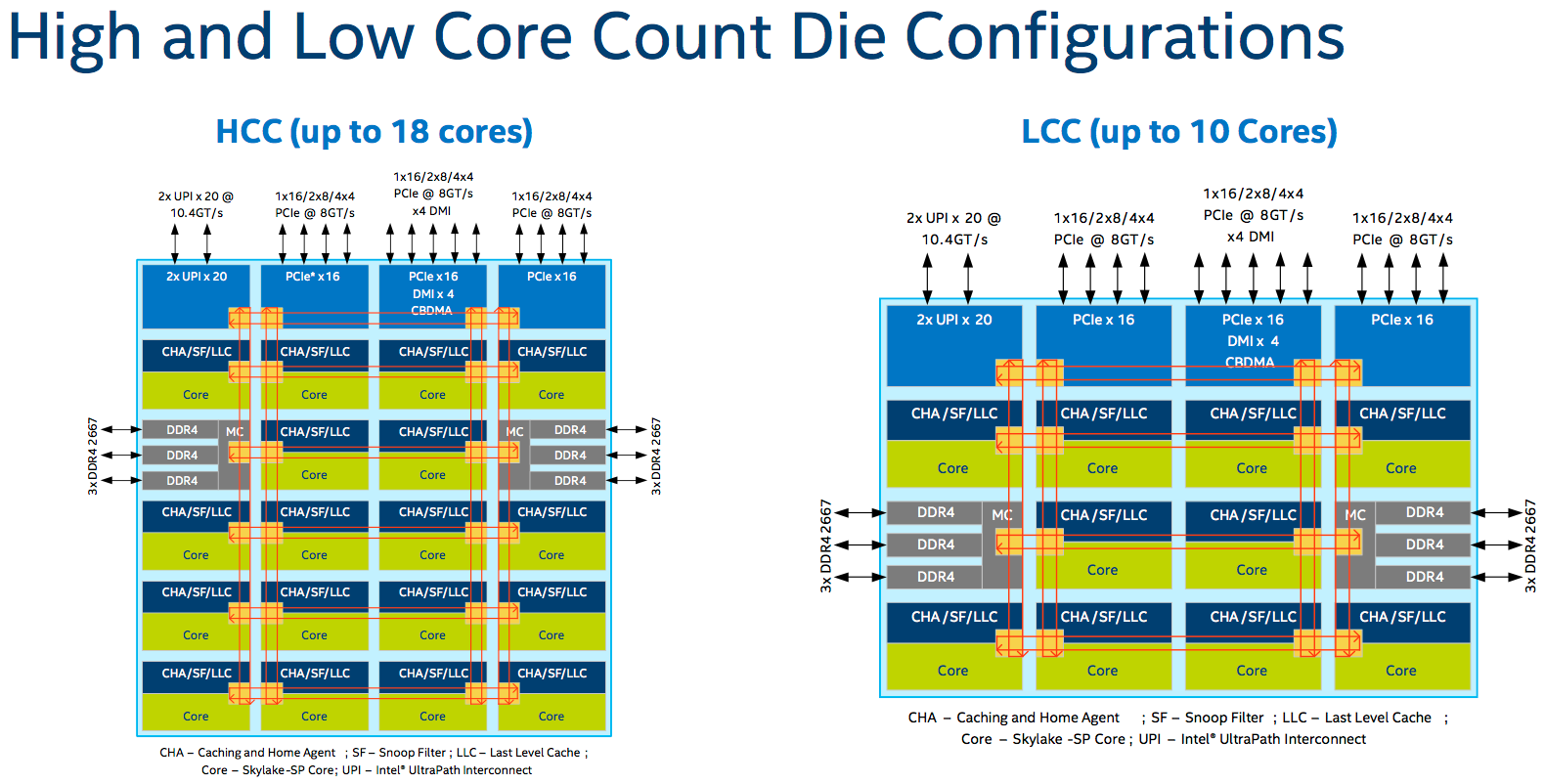
Before we get stuck in, here's a summary of the base specifications, compared to last year's Broadwell-based Xeon E5 v4 gang, plus the system architecture and socket topology. You'll notice not only is there an uptick in core count to boost overall performance, there's a mild leap in power consumption, too...
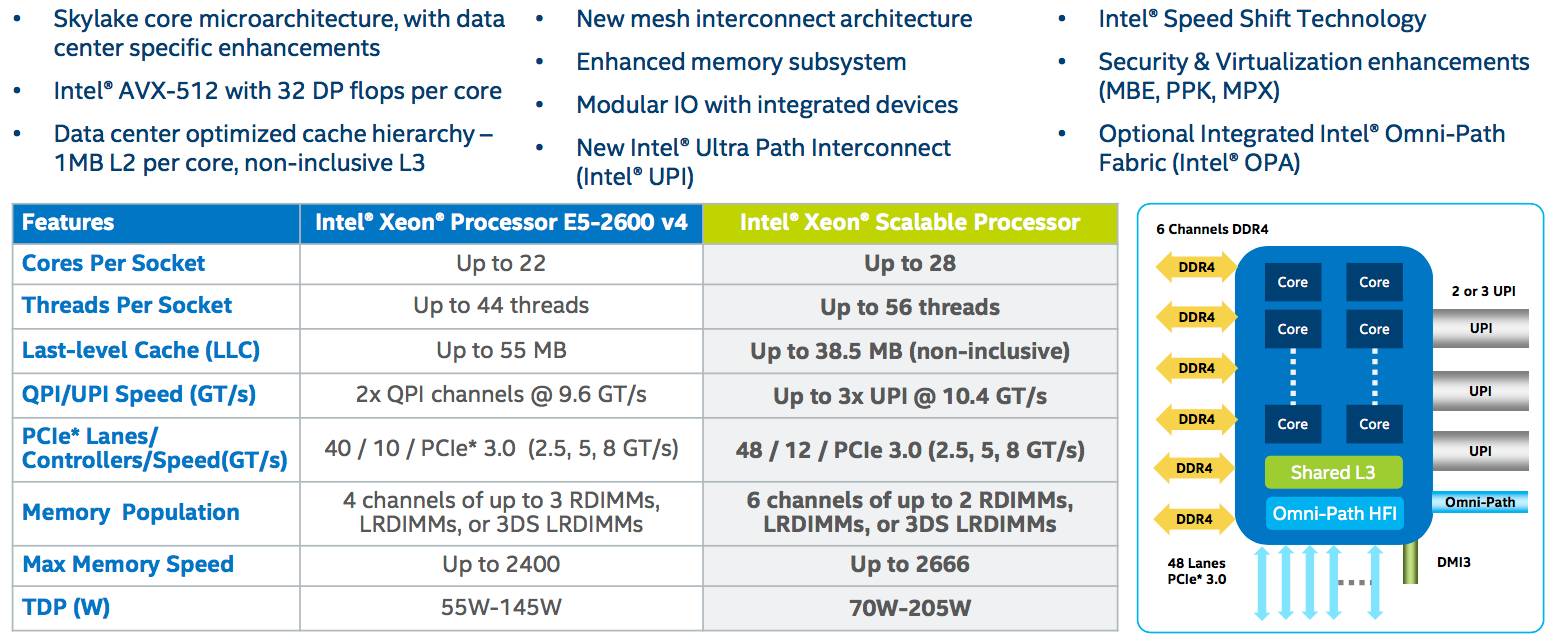

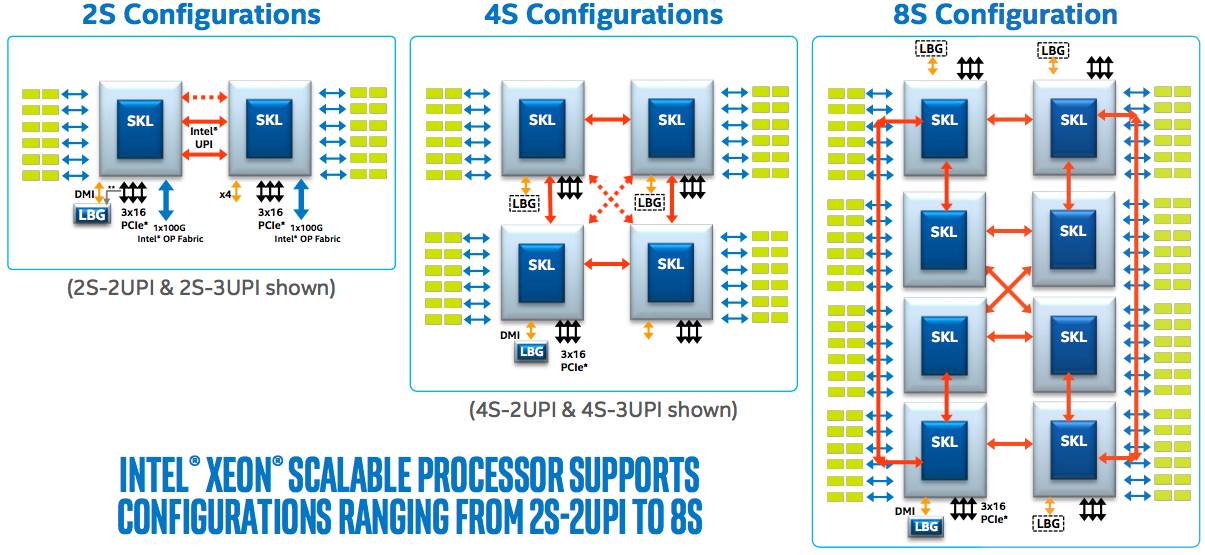
Click to enlarge any picture (Source: Intel)
And here's Intel's slide laying out the main changes between the Skylake desktop cores and the Skylake cores in the Scalable Processor packages – AVX-512 vector processing, and more L2 cache, plus some other bits, basically. The ports in the diagram below refer to ports from the out-of-order instruction scheduler that feeds instructions into the core's various processing units – see the microarchitecture diagram on the next page for a wider context.

So let's look at what you can now order, or at least enquire about, from today:
Xeon Platinum 81xx processors
Up to 28 cores and 56 hardware threads, can slot into one, two, four or eight sockets, can clock up to 3.6GHz, and each has 48 PCIe 3.0 lanes, six memory channels handling 2666MHz DDR4 and up to 1.5TB of RAM, up to 38.5MB of L3 cache, three UPI interconnects, AVX-512 vector processing with two fused multiple-and-add units (FMAs) per core. The power really depends on the part, going all the way up to about 200W.
Xeon Gold 61xx processors
Up to 22 cores and 44 hardware threads, can slot into one, two or four sockets, can clock up to 3.4GHz, and each has 48 PCIe 3.0 lanes, six memory channels handling 2666MHz DDR4 and up to 768GB of RAM, up to 30.25MB of L3 cache, three UPI interconnects, AVX-512 vector processing with two FMAs per core. The power really depends on the part, going all the way up to about 200W.
Xeon Gold 51xx processors
Up to 14 cores and 28 hardware threads, can slot into one, two or four sockets, can clock up to 3.7GHz, and each has 48 PCIe 3.0 lanes, six memory channels handling 2400MHz DDR4 and up to 768GB of RAM, up to 19.25MB of L3 cache, two UPI interconnects, AVX-512 vector processing with a single FMA per core. The power really depends on the part, going up to about 100W.
Xeon Silver 41xx processors
Up to 12 cores and 24 hardware threads, can slot into one, two or four sockets, can clock up to 2.2GHz, and each has 48 PCIe 3.0 lanes, six memory channels handling 2400MHz DDR4 and up to 768GB of RAM, up to 16.5MB of L3, two UPI interconnects, AVX-512 vector processing with a single FMA per core. The power really depends on the part, going up to about 85W.
Xeon Bronze 31xx processors
Up to eight cores and eight hardware threads, can slot into one or two sockets, can clock up to 1.7GHz, and each has 48 PCIe 3.0 lanes, six memory channels handling 2133MHz DDR4 and up to 768GB of RAM, up to 11MB of L3 cache, two UPI interconnects, AVX-512 vector processing with a single FMA per core. The power really depends on the part, going up to about 85W.
Intel has made a handy decoder chart for the part numbers. We note that the old Xeon E5 and E7 family map to the Gold 5xxx group.
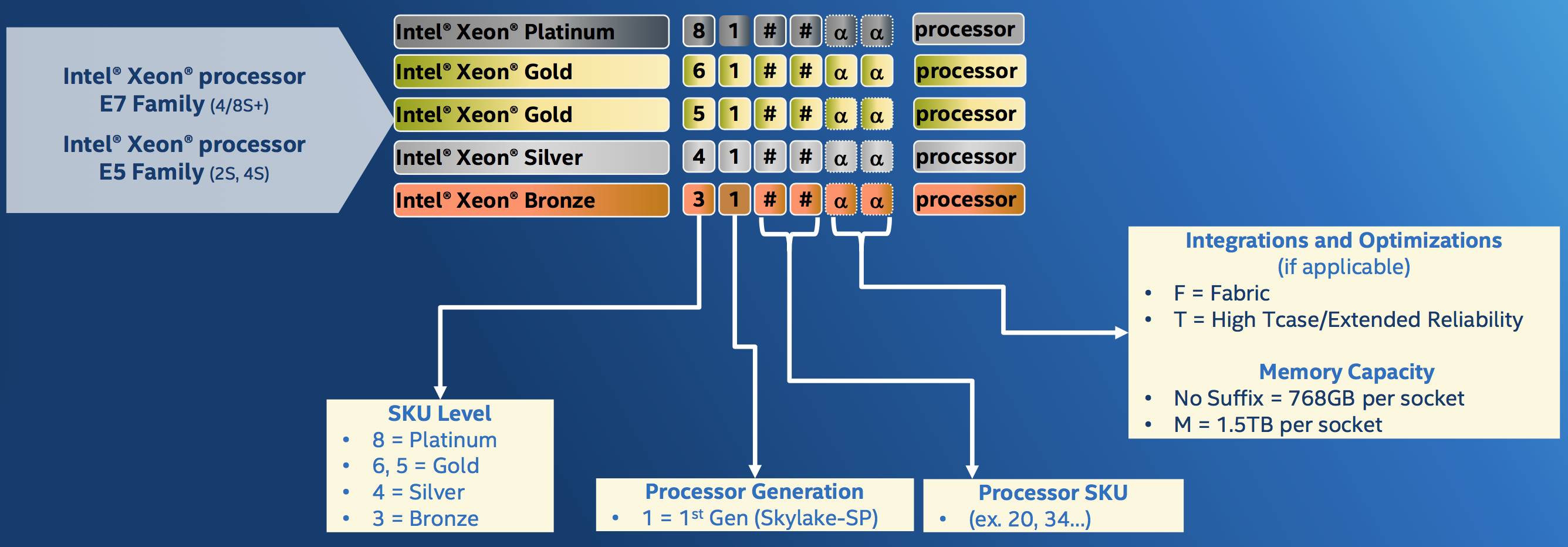
How to understand the part numbers ... Click to enlarge
So what's actually new? What makes these server-grade Skylakes as opposed to the Skylakes in desktops and workstations? The big change is Intel's new mesh design. Previously, Chipzilla arranged its Xeon cores in a ring structure, spreading the shared L3 cache across all the cores. If a core needed to access data stored in an L3 cache slice attached to another core, it would request this information over this ring interconnect.
This has been replaced with a mesh design – not unheard of in CPU design – that links up a grid of cores and their L3 slices, as seen in the Xeon Phi family. This basically needed to happen in order to support more cores in an efficient manner. The ring approach only worked well up until a point, and that point is now: if you want to add more cores and still get good bandwidth and low latency when accessing the shared L3 pool, a mesh – while more complex than a ring – is the way forward.
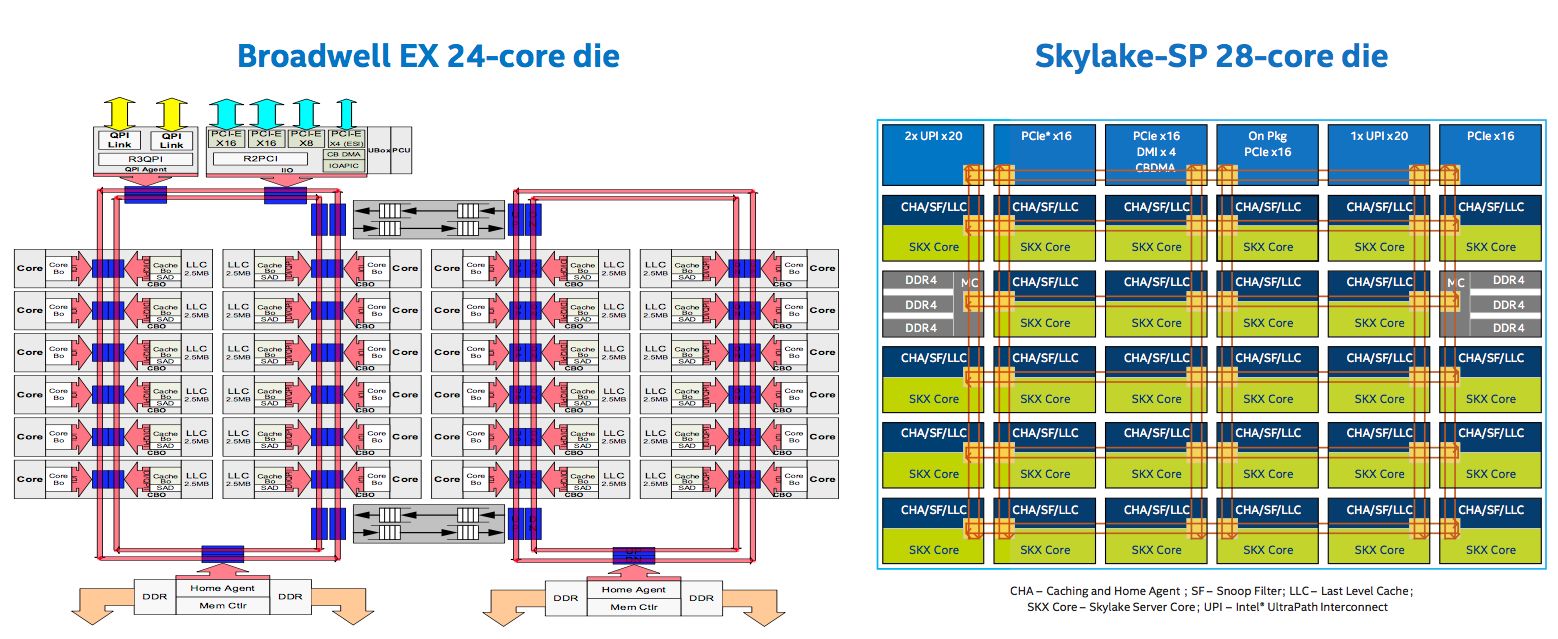
That's a fine mesh you've got me into ... The red lines represent bidirectional transfer paths and the yellow squares are switches at mesh intersections (Click to enlarge either picture)
A core accessing an adjacent core's L3 cache, horizontally or vertically, takes one interconnect clock cycle, unless it has to hop over an intersection, in which case it takes three cycles. The mesh is clocked somewhere between 1.8 and 2.4GHz depending on the part and whether or not turbo mode is engaged. So in the diagram above, a core in the bottom right corner accessing a core's L3 cache to its immediate left takes one cycle, and four cycles to the next cache on the left (one hop then three hops).
Speaking of caches, the shared L3 blob has been reduced from 2.5MB per core to 1.375MB per core, while the per-core private L2 has been increased from 256KB to a fat 1MB. That makes the L2 a primary cache with the L3 as an overflow. The L3 is also now non-inclusive from inclusive, meaning lines of data in the L2 may not exist in the L3. In other words, data fetched from RAM directly fills the core's L2 rather than the L2 and the L3.
This is supposed to be a tune-up to match patterns in data center application workloads, particularly virtualization where a larger private L2 is more useful than a fat shared L3 cache.
You can also carve up a die into sub-NUMA clusters, a system that supersedes the previous generation's cluster-on-die design. This – as well as the mesh architecture, various new power usage levels, and the new inter-socket UPI interconnect – is discussed in detail, and mostly spin free, by Intel's David Mulnix here. UPI is, for what it's worth, a coherent link between processors that replaces QPI.
There's also an interesting new feature called VMD aka Intel's volume management device: this consolidates PCIe-connected SSDs into virtual storage domains. To the operating system, you just have one or more chunks of flash whereas underneath there are various directly connected NVMe devices. This technology can be used to replace third-party RAID cards, and it is configured at the BIOS level. The Purley family also boasts improvements to the previous generation's memory reliability features for catching bit errors.
While these new Xeons share many features present in desktop Skylake cores, there's another new thing called mode-based execution (MBE) control. This is supposed to stop malicious changes to a guest kernel during virtualization. It repurposes the execution enable bit in extended page table entries to allow either execution in user mode or execution in supervisor (aka kernel) mode. By ensuring executable kernel pages cannot be writeable, a hypervisor can prevent guest kernels from being tampered with and hijacked by miscreants exploiting security bugs. This is detailed in section 3.1.1 in this Intel datasheet.
