This article is more than 1 year old
AI bot rips off human eyes, easily cracks web CAPTCHA codes. Ouch
I'm not a robot, muhaha, hahah
Computer software that mimics how the human visual cortex works can solve text-based CAPTCHA challenges, the image recognition tasks often used by websites to differentiate human visitors from spam bots.
A paper describing the code was published on Thursday in the journal Science. A team from Vicarious – a California startup interested in developing artificial general intelligence for robots – developed the system, and called it a recursive cortical network (RCN). It can, we're told, convert CAPTCHAs that are randomized letters of text into a correct input with a decent level of accuracy.
CAPTCHA stands for Completely Automated Public Turing test to tell Computers and Humans Apart, and dates back 20 years to 1997. Distorted images of letters and numbers are confusing for machines to grok, but easy for humans to read. A website visitor typically has to type in the characters shown in a randomly generated CAPTCHA to prove they are a person before they can be allowed to sign up for an account or send a message, and so on.

Examples of text-based CAPTCHA codes ... Image credit: D. George et al.
A CAPTCHA implementation is considered broken if it can be automatically and successfully solved at a rate above one per cent, ie: one in one hundred can be solved by software. The RCN can recognize text-based codes from Google’s reCAPTCHA, BotDetect's CAPTCHA generator, and Yahoo and PayPal's robot challenges with more than 50 per cent accuracy.
The software's model takes inspiration from assumptions based on how neurologists think the visual cortex works in mammalian brains, we're told.

Meet the man building an AI that mimics our neocortex – and could kill off neural networks
READ MOREDileep George, a researcher and cofounder of Vicarious, told The Register there is evidence the visual cortex is a hierarchical system. There is one set of neurons in the system detecting object edges, and another for inspecting the surface and texture. Both work together to build up the brain's internal understanding of individual objects so they can be recognized.
The RCN works in similar manner. There are subnetworks made up of nodes that collect “child features” that identify the edges of characters; these are basic representations of particular letters. On top of that is another layer of nodes grouped together to identify “parent features,” where the information from the “child features” is used to build a higher representation and the overall shape of each letter.
Another subnetwork is used to recognize the different styles of fonts used in the CAPTCHA challenges. The system is trained on all 26 letters of the modern English alphabet in various typefaces.
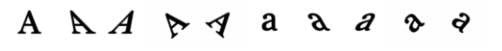
An example of training data for the letter a. Image credit: D.George et al.
As more examples of characters are given to the RCN to learn, it builds up a "dictionary" of different styles of As, Bs, Cs, and so on. When faced with previously unseen CAPTCHA letters, it uses its memory bank of knowledge to trace the features common to each letter in the alphabet, identify the characters, and solve the challenge automatically.
A good dictionary is versatile and includes variations, such as rotations and upper and lower case letters.
Shock, horror! It's not deep learning
Unlike the bulk of today's AI research, the RCN is a probabilistic generative model, and not a trendy deep-learning neural network.
A rival convolutional neural network (CNN) trained by Google on 2.3 million CAPTCHA images achieved an accuracy rate of 89.9 per cent with reCAPTCHA – much higher than Vicarious’ results for reCAPTCHA at 66.6 per cent, BotDetect at 64.4 per cent, Yahoo at 57.4 per cent and PayPal at 57.1 per cent.
Neural networks in image-recognition systems, such as the aforementioned CNN, are essentially expert pattern matchers. Feed them enough training data and they’ll be able to recognize the same structures they’ve seen before. However, if the image is slightly off, for example if the CAPTCHA challenges have more or fewer letters than the ones in the training data, or the spacing between the characters is changed, the accuracy drops significantly.
For example, just 15 per cent more spacing reduced the CNN's accuracy to 38.4 per cent, and 25 per cent more spacing whittled it down even further to just seven per cent.
Although the RCN has a lower accuracy, it’s much more robust to changes in the CAPTCHA design because it’s better at recognizing the letters of the alphabet rather than the whole image. Thus, it can cope with minor changes, such as spacing between characters, better.
“It models the shape of an object rather than just its appearance,” George explained. “For example, if there was an outline of a banana filled in with strawberries, it would be very confusing for a neural network. Is it a banana? Is it a strawberry? But for probabilistic generative models, the contours of an image are more important. So it would know that the image was a banana because of its shape regardless if the pattern was made of strawberries or not.”
The RCN also required a fraction of the training data compared to the CNN model: only 500 images were used to train reCAPTCHA, and roughly 5,000 images from three of the four CAPTCHA implementations were used to test it. BotDetect was a little trickier: 50 to 100 images were used for training on each font style, and only 100 were used for testing.
A big disadvantage to using the RCN approach is that a network has to be tailored to each training set, unlike one overarching model for the CNN. So the RCN for reCAPTCHA is slightly different to the one used for Yahoo, PayPal and BotDetect.
The Letter Spirit
CAPTCHA problems encapsulate a lot of visual perception difficulties that artificial general intelligence systems will have to overcome, Vicarious explained in a blog post today. "Computers have to deal with missing and uncertain information, clutter and noise."
Douglas Hofstadter, a professor of cognitive science interested in machine consciousness and creativity, declared in the textbook Metamagical Themas: Questing for the Essence of Mind and Pattern that “for any program to handle letterforms with the flexibility that human beings do, it would have to possess full-scale artificial intelligence.” Hofstadter set up the The Letter Spirit project with the goal to “model how the 26 lowercase letters of the Roman alphabet can be rendered in many different but internally coherent styles.”
The problem is far from solved, however. Just because software can identify some designs of the letter A, for instance, doesn't mean it can general understand the letter A and identify it in other typefaces. “We can’t even get any machine to recognize all the forms of just the letter A yet,” George admitted. ®
